ChatGPT and various large language models (LLMs) boast incredible versatility, enabling the development of a wide range of applications. However, as your application grows in popularity and encounters higher traffic levels, the expenses related to LLM API calls can become substantial. Additionally, LLM services might exhibit slow response times, especially when dealing with a significant number of requests. To tackle this challenge, we have created GPTCache, a project dedicated to building a semantic cache for storing LLM responses. This project is undergoing swift development, and as such, the API may be subject to change at any time.
Features
- GPTCache has been fully integrated with LangChain
- A Library for Creating Semantic Cache for LLM Queries
- You can quickly try GPTCache and put it into a production environment without heavy development
- By default, only a limited number of libraries are installed to support the basic cache functionalities
- Make sure that the Python version is 3.8.1 or higher
- Examples included
Project Samples
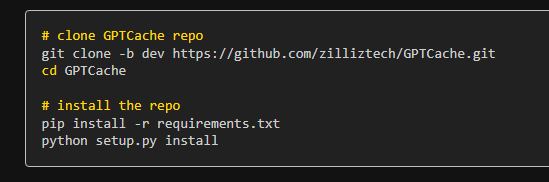
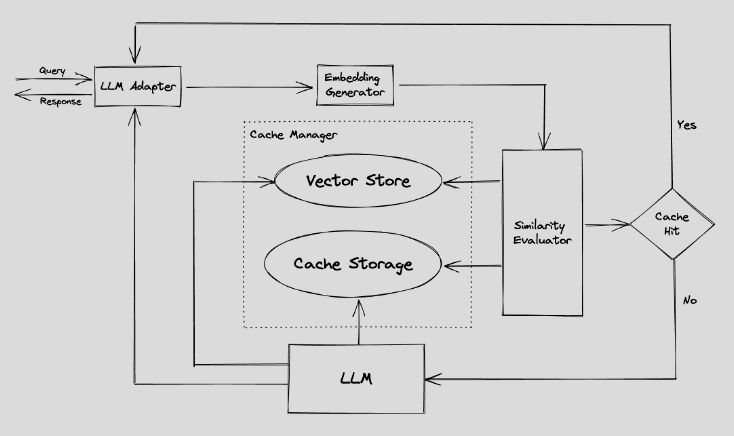
Categories
Artificial IntelligenceLicense
MIT LicenseFollow GPTCache
Other Useful Business Software
Build Agents and Models on One Platform
Gemini Enterprise Agent Platform is Google Cloud's comprehensive platform for developers to build, scale, govern, and optimize agents and models. Choose from Google's most advanced models and third-party models like Anthropic's Claude Model Family.
Rate This Project
Login To Rate This Project
User Reviews
Be the first to post a review of GPTCache!