indic-computing-devel Mailing List for The Indic-Computing Project (Page 10)
Status: Alpha
Brought to you by:
jkoshy
You can subscribe to this list here.
| 2001 |
Jan
|
Feb
|
Mar
|
Apr
|
May
|
Jun
|
Jul
|
Aug
|
Sep
|
Oct
|
Nov
|
Dec
(14) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2002 |
Jan
(25) |
Feb
(90) |
Mar
(41) |
Apr
(16) |
May
(8) |
Jun
|
Jul
(37) |
Aug
(35) |
Sep
(62) |
Oct
(37) |
Nov
(22) |
Dec
(7) |
| 2003 |
Jan
(16) |
Feb
(19) |
Mar
(10) |
Apr
(5) |
May
(26) |
Jun
(11) |
Jul
(35) |
Aug
(4) |
Sep
(14) |
Oct
(5) |
Nov
(5) |
Dec
(10) |
| 2004 |
Jan
(25) |
Feb
(2) |
Mar
|
Apr
(1) |
May
|
Jun
|
Jul
(10) |
Aug
(2) |
Sep
(2) |
Oct
(1) |
Nov
(9) |
Dec
|
| 2005 |
Jan
|
Feb
|
Mar
|
Apr
|
May
|
Jun
|
Jul
(2) |
Aug
|
Sep
|
Oct
(1) |
Nov
(1) |
Dec
(1) |
| 2006 |
Jan
|
Feb
|
Mar
(1) |
Apr
|
May
|
Jun
|
Jul
|
Aug
|
Sep
|
Oct
|
Nov
(1) |
Dec
|
| 2017 |
Jan
|
Feb
|
Mar
|
Apr
|
May
|
Jun
|
Jul
|
Aug
|
Sep
|
Oct
|
Nov
(4) |
Dec
|
|
From: <al...@ya...> - 2002-12-17 03:26:02
|
Hi, I want to mirror http://indic-computing.sourceforge.net onto my company's intranet. So, a few questions: a. Is it technically possible to do a mirror like this? b. Is it permissible to mirror the site (as-is) onto my company's intranet(I'm asking about permissions from the project's copyright viewpoint, not from the company policy viewpoint)? c. Would it be possible to automate updates to the mirror? Since I don't know anything about mirroring, any pointers would be a good help. The idea just came in my mind so I haven't even googled on it yet. The company in question is Infosys Technologies Limited, mirroring the site would provide some 16000 people access to the site. That's a lot of potential developers. Most employees don't have restricted internet access on their desktops. tia, Alok ________________________________________________________________________ Missed your favourite TV serial last night? Try the new, Yahoo! TV. visit http://in.tv.yahoo.com |
|
From: Guntupalli K. <kar...@fr...> - 2002-12-16 08:13:56
|
Hi All, TDIL has put up its July 2002 newsletter, containing info on Bengali, Oriya & Assamese. http://tdil.mit.gov.in/tdil-july-2002.pdf Also a small writeup on Inscript Keyboard layout http://tdil.mit.gov.in/keyoverlay.htm More on ISCII & inscript in http://tdil.mit.gov.in/isciichart.pdf Regards, Karunakar -- Hating people is like burning down your house to get rid of a rat - Anon --------------------------------------------------- * Indian Linux project, www.indlinux.org * * Indic-Computing project, indic-computing.sf.net * --------------------------------------------------- |
|
From: Sayamindu D. <unm...@So...> - 2002-12-09 17:35:15
|
As promised in the last week, Akaash version 0.75 has been released. Get the tarball from http://savannah.nongnu.org/download/freebangfont/Akaash.pkg/0.75/Akaash-0.75.tar.gz Changes since version 0.50: 1. Latin glyphs changed, and looks much better now. 2. Major changes in the OT tables, the conjuncts have been cleaned up and are more organized now. 3. Akaash now covers all the Bengali code points as defined in Unicode specification. 4. Added a number of new glyphs, and it has around 650 glyphs now. ...Enjoy -cheers- Sayamindu -- Sayamindu Dasgupta [ http://www.peacefulaction.org/sayamindu/ ] * GNU is Not Unix * .... Towards World Liberation .... http://www.gnu.org There are two ways to write error-free programs; only the third one works. |
|
From: Thuraiappah V. <t_...@ya...> - 2002-12-01 15:13:50
|
Hello, I've added OpenType tables to the GPL'ed Tamil Fonts. from Akruti Ltd. They are available from http://groups.yahoo.com/group/tamilinix/files/unicode/fonts/ Many thanks to Akruti.com for releasing them under the GPL. The fonts have been tested with Pango (Redhat 8.0) and Windows XP. Please let me know if you encounter any bugs with the OpenType features. -Vasee __________________________________________________ Do you Yahoo!? Yahoo! Mail Plus - Powerful. Affordable. Sign up now. http://mailplus.yahoo.com |
|
From: Arun S. <ar...@sh...> - 2002-11-29 05:12:49
|
On Thu, Nov 28, 2002 at 07:58:30PM +0530, Guntupalli Karunakar wrote: > Hi, > As of now Kannada locale is not present in glibc (nor in any other > locales project - ICU etc) Hope that'll change soon. > Look for comments of type % *** . Strings are basically to be > written as unicode code points . eg for Sunday in Kannada , write it > down in Kannada on paper & then write the unicode codes for each > character involved in sequence. I found an easier way. I type in the text in a WYSIWIG manner in a UTF-8 environment (my setup is windows) to produce something like: http://www.sharma-home.net/~adsharma/projects/kn_IN/kn_IN.src.txt and then run it through: http://www.sharma-home.net/~adsharma/projects/kn_IN/localify.py to get: http://www.sharma-home.net/~adsharma/projects/kn_IN/kn_IN.utf8 I've verified the days/month part to be working: http://www.sharma-home.net/~adsharma/projects/kn_IN/kn_IN.date.txt http://www.sharma-home.net/~adsharma/projects/kn_IN/kn_IN.cal.txt using: http://www.sharma-home.net/~adsharma/projects/kn_IN/locale.sh However, I haven't been able to test the currency part. strfmon doesn't seem to work as advertized on Mandrake 8.2. Has anyone tried something newer ? -Arun |
|
From: Sayamindu D. <unm...@So...> - 2002-11-26 15:09:56
|
-----Forwarded Message----- From: Taneem Ahmed <ta...@ey...> To: us...@be... Cc: bd...@ya..., co...@be... Subject: [Bengalinux-core] bspeller-0.1 release Date: 26 Nov 2002 08:31:03 -0500 Hi, I would like to let everyone know that the first beta version of bspeller has been released. You can download the source files from the following URL: http://sourceforge.net/project/showfiles.php?group_id=43331 Bspeller is a small text editor that works as a Bangla (Bengali) spell checker. It is also capable of printing using OpenType fonts, which is very useful for Inidic languages (or any other complex language) like Bangla (Bengali). *Ironically* the first release does not do any spell checking, however, it is being released because of the printing feature. Any comment, suggestions, or bug report is always welcomed. Taneem Since light travels faster than sound, people appear bright until you hear them speak. ------------------------------------------------------- This SF.net email is sponsored by: Get the new Palm Tungsten T handheld. Power & Color in a compact size! http://ads.sourceforge.net/cgi-bin/redirect.pl?palm0002en _______________________________________________ Bengalinux-core mailing list Ben...@li... https://lists.sourceforge.net/lists/listinfo/bengalinux-core -- Sayamindu Dasgupta [ http://www.peacefulaction.org/sayamindu/ ] * GNU is Not Unix * .... Towards World Liberation .... http://www.gnu.org fortune: cannot execute. Out of cookies. |
|
From: Keyur S. <key...@ya...> - 2002-11-25 10:33:56
|
--- Baiju M <ba...@fr...> wrote: > Can anyone send me the source of indic-computing-tool available at > http://rohini.ncst.ernet.in/indix/download/print/indic-printing-tools-0.99-1.i386.rpm > > I think its under GPL (RPM info shows), but source is not distributed > with that binary. Yes, it is under GPL. I really forgot to put source RPM. Thanks for reminding. I'll put it up in couple of days. There are many versions. Unfortunately, I didn't use CVS for printing tool development. I'll have to verify correct version. Give me that much time :) Thanks, Keyur __________________________________________________ Do you Yahoo!? Yahoo! Mail Plus Powerful. Affordable. Sign up now. http://mailplus.yahoo.com |
|
From: Dr. U.B. P. <pav...@vi...> - 2002-11-25 04:50:39
|
