Gothic Norwegian "vertical reversed tilde combining" diacrit
Brought to you by:
psb1558
In the so-called "Gothic Norwegian" used in a great many of the records digitized by the Norwegian national Digital Archive (http://digitalarkivet.no), the 'u' is distinguished from other characters or character combinations (e.g. 'n' or 'e' or 'cc') that would otherwise greatly resemble it by the use of a "vertical reversed tilde combining diacritical." Examples can be seen in the University of Bergen tutorial linked from that site, http://www.hist.uib.no/gotisk/ (use the "Alfabet" link at the top of the page to open the viewer, or you can go straight to the characters in question at http://www.hist.uib.no/gotisk/alfabet/u.jpg for the lower-case 'u' and to a lesser degree http://www.hist.uib.no/gotisk/alfabet/su.jpg for the upper-case 'U'). As far as I know this is the only use of a vertical reversed tilde ("reversed vertical tilde"?) combining diacritical in any language, so perhaps it would be equally efficient to have a precomposed "Gothic Norwegian u" and "Gothic Norwegian U" rather than lower- and upper-case variants of the "vertical reversed tilde combining" diacritical. I'm trying to translate and edit an extensive tutorial on reading those records, and it sure would be helpful to have standard and italic versions of at least the lower case version! I don't know that it interests a sufficient number of people to make it worth prosecuting a request through official Unicode channels to have it added to the "Combining Diacritical Marks Supplement," but it would be really appreciated if you could add them to JuniCode's "Private Use Area."
Thank you for your work on this extraordinary project, and for your openness to feature requests!
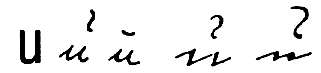{kind=link}
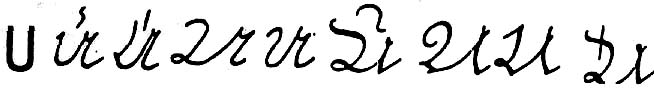{kind=link}
lower-case Gothic Norwegian 'u' - 4 examples
I like to go through MUFI for this kind of addition to the font, so I've submitted a proposal there, and we'll see what the medieval font gang has to say.
Referred to MUFI. Will add if MUFI assigns it to an encoding slot.