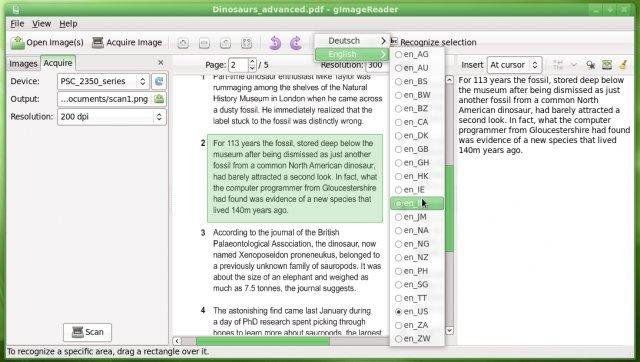
gImageReader is a simple Gtk/Qt front-end to tesseract. Features include:
- Import PDF documents and images from disk, scanning devices, clipboard and screenshots
- Process multiple images and documents in one go
- Manual or automatic recognition area definition
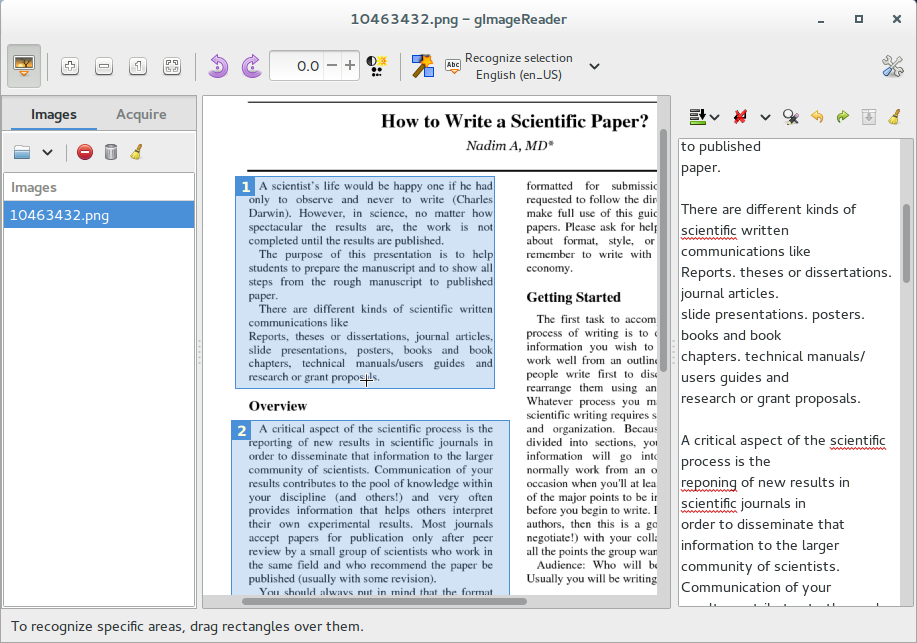
- Recognize to plain text or to hOCR documents
- Recognized text displayed directly next to the image
- Post-process the recognized text, including spellchecking
- Generate PDF documents from hOCR documents
**Note**: This page is only a mirror for the downloads. Development is happening on github at https://github.com/manisandro/gImageReader, release binaries are also posted there.
Features
- Import PDF documents and images from disk, scanning devices, clipboard and screenshots
- Process multiple images and documents in one go
- Manual or automatic recognition area definition
- Recognize to plain text or to hOCR documents
- Recognized text displayed directly next to the image
- Post-process the recognized text, including spellchecking
- Generate PDF documents from hOCR documents
Project Samples




License
GNU General Public License version 3.0 (GPLv3)Follow gImageReader
Other Useful Business Software
MongoDB Atlas runs apps anywhere
MongoDB Atlas gives you the freedom to build and run modern applications anywhere—across AWS, Azure, and Google Cloud. With global availability in over 115 regions, Atlas lets you deploy close to your users, meet compliance needs, and scale with confidence across any geography.
Rate This Project
Login To Rate This Project
User Reviews
-
Stable and a nice touch is the OCR editing facility to enable manual correction of automated OCR errors. The program would be further enhanced by enabling output of the input PDF image file also as a PDF image file but with the OCR as searchable text layer under the page image; this instead of / as an additional option to the existng PDF output of OCR-only text without image.
-
This program works wonderfully! The interface is fairly self-explanatory and it effortlessly and nearly faultlessly translated a 117 page PDF image scan of an out of print book I wanted to get on my Kindle. The only reason I give it four out of five stars is the fact that Norton caught the presence of a virus in the "uninstall" utility of the program. Norton labeled it "Trojan.ADH.X". Not sure why that was put there, and it doesn't inspire much confidence, but Norton caught it -- so please be up to date on your virus protection when you install this download. Other than that it worked perfectly and, as they say, the price was right.
-
Fast, simple, great. But one important missing thing is the lack of option to save OCR on pdfs...