Hi all, There is a new font technology for the web. It is called Photofont. The url is www.photofont.com. This is by the people who make FontLab. This was in the pipeline for quite some time and now the specs are there. I had met Mr. Ted Harrison, President of FontLab Inc. lats Aug. He had mentioned to me about this new initiative at that time. When I checked the site and went through the specs I realised that they don't support all the features of Opentype fonts, expecially the GSUB and GPOS tables. Without this support we can not use it for Indic scripts. The technology of Photofont is somewhat similar to dynamic fonts. Each glyph is converted from bitmap to plain text and then stored in the web server. The web browser need to get a free plug-in from Photofont to display the font. There is no need to have the font installed in the local system. The process of installing the plug-in has to be done only once (this was the case with the ActiveX plug- in for IE browser for PFR fonts, which is defunct now). I had sent mails to Ted Harrison about OTF support in Photofont and the answer was in the negative. They are not planning to support OTF. But he says that the specifications are open and we are welcome to add the support ourselves. I have attached my mails to Ted and his replies at the end of this mail. Please take a look at photofont.com, study the specs and think about extedning the support to OTF. Any volunteers? Thanks and regards, Pavanaja ----------- Begin mail 1 fro Ted -------- Dear Dr. Pavanaja, > I am bit surprised to > know that it does not support the Opentype tables like GSub, > GPos, etc. Without these support we can not use this technology > for Indic scripts. What are your plans about supporting Opentype > tables? Well, I'm sure you noticed that photofonts are not OpenType fonts. They are a new bitmap font format. Therefore it is highly likely that they will never support OT tables. Regards, Ted Harrison FontLab Ltd. --------------- End mail 1 ---------------------- ---------------- Begin mail 2 from Ted -------------- Dear Dr. Pavanaja,, > In that case, how are you planning to support complex scripts > (Indic scripts, Arabic, etc)? > We are not. However, it is an open specification so anyone who wants to add that capability is welcome to come up with a mechanism. Regards, Ted Harrison FontLab Ltd. ------------------ End mail 2 from Ted ------------------------------- ----------------------------------------------------- Dr. U.B. Pavanaja Editor, Vishva Kannada World's first Internet magazine in Kannada http://www.vishvakannada.com/ Note: I don't worry about pselling mixtakes |
|
From: Baiju M <ba...@fr...> - 2002-11-23 09:20:02
|
Can anyone send me the source of indic-computing-tool available at http://rohini.ncst.ernet.in/indix/download/print/indic-printing-tools-0.99-1.i386.rpm I think its under GPL (RPM info shows), but source is not distributed with that binary. Regards, Baiju M |
|
From: Guntupalli K. <kar...@fr...> - 2002-11-23 07:34:53
|
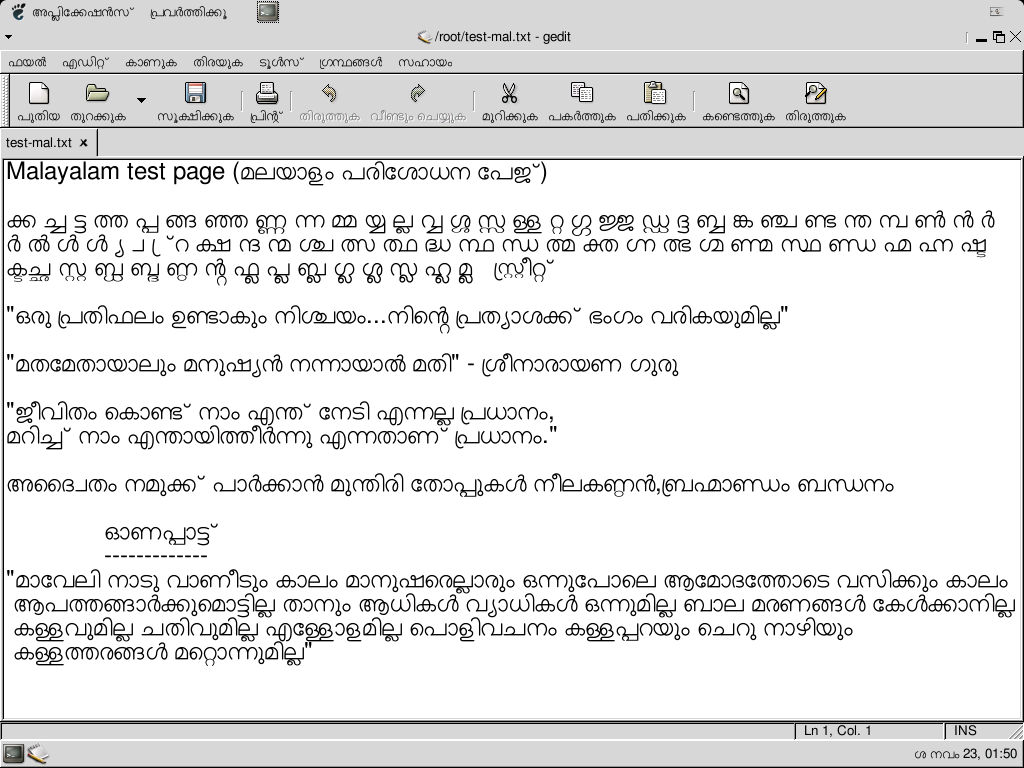
On Sat, 23 Nov 2002 11:21:31 +0400 (SCT) "Baiju M" <ba...@fr...> wrote: > Rendering is not working in printing. Here is two screenshots : > > http://baijum81.tripod.com/smc/print-01.png (Gedit) > http://baijum81.tripod.com/smc/print-02.png (Print preview) > links not working, but yes printing doesnt work for Indic , you get all blanks for indic characters. There was one paps - pango printing/postscript system - which uses ft2 backend to render & convert to postscript. there is indix-printing-tools at http://rohini.ncst.ernet.in/indix/download/print/ takes a utf-8 file & generates postscript. It uses raghu font by default or you can set it to use some other font. -- Hating people is like burning down your house to get rid of a rat - Anon ------------------------------------ * Linux Bangalore/2002 * * Technology for a Free World * * December 3/4/5, 2002 * * http://linux-bangalore.org/2002 * ------------------------------------ |
|
From: Baiju M <ba...@fr...> - 2002-11-23 07:21:40
|
Rendering is not working in printing. Here is two screenshots : http://baijum81.tripod.com/smc/print-01.png (Gedit) http://baijum81.tripod.com/smc/print-02.png (Print preview) The language is Malayalam, I tested Hindi and Tamil aslo. The rendering is working by using OpenType fonts. With thanks and Regards, Baiju M |
|
From: <a_j...@ya...> - 2002-11-21 04:10:29
|
> How are images esp, something like glyphs, text > strings to be > embedded in handbook? At the moment using <inlinemediaobject>. This works, ok for HTML output but poorly for PDF. The needs for print and online display are different enough that getting good quality output on both using embedded images is difficult. > Any mechanisms to generate them on the fly & have > them embedded when > building a pdf/ps/html ? There is a planned mechanism which is not operational yet. The idea is to extend DocBook with a tag ``<indicphrase>''. The contents of an indicphrase element would be data representing some indian language text in some arbitrary encoding scheme. A encoding scheme is specified using an attribute. The transformation process from DocBook to the output format [PDF, HTML, whatever], would convert <indicphrase> elements to the appropriate GIF images for HTML, or to embedded font sequences for PDF or PS. I'm not sure if this is enough. This is what I'm trying at the moment. Suggestions are welcome. There is more about how the documentation is built on the website (look for an article named "Documentation Build Infrastructure"). ===== Joseph Koshy Tel: (080)-2251554 x1802 [Office (HPISO)] The FreeBSD Project http://people.freebsd.org/~jkoshy/ Indic Computing http://indic-computing.sourceforge.net/ ________________________________________________________________________ Missed your favourite TV serial last night? Try the new, Yahoo! TV. visit http://in.tv.yahoo.com |
|
From: Tapan S. P. <ta...@ya...> - 2002-11-19 14:01:30
|
Well if you can import the document into OpenOffice and can see all your text properly, than you can print to PDF and all of the glyphs will be embedded and you need not worry about having fonts installed on the client side. i think that should work. -- tapan On Tue, 19 Nov 2002 19:21:29 +0530 Guntupalli Karunakar <kar...@fr...> wrote: > Hi, > How are images esp, something like glyphs, text strings to be > embedded in handbook? > Any mechanisms to generate them on the fly & have them embedded when > building a pdf/ps/html ? > > Regards, > Karunakar > > -- > Hating people is like burning down your house to get rid of a rat - > Anon > > ------------------------------------ > * Linux Bangalore/2002 * > * Technology for a Free World * > * December 3/4/5, 2002 * > * http://linux-bangalore.org/2002 * > ------------------------------------ > > > ------------------------------------------------------- > This sf.net email is sponsored by: To learn the basics of securing > your web site with SSL, click here to get a FREE TRIAL of a Thawte > Server Certificate: http://www.gothawte.com/rd524.html > _______________________________________________ > Indic-computing-devel mailing list > http://indic-computing.sourceforge.net/ > Ind...@li... > https://lists.sourceforge.net/lists/listinfo/indic-computing-devel > [Other Indic-Computing mailing lists available: -users, -standards, > -announce] |
|
From: Guntupalli K. <kar...@fr...> - 2002-11-19 13:34:57
|
Hi, How are images esp, something like glyphs, text strings to be embedded in handbook? Any mechanisms to generate them on the fly & have them embedded when building a pdf/ps/html ? Regards, Karunakar -- Hating people is like burning down your house to get rid of a rat - Anon ------------------------------------ * Linux Bangalore/2002 * * Technology for a Free World * * December 3/4/5, 2002 * * http://linux-bangalore.org/2002 * ------------------------------------ |
|
From: <ar...@bg...> - 2002-11-17 13:59:07
|
Dear Colleagues, I presume that Mr. harsha you are replying to mails on behalf of the people (I have got it confirmed over phone from one of my friend in that group) whom I have quoted my mail. Hence my reply to this mail is not addressed to Mr. harsha personally but I am addressing it to the same group whom I quoted in my earlier mail. Anbarasan : It is this annoying trick which is being followed by the 'Specific Group' for Kannada in standardising and developing NUDI for Kannada while blaming the developers. Why this 'Specific Group' never attempted to invent a technology to handle Kannada efficiently using ISCII on computers for the off-the-shelf applications. I leave it to your guess and further pacifying. KGP : Why you people never attempted to invent a technology to handle Tamil efficiently using ISCII ? and why are you people using TSCII ? Anbarasan : "You people" - who is this? It is me or Tamil community. By trying to link my identity with Tamil you are proving how immoral you people are. Instead of asking me this question that why Tamils have not attempted to invent technology to handle Tamil efficiently using ISCII? you should have bothered about Kannada since I have served Kannada Language from 1989. You are trying to hide this thirteen years of my service to Kannada Language and trying to isolate me in Kannada development on the digital media. I am dedicating myself in developing technology for all Indian Languages. I am not particular about any one language. Coming to my technology development in handling ISCII on computers. It is the SURABHI, the first "software only" technological solution (there were only two efforts on this direction one is at APPLESOFT the other was at CIIL Mysore, later on CDAC has announced their GIST Shell) developed to support ISCII on all text based application software on MS DOS. Thereby SURABHI supported MS DOS, Norton Editor, WordStar, Dbase, Lotus 1-2-3. This product was demonstrated at the exhibition organised at Vidhana soudha, Bangalore for the inauguration of Kannada Jagruthi varsha celebrations. The demonstration of SURABHI software was broadcast on the Bangalore Doordharshan on the computerisation efforts of Karnataka Government. Every indic computing developer pretty well aware that the problem involved in implementing ISCII in MS Windows platforms to make use of ISCII in all the off the shelf application software like MS Office or StarOffice. I humbly submit that APPLESOFT is the only organization to demonstrate the possibility of using ISCII for internal storage with standard application software like Notepad, Wordpad, MS Word etc. I am quoting these two of my technological contributions to Indian Languages which enabled the most popular OS of the day. I would like to draw the attention of member of this forum to note that, it is this group continuously blamed the developers since the inception of KGP through mass media propaganda, fooled the media persons by claiming ISCII superiority on one hand and developing software using glyphs on the other hand. That is the reason I am trying to expose these people. So, you are accepting that you have followed Tamil standardisation effort. You are referring to Tamil standardisation effort now to cover up your mischievous standards. While giving interviews or instigating others to write your standardisation efforts you people were conveniently hiding the fact that your standardisation efforts were based on Tamil, while so far claiming your standardisation efforts are first of its kind in India. * Why only referring Tamil - with my own expenses incurring financial losses contributed to develop language standardisation efforts of all languages which I came to know. * Why bother about whether anybody invented any new technology for Tamil or not. * If Tamil got developed it would have been a model for people like you to copy and claim. * Can you justify that if Tamil was not developed, you people also would not develop Kannada. Since you people (Refer Dr. Pavanaja's interview with Frederick Noronha, "Kannada Connects" available on-line at http://www.blonnet.com/ew/2002/03/06/stories/2002030600090200.htm and "Kannada on the keyboard, finally" available at http://www.zdnetindia.com/print.html, he says "We feel the best solution is to have the storage in ISCII. Other solutions have attempted to tie up the user in their own software solutions") are claiming the ISCII is the most suitable for Kannada, it is your interest to develop/invent a technology to handle ISCII and not Tamils to invent technology of ISCII who are not accepting ISCII as a suitable standard for TAMIL. Same is the case with Unicode. That is the reason, why Tamilnadu Government attempted to make a scientific study on the alternate encoding mechanism which NO other Indian language has ever attempted. If you people have made any attempt to prove efficiency of KSCLP over ISCII/Unicode, why it is not published, you make it public. TSCII is not a standard announced or endorsed by any government and hence TSCII is not a approved standard. TSCII is being promoted by people who don't accept the standards. TSCII may become a standard if the user community accepts it because of the failure of the standards. For your information, Tamilnadu Government has announced three prototype encoding standards based on character encoding, a bi-lingual glyph encoding, a monolingual glyph encoding. However, Character encoding standard is still pending. As of now only TAB and TAM are the only standards for Tamil. If you need any further details why three encoding is needed for a language, you may refer to my paper presented in the Tamil Internet 1999 International seminar held at Chennai. If you don't get any information, you may come to my office and have a look into it. If you still not clear on the standardisation issues, you refer to my book on Evolving Tamil Standards which deals with aspects of existing and evolving standards. Further, you are free to contact me for any clarifications. If you don't wish to do so, we still continue on this forum. In my opinion none of the font (the so called) standards can be accepted as standards as they are yet to be recognised by the standards body. As you people always blame the developer, I have not seen any instance of such thing in Tamil computing. Moreover, there is no instances of unethical copying of technology like you people have done and blaming the developer. ----------------------------------------------------------------------------------------------------------- Anbarasan : Later on, when the Specific Group reached the peak of confusion, came out with another altogether different set of character set as Kannada Standard Code for Language Processing. Strangely, the arguable special symbol for 'r' is left out in this character set. If KSCLP code set is meant for Language processing, then what else the other encodings ISCII/UNICODE etc., do. Does it mean that the Group is not aware of the sorting problems when they submitted the recommendation. Why the Government is insisting on SORTING order as per ISCII when KGP is allowed to do sorting based on KSCLP. Is it not a malpractice recommending two different standards based on altogether different principle and use it for self advantage. Are they not misleading the Kannada people, people of Karnataka and the Government of Karnataka. If Character encoding (KSCLP) is the most suitable for Kannada Language processing, why the same was not recommended for Unicode. Is it not a wonder? KGP : We have never came out with confusion, instead we are still using ISCII for storage in Nudi to maintain the National standards, where as design of ISCII never solves the sorting problems of Kannada so for sorting, searching and other language processing we are using KSCLP as the INTERMEDIET CODE. and also as the govt. standard says "WE CAN NOT CHANGE OUR LANGUAGE RULES TO SUITE THE TECHNOLOGY, INSTEAD TECHNOLOGY HAS TO BE CHANGED TO SUIT THE LANGUAGE" and KSCLP is the best example for this. its true that KSCLP is most suitable for Kannada language processing, but since "wrong standards which were in ISCII, is also copied to Unicode" ( Its Realy a wonder ) and now consortium cannot modify the previous standard, the KSCLP recommended by KGP is not accepted by Unicode consortium. Anbarasan : You people are playing a dirty game by combining a dirty wordprocessor and dirty input interface and confuse the concerned Govt officials and journalist by false claims. Wherein, ISCII storage facility is provided only in the NUDI wordprocessor, while input interface of NUDI facilitates storing glyphs. Simillary, when you people claim Nudi is having sorting facility, can NUDI facilitate sorting in all application software where sorting facility for English is available. Definitely NO. Then why you people are misleading everyone by saying NUDI is having sorting facility. When NUDI is used as a keyboard interface with any off-the-shelf application for example say MS Word, the storage is still glyphs not ISCII as you are claiming. By making this kind of blind statements, you are also exposing your malpractice. It is known for every one, who is involved with standards that the purpose of standard encoding is not solving the sorting problems but to achieve linguistic analysis (refer Unicode). To achieve sorting, a separate table needs to be maintained. So, a table designed to handle sorting issue can't be called as a standard for a language. Then why you people claim KSCLP(which is designed for sorting) as a standard for Kannada and recommend to Unicode consortium. Have you ever submited your KSCLP standard to MCIT or BIS for their consideration as a standard for Kannada. Let KSCLP be a most suitable standard for Kannada, when KGP has submitted the KSCLP proposed to Unicode consortium? through whom? what is the reference? who has represented KGP?, who has attended the Unicode consortium Meeting? why the same was not sent to Karnataka Government to forward the same? is that KGP has submitted the proposal directly to Unicode Consortium to project itself. Which is the Govt order you are referring. Don't quote anything off the air, substantiate all your claims with appropriate reference/results. If ISCII is a wrong standard, as you pointed out, the same wrong standard is also copied into Unicode. How dare you people are hiding the very fact that you people have prepared documentation for the same wrong Unicode and sent to Unicode consortium for its inclusion. It is to be noted that KSCLP is based on pure consonant approach where the Consonant and vowel combines (it also contains vowel signs or mathras, which is the secondary symbol of the vowels. For NLP the text is expected to be based on the Vowels and Consonants. For sorting, it is expected to be based on Vowel signs. Can the same text be available in two different encodings.) whereas ISCII/Unicode is based on vowelised consonant where the vowelised consonant joins with the mathras to form vowelconsonants (the vowels don't join with the consonants). Afterall KSCLP can be used only for sorting not NLP, which is based on the vowels and consonants. In KSCLP mathras are used to form vowelconsonants. Why you people claim both (KSCLP and Unicode) as standard. ----------------------------------------------------------------------------------------------------------- Anbarasan : Let me focus on, how ambiguously they interpret the Language, which resulted in today's anarchy. Leave alone the complexities of script composition, Kannada has one special interpretation of consonant 'r' as in Karnataka when written in Kannada. Which is a most commonly used form of 'r'. The so called experts, instead of handling the complexity of 'r' in the software have introduced it as one of the symbol in the standards announced for Kannada Keyboard (reference Karnataka G.O sa am ka e 70 kaa 99 dated 4-2-1999). In this standard, 47 necessary Kannada characters and 4 symbols are listed for modern Kannada language issued by the secretariat of Kannada and Culture. KGP : The keyboard layout is designed by our experts is to suit all sorts of end users such as the users who are familier with using the Kanglish keyboard in Baraha, Typewriter users, KP Rao layout users, and the DOE layout users. After a discussion it is found that DOE layout is most horrible which is very difficult to learn and the number of keystrokes are more. Kanglish layout in Baraha is offcource easy for Kanglish users but it will be difficult for the users who dont know english, ( A user has to learn english to work with Kannada software Baraha ) and offcource it is not a Kannada keyboard layout its a standard English Keyboard. KP Rao layout is most suitable to all ( Even for those who are using Baraha ) and is very easy to lean ( Its proved ). So KGP finaly came out with KP Rao Keyboard layout with some some small changes which were recomonded by expers. Anbarasan : You have not answered the basic question of why the dual interpretation of 'r' is included in the keyboard standard as separate key. I am interested in evolving the best of the features for a standard as such, can you publish your findings on Inscript keyboard, let people know how horrible is DOE keyboard!. Without any substantiable study or findings and without disclosing any such study if at all you have carried out, no one will buy your statements. "Discuss and discard" is the way you people have evolved all the standards without any scientific study or implementation. How your keyboard is proved over others, any sensible debate/discussions needs scientific findings. As you cry for the heavenliness of the development you made, can you point out the discussion forums/e-groups/details on the committees who have discussed/studied/proved the greatness of your standards. Can you at least point out any RFC for these developments. Or at least can you list out the design principles of the standards, in my argument, you people didn't have any design principles either for keyboard layout design or Font design or prescribed minimum feature for Kannada software. When Baraha input method can be used only by those who know English as you point out, How come KP Rao keyboard can be used without learning English. Afterall, the Kannada letters in the KP Rao keyboard layout were mapped based on the English letters. The fact is, you people wanted to take advantage of default English keyboard to learn / remember the Kannada keys by foregoing the advantage of designing a keyboard based on scientific study like frequency analysis and linguistic analysis. ----------------------------------------------------------------------------------------------------------- Anbarasan : Can any one list out the ten features that KGP has provided with NUDI as claimed by the Specific Group. NUDI, purported to be the benchmark software has been developed with non-standard fonts like English numerals, bi-lingual fonts, No conversion utilities. KGP : Font with English numerals can not be a non standard font since portabality will be there. It is just provided for the convience of user. When talking about Nudi its not a full fledged word Processor. It is a Keyboard driver which works for layout specified by Govt. Of Karnataka, and some fonts with Govt standards. Nudi ( Latest is 3.0 Release 2 ) comes with many features as fallows. - Sorting is provided as per the "Kannada Sahitya" which is there in none of other Kannada Softwares which were only developed for DTP operators. - SDK is provided with conversion functions from and to all types of codes like KSCLP, ISCII, Bi-Lingual Glyph, Monolinugual glyph, in-built keyboard engine which can be used by any developers to develop Kannada applications "which are not only meant for DTP operators". -Template files given for MS-Word and MS-Excel ( available in Release 2 ) which allows to sort search and to use many other features which are available in MS-Word, MS-Excel. Anbarasan : Nobody accept NUDI as a software, it crudely provides input interface that's all. It is not even a driver as claimed by you. What is the Govt standard? Govt standard only contains Glyphs for Kannada script, Kannada Numerals, and Punctuation marks Govt never announced any standard with Bi-lingual nature, if anything is there, you would have given reference to that. In the absence of any standard for Bi-lingual fonts, don't claim that NUDI comes with Government standard fonts and a software based on a standard has to follow the standards. You people could have added additional features but not the fonts based on the proprietory encoding. You people have implemented bi-lingual fonts to establish monopoly by taking undue advantage by implementing this non-standard font in the e-governance projects. It is sure that this is going to messup the data while migrating to another encoding say Unicode. As you have copied the methodology of our software which were given for testing, evaluation and certification. You have copied the methodology of providing sorting facility in MS Word in NUDI, your claim of no software were developed with sorting is false and intentional to defame and gain undue advantage and fame for yourself. The proof of our software SURABHI having sorting facility is the test report given by the KGP. "Standardisation is somethig that has to be imposed" says Dr. Pavanaja in the interview quoted elsewhere in this mail. You people must understand that standards can't be imposed. You people can play the dirty game only to gain monopoly in the Kannada software field by introducing the non-standard fonts like Bi-lingual fonts as you have introduced with NUDI and in the e-governance projects of Government of Karnataka. It is sure that your monopoly act would only result in bottleneck for Kannada in further development. You are still accusing the developer (you are trying to be out of the developer community) while still following the same age old methodology. It is a unfair game you people have just started. Atlast, you are accepting you are not a developer but you are a tinkerer. That is why you have taken a sample code and tinkered around to put UI in Kannada and claimed you have developed the controversial NUDI. Do you people have developed the NUDI software without funding from Government. Even after receiving fund from the Government you people are conveniently hiding the fact that NUDI is funded by the Government. It is also true that you people are distributing NUDI for Rs.100.00 per copy (while spending only 20% of it, it means that you are making 80% profit) without any training or support. My accusation is that you people are getting funds from the Government and try to build your foundations for future business prospects by monopolising Kannada software industry with the help of the officials of Directorate of Information Technology. Dr. Pavanaja's Visvakannada Softech is the example of this type. ----------------------------------------------------------------------------------------------------------- Anbarasan : Kannada has become a victim of jealousy KGP. I wish Kannada with its outstanding 2300 years of survival and very rich literary contribution has to face this challenge and expose the erratic management of Kannada standards by KGP to maintain its sustained growth and enthronement on digital media. With my everlasting love and creed towards Kannada Kasthuri I have taken your precious time. I welcome your views on this subject. KGP : Kannada was a victim of jealousy Kannada Software developers who developed keyboard drivers with some ( Beautiful fontS ) just to attract DTP operators and make money they were never thought of developing some standards for glyph and storage ( if they do this they will loose customers ). Now there game is end!. THANK GOD FINALLY SOME STANDARDS HAS COME. I wish Kannada with its outstanding 2300 years of survival and very rich literary contribution has to face this challenge and support standards provided by Govt. Of. Karnataka. With my everlasting love and creed towards Kannada I welcome your comments on this subject. Anbarasan : Your accusation on the Kannada software developers that the developers never contributed in developing standards is like a daylight robbery. It tentamounts to show the most vulnerable ungrateful re-course on those who have spent their everything for the noble cause of beloved languages on digital media. After the committee on standardising glyphs and codes have submitted the draft version, the same was sent to the developers for their comments. Developers of SURABHI, BARAHA, SHREE LIPI have contributed details on the usability of codes, organising the glyphs etc. The present standard is the witness for how much of the developers comments have helped in evolving the standard. By hiding their contributions, you are exposing your integrity (which is being questioned). It is unfortunate that the Government is sponsoring your activities and colluded with you people. I thought you people only copy the methodology and technolgy invented by others but your reply proves you are copying even the writings (feelings). N. ANBARASAN email : ar...@bg... , phone : +91-080-3386167. |
|
From: Sayamindu D. <unm...@So...> - 2002-11-17 05:54:39
|
-----Forwarded Message----- From: Anirban Mitra <mit...@ya...> To: Free Fonts <fre...@no...> Subject: [Freebangfont-devel] Bengali OT specification Date: 17 Nov 2002 05:28:40 +0000 Hi all, Microsoft have finalised and published Bengali OpenType Specification. It is available at the URL www.microsoft.com/typography/otfntdev/bengalot/default.htm . I feel we should also follow the specifications for cross platform compatibility. Not much change will be required in our fonts. -cheers- ===== Dr Anirban Mitra |||| || || || || || ||||||||||||||||||||||||||||||| |||| | || || || || ||| || || || || || || || ||| || || | || || || || |||||| || || ||| ||| || || ||| || || || | || || ________________________________________________________________________ Missed your favourite TV serial last night? Try the new, Yahoo! TV. visit http://in.tv.yahoo.com _______________________________________________ Freebangfont-Devel mailing list Fre...@no... http://mail.nongnu.org/mailman/listinfo/freebangfont-devel -- Sayamindu Dasgupta [http://www.peacefulaction.org/sayamindu/] * GNU is Not Unix * .... Towards World Liberation .... http://www.gnu.org |
|
From: Harsha K.M. <kmh...@ho...> - 2002-11-14 06:53:40
|
RE - ANARCHY OF KANNADA STANDARDS IN IT Hi All, I would like to comment on the mail sent by Mr. N. ANBARASAN. and I hope my answers will help him in understanding the Standards Approved by Govt. Of Karnataka. Comments are welcome. > It is this annoying trick which is being followed by the 'Specific Group' for Kannada in standardising and developing NUDI for Kannada while blaming the developers. Why this 'Specific Group' never >attempted to invent a technology to handle Kannada efficiently using ISCII on computers for the off-the-shelf applications. I leave it to your guess and further pacifying. Why you people never attempted to invent a technology to handle Tamil efficiently using ISCII ? and why are you people using TSCII ? > Later on, when the Specific Group reached the peak of confusion, came out with another altogether different set of character set as Kannada Standard Code for Language Processing. Strangely, the >arguable special symbol for 'r' is left out in this character set. If KSCLP code set is meant for Language processing, then what else the other encodings ISCII/UNICODE etc., do. Does it mean that the >Group is not aware of the sorting problems when they submitted the recommendation. Why the Government is insisting on SORTING order as per ISCII when KGP is allowed to do sorting based on >KSCLP. Is it not a malpractice recommending two different standards based on altogether different principle and use it for self advantage. Are they not misleading the Kannada people, people of >Karnataka and the Government of Karnataka. If Character encoding (KSCLP) is the most suitable for Kannada Language processing, why the same was not recommended for Unicode. Is it not a >wonder ? We have never came out with confusion, instead we are still using ISCII for storage in Nudi to maintain the National standards, where as design of ISCII never solves the sorting problems of Kannada so for sorting, searching and other language processing we are using KSCLP as the INTERMEDIET CODE. and also as the govt. standard says "WE CAN NOT CHANGE OUR LANGUAGE RULES TO SUITE THE TECHNOLOGY, INSTEAD TECHNOLOGY HAS TO BE CHANGED TO SUIT THE LANGUAGE" and KSCLP is the best example for this. its true that KSCLP is most suitable for Kannada language processing, but since "wrong standards which were in ISCII, is also copied to Unicode" ( Its Realy a wonder ) and now consortium cannot modify the previous standard, the KSCLP recommended by KGP is not accepted by Unicode consortium. > Let me focus on, how ambiguously they interpret the Language, which resulted in today's anarchy. Leave alone the complexities of script composition, Kannada has one special interpretation of consonant >'r' as in Karnataka when written in Kannada. Which is a most commonly used form of 'r'. The so called experts, instead of handling the complexity of 'r' in the software have introduced it as one of the >symbol in the standards announced for Kannada Keyboard (reference Karnataka G.O sa am ka e 70 kaa 99 dated 4-2-1999). In this standard, 47 necessary Kannada characters and 4 symbols are listed >for modern Kannada language issued by the secretariat of Kannada and Culture. The keyboard layout is designed by our experts is to suit all sorts of end users such as the users who are familier with using the Kanglish keyboard in Baraha, Typewriter users, KP Rao layout users, and the DOE layout users. After a discussion it is found that DOE layout is most horrible which is very difficult to learn and the number of keystrokes are more. Kanglish layout in Baraha is offcource easy for Kanglish users but it will be difficult for the users who dont know english, ( A user has to learn english to work with Kannada software Baraha ) and offcource it is not a Kannada keyboard layout its a standard English Keyboard. KP Rao layout is most suitable to all ( Even for those who are using Baraha ) and is very easy to lean ( Its proved ). So KGP finaly came out with KP Rao Keyboard layout with some some small changes which were recomonded by expers. > Can any one list out the ten features that KGP has provided with NUDI as claimed by the Specific Group. NUDI, purported to be the benchmark software has been developed with non-standard fonts >like English numerals, bi-lingual fonts, No conversion utilities. Font with English numerals can not be a non standard font since portabality will be there. It is just provided for the convience of user. When talking about Nudi its not a full fledged word Processor. It is a Keyboard driver which works for layout specified by Govt. Of Karnataka, and some fonts with Govt standards. Nudi ( Latest is 3.0 Release 2 ) comes with many features as fallows. - Sorting is provided as per the "Kannada Sahitya" which is there in none of other Kannada Softwares which were only developed for DTP operators. - SDK is provided with conversion functions from and to all types of codes like KSCLP, ISCII, Bi-Lingual Glyph, Monolinugual glyph, in-built keyboard engine which can be used by any developers to develop Kannada applications "which are not only meant for DTP operators". -Template files given for MS-Word and MS-Excel ( available in Release 2 ) which allows to sort search and to use many other features which are available in MS-Word, MS-Excel. Kannada was a victim of jealousy Kannada Software developers who developed keyboard drivers with some ( Beautiful fontS ) just to attract DTP operators and make money they were never thought of developing some standards for glyph and storage ( if they do this they will loose customers ). Now there game is end!. THANK GOD FINALLY SOME STANDARDS HAS COME. I wish Kannada with its outstanding 2300 years of survival and very rich literary contribution has to face this challenge and and support standards provided by Govt. Of. Karnataka. With my everlasting love and creed towards Kannada I welcome your comments on this subject. Harsha Kodnad Software Engineer Kannada Ganaka Parishat., Gokale Inst. of Public Afairs, N. R. Colony, Bangalore. +91-80-6615972 kmh...@ho... |
|
From: Sayamindu D. <unm...@So...> - 2002-11-14 04:18:06
|
-----Forwarded Message----- From: G Waraich <wa...@li...> To: gno...@gn... Subject: New team for Punjabi (pa) Date: 14 Nov 2002 05:21:37 +0800 Hi, I would like to start a new team for Punjabi localization Name of the co-ordinator Gurupkar Waraich email of the co-ordinator wa...@li... website for localization punjabi-linux.sourceforge.net (approved site) Volunteers please get in touch so that we can start working. Cheers Gurupkar Waraich -- ______________________________________________ http://www.linuxmail.org/ Now with POP3/IMAP access for only US$19.95/yr Powered by Outblaze _______________________________________________ gnome-i18n mailing list gno...@gn... http://mail.gnome.org/mailman/listinfo/gnome-i18n -- Sayamindu Dasgupta [http://www.peacefulaction.org/sayamindu/] * GNU is Not Unix * .... Towards World Liberation .... http://www.gnu.org |
|
From: Sayamindu D. <unm...@So...> - 2002-11-12 18:24:20
|
On Tue, 2002-11-12 at 16:55, Bharateeya-OpenOffice wrote: > Hi All, > > We have a requirement for OT fonts in Tamil as well as in other > languages for our localization work on Linux. Would anyone help us in this > direction? > If you want Bengali OpenType fonts, please refer to http://www.nongnu.org/freebangfont/ We have 4 (beta - but ok for most jobs) sets of Bengali opentype fonts in there. -regds- sayamindu -- Sayamindu Dasgupta [http://www.peacefulaction.org/sayamindu/] * GNU is Not Unix * .... Towards World Liberation .... http://www.gnu.org |
|
From: Bharateeya-OpenOffice <bha...@nc...> - 2002-11-12 11:19:28
|
Hi All, We are a team from NCST, Bangalore, working on the localization and internationalization of OpenOffice.org in Indian Languages. We have localized OpenOffice.org in Hindi on Windows and Linux, and in Tamil on Windows. We have also enabled Complex Text Layout support for all main Indian languages as well as other Internationalization features like Indian currency and calendar translations in Hindi and Tamil, on Windows. Localization work in Tamil on Linux, as well as Complex Text Layout support and other Internationalization aspects on Linux OO.o is going on. Refer to our site http://www.ncb.ernet.in/bharateeyaoo for more information on our work. Our work has been recognized by OpenOffice.org Ref: http://l10n.openoffice.org/localization_responsibilities.html and is copyright approved. Ref: http://www.openoffice.org/copyright/copyrightapproved.html We have uploaded some screenshots of the localized applications on both Windows and Linux, and the localized binaries for Hindi and Tamil on Windows are available for a free download. The localized binaries on Linux will be uploaded soon. We have a requirement for OT fonts in Tamil as well as in other languages for our localization work on Linux. Would anyone help us in this direction? We also welcome any suggestions, comments and feedback about our work. Thank you and Best regards, BharateeyaOO.o Team ------------------------------------------------------------ |Bhupesh Koli <bh...@nc...>| |Shikha G Pillai <sh...@nc...> | |Velmani N <ve...@nc...>| ------------------------------------------------------------ |BharateeyaOO.o - Indian Language support in OpenOffice.org| |National Centre for Software Technology | |68, Electronics City, Bangalore - 561229 | |Tel: +91 80 852 3300/0239 | |Web: http://www.ncb.ernet.in/bharateeyaoo | |Email: bha...@nc... | ------------------------------------------------------------ |
|
From: M K S. <mk...@co...> - 2002-11-12 04:15:27
|
>> Does anybody know of (preferably free) TSCII to UTF-8 converters for >> Tamil? Alok Hans Peter Bieker wrote a UTF8 <--> TSCII codec long time back. You can contact him & obtain the source. bi...@st... for TSCII related posting you will get quick response in ts...@ya... -- mks -- |
|
From: Guntupalli K. <kar...@fr...> - 2002-11-11 15:59:57
|
On Mon, 11 Nov 2002 14:31:54 +0000 (GMT) Alok Kumar <al...@ya...> wrote: > Hi, > Does anybody know of (preferably free) TSCII to UTF-8 converters for > Tamil? Alok > I dont know of any, but Qt has a Unicode to TSCII codec & vice versa. See attached qtsciicodec.cpp Regards, Karunakar -- Hating people is like burning down your house to get rid of a rat - Anon ------------------------------------ * Linux Bangalore/2002 * * Technology for a Free World * * December 3/4/5, 2002 * * http://linux-bangalore.org/2002 * ------------------------------------ |
|
From: <al...@ya...> - 2002-11-11 14:32:00
|
Hi, Does anybody know of (preferably free) TSCII to UTF-8 converters for Tamil? Alok ===== This message was sent from alkuma "at" yahoo "dot" com http://www.geocities.com/alkuma/ http://www.geocities.com/mudralipi http://www.geocities.com/shabdanjali/ http://hindi.mozzie.org ________________________________________________________________________ Missed your favourite TV serial last night? Try the new, Yahoo! TV. visit http://in.tv.yahoo.com |
|
From: <ar...@bg...> - 2002-11-08 12:21:19
|
ANARCHY OF KANNADA STANDARDS IN IT. Historically, standards were never forced or defined without thorough evaluation to analyse the pros/cons and implementations on trial basis. Standards evolve and becomes mandatory for a measure of quality assurance and building consensus among all the concerned regarding norms for compliance and criteria for certification. How the goals of standardisation could be achieved by adopting controversial methods in evolving standard glyph set / font / encoding for Kannada. Since, topic of this mail is around code set - about its usefulness and interoperability. I take an example of PC character set. How this character set has become acceptable to all PC manufacturers, OS developers, application developers etc, inspite of the provision to alter or change the character generator to define ones choice of character set. The character set defined by IBM was accepted by the whole Industry for the sake of interoperability. Interoperability is an important criteria for a standard to succeed. Well. Is there interoperability in the standards of Kannada for computers. Introduction Often Indian Languages complexities really complicates the so called expert of the field and influence the officials to favour their idealism and get funded their efforts and confuse those end users, who are already in dilemma say a typist - a government employee who is at the receiving end of the resultant half baked potatoes. You may be wondering what relevance this mail has to you. As you are interested in Indian Language computing, I thought it would be of some interest to you. Is there any single product available for Indian Languages, which can talk of some technological marvel. No. It is to be noted that every Indian Language is now implemented just by hacking the fonts. Even the hacking of font is not made properly in many instances. I take the example of Kannada to go into the details of "How Kannada Language / Script / Glyph / Font / Code is being handled for standardisation". I have included Language, Script, Glyph, Font and code just to throw some light on the ambiguities the people concerned have implied in standardising Kannada. Indian Script code standard All the Indian Languages were encoded as ISCII (Indian Script Code for Information Interchange - this often misinterpreted as Indian Standard Code for Information Interchange) based on the script principles of Vowels and Consonants. Hence, this standard has only Signs, Vowels, Vowelconsonants (instead of using of pure consonant, a consonant having an initial vowel in it, which is a base for writing the script and non-use of pure consonant in Devanagari is the reason.), Vowel signs (to differentiate from the vowels in a string and to avoid auto-combining feature of consonant and vowel when a vowel comes in the non-initial position). This principle is also adopted in the Unicode (Which is supposed to be a character encoding) for Indian Languages based on the earlier version of ISCII. Indian Script implementation As the existing OS (except MS Windows 2000 and MS Windows XP) does not have the capability to handle these standards, the enthusiastic developers found a trick of having the glyphs in some useful manner for these languages and handle the combinational complexities at the input level. As this kind of trick was being followed with the MS DOS based DTP softwares prior to MS Windows popularisation, the same trick was followed even for MS Windows for the sake of convertibility and its ease of use. When all the available Indian Language solutions are based on these hack tricks, NO technology is existing on the GUI based operating systems like MS Windows to handle ISCII with the off-the-shelf application software like Office suites. It is this annoying trick which is being followed by the 'Specific Group' for Kannada in standardising and developing NUDI for Kannada while blaming the developers. Why this 'Specific Group' never attempted to invent a technology to handle Kannada efficiently using ISCII on computers for the off-the-shelf applications. I leave it to your guess and further pacifying. Kannada standards Let me focus on, how ambiguously they interpret the Language, which resulted in today's anarchy. Leave alone the complexities of script composition, Kannada has one special interpretation of consonant 'r' as in Karnataka when written in Kannada. Which is a most commonly used form of 'r'. The so called experts, instead of handling the complexity of 'r' in the software have introduced it as one of the symbol in the standards announced for Kannada Keyboard (reference Karnataka G.O sa am ka e 70 kaa 99 dated 4-2-1999). In this standard, 47 necessary Kannada characters and 4 symbols are listed for modern Kannada language issued by the secretariat of Kannada and Culture. When the same Specific Group sent recommendation for Kannada in Unicode to Government of India through Directorate of Information Technology of Government of Karnataka, have left two diacritic marks(part of the above standard), which were recommended for composing Vedic text. But, included a new set of additional characters. Later on, when the Specific Group reached the peak of confusion, came out with another altogether different set of character set as Kannada Standard Code for Language Processing. Strangely, the arguable special symbol for 'r' is left out in this character set. If KSCLP code set is meant for Language processing, then what else the other encodings ISCII/UNICODE etc., do. Does it mean that the Group is not aware of the sorting problems when they submitted the recommendation. Why the Government is insisting on SORTING order as per ISCII when KGP is allowed to do sorting based on KSCLP. Is it not a malpractice recommending two different standards based on altogether different principle and use it for self advantage. Are they not misleading the Kannada people, people of Karnataka and the Government of Karnataka. If Character encoding (KSCLP) is the most suitable for Kannada Language processing, why the same was not recommended for Unicode. Is it not a wonder ? Font Standards Leave apart the Kannada character set, which the Specificd Group handle/suggest/innovate. Let me throw some light on their script handling glyph code standards. To solve the Kannada text portability and its compatibility, the Government of Karnataka have appointed a Committee, which included constituents of Specific Group. The Specific Group has submitted the report recommending a set of Glyphs and Glyph codes and was announced as standard on Nov 1, 2000. The Specific Group has managed to get funding to develop a model software (an input handling software), and the same was developed and announced without even bothering about the minimum features, which were recommended by the same Specific Group. Later on, when a difficulty arose in using their standards for e-governance projects which requires English to be part of the user choice, they had silently included a bi-lingual glyph encoding by making use of the code positions which were spared due to its unusability of nature. I wonder how the Government is promoting the bi-lingual encoding which is based on the codes which are spared while evolving the mono-lingual glyph standard. If the Specified Group decide as they wish, then why the Government appoints committee to standardise glyphs and glyph codes for Kannada. Is it to approve by stamping or to elevate the Specific Group to a level of consultants to Microsoft. Conversion When a document created using KGP recommended Unicode is converted to KSCLP, it will be a lossy conversion resulting into loss of diacritic marks recommended for Vedic texts and 'ru' long vowel and 'ru' long vowel consonants. Similarly, when one tries to convert the text created in mono-lingual encoding into bi-lingual encoding it will result into loss of data. As the diacritic marks were not part of the recommended glyph set but recommended as part of the keyboard standard, any software to be developed as per the prevailing standard, developers are allowed to accommodate the diacritic marks as per their convenience. If such Software are used, it will only result into non-standard, non-compatible font and text will result in non-portable format. How anybody can write a converter utility to convert the texts created with diacritic marks, which are allowed in any vacant codes in any order. This may be the reason why the Specific Group has not attempted to provide a conversion utility for their software NUDI. Keyboard standard It is often argued that the strength of the standardised keyboard lies in the layout being managed within the keys meant for English. English keys are used as reference for the user to remember the keys. However, it is conveniently forgotten the loading of fingers. In the standard Kannada keyboard, left hand is loaded with 15 keys and the right hand is loaded with 11 keys (excluding the punctuation keys). Normally, when a keyboard layout is designed, the frequency analysis of letters and in turn keystrokes are considered. When, language specific encoding standards and keyboard layouts are getting evolved worldwide, it is strange that the Specific Group managed to get attestation from the Government for their unscientific keyboard layout. It is alarming the Group also try to influence the other language groups working in the area of standardisation efforts. NUDI The Specific Group cleverly managed to get the support of the concerned authorities of the Government of Karnataka and made use of the Government machinery to fulfill their whimsical will. As once one amongst the Specific Group was blaming the developers for proprietary glyph encoding "We feel the best solution is to have the storage in ISCII. Other solutions have attempted to tie up the user in their own software solutions". But in reality they have succeeded in announcing their proprietory set of glyphs as standard and have not provided a solution for storage in ISCII for the off-the-shelf applications. It amply proves of their lip service. You may be wondering as who are these friends. They are none other than Dr. U.B Pavanaja, who holds Vishva Kannada Softech, Mr C. V Srinatha Sastry, General Secretary of Kannada Ganaka Parishat, Mr. G. N Narasimha Murthy, Secretary of Kannada Ganaka Parishat (I have not mentioned their attached institutions to maintain the dignity of the Institutions) Now the KGP has tied up the Government users by forcing to use the proprietary non-standard bi-lingual encoding by implementing the e-governance projects with the blessings of Kannada Development Authority and with the support of Directorate of Information Technology which is the controlling and monitoring body of the IT requirements of Government of Karnataka. Can any one list out the ten features that KGP has provided with NUDI as claimed by the Specific Group. NUDI, purported to be the benchmark software has been developed with non-standard fonts like English numerals, bi-lingual fonts, No conversion utilities. While KGP sings for standard for Kannada, what has prompted them to develop NUDI using a non-standard bi-lingual font. When the Directorate of Information technology penalises the shortlisted developers for not having followed the standard, what is the modus operandi behind promoting the non-standard uncertified software NUDI. Kannada Development KGP is successful in implementing (by influencing the project handling agencies) e-governance projects in non-standard proprietary bi-lingual glyphs by restricting all the Government data flow only confining to its wishes. Is it not a dirty trick. KGP is increasingly using yet another proprietary encoding for its own internal implementations and pass on their invisible internal encoding in the name of SDK, just crawl and grab the entire application development in Kannada. This proprietary encoding is also being used in the New NLP projects which KGP has started developing with huge funds flooded from the Government. With this initiative, KGP would build a considerable size of MRD, which are necessary for NLP projects. Can anyone explain how this huge size of MRD is interoperable and how it is going to help develop Kannada on computers. Kannada has become a victim of jealousy KGP. I wish Kannada with its outstanding 2300 years of survival and very rich literary contribution has to face this challenge and expose the erratic management of Kannada standards by KGP to maintain its sustained growth and enthronement on digital media. With my everlasting love and creed towards Kannada Kasthuri I have taken your precious time. I welcome your views on this subject. N. ANBARASAN email : ar...@bg... , phone : +91-080-3386167. |
|
From: Arun S. <ar...@sh...> - 2002-11-08 04:39:34
|
There is some interesting information posted to the message board here: http://sourceforge.net/forum/forum.php?thread_id=757113&forum_id=151750 STSF is taking an approach not very different from what I was proposing for IndiX i.e. - Do all the Indic computing reordering based on X extensions, rather than modifying existing X protocol requests. - X Server side opentype font support They're also using the ICU layout library from IBM to do the reordering. The projected release date is December or January. They sound quite confident about getting their stuff into the XFree86 source base. But it might be a while before distributors pick it up. In the meanwhile, there may be some work for volunteers on this forum to package up their work so that it gets plenty of testing. -Arun |

{kind=link}
{kind=link}