Menu
▾
▴
tinyscheme-issues
|
From: Andrea R. <and...@gm...> - 2013-12-28 02:10:32
|
Hello everyone,
my test1.scm testcase runs correctly until the end,
but in test2.scm TinyScheme emits a "No memory!"
error message in the middle of the execution, then
quits immediately.
In the testcases I'm basically doing
(set! vvv (make-vector ...)) several times,
I expected that garbage collection would
reclaim the previous vectors' memory.
I'm new to Scheme and I can't understand if the
problem is in my testcases or in TinyScheme.
Thanks in advance for any suggestion or
advice you may provide, kindest regards.
Andrea
Further details:
I'm running TinyScheme 1.41 r100 on Win7,
compiled with MinGW gcc 4.7.0 and these flags:
-fpic -pedantic -I. -c -g -Wno-char-subscripts
-O -DUSE_STRLWR=0 -DUSE_DL=1 -DUSE_MATH=1
-DUSE_ASCII_NAMES=0
----------- test1.scm: OK --------------
(define vvv '#())
(do ((i 0 (+ i 1))) ((>= i 100000)) ; for 100000 times...
(if (= 0 (remainder i 1000)) (begin (write i) (newline))) ; write a log line every 1000 cycles
(set! vvv (make-vector 5000 "blabla"))) ; overwrite vvv with a new vector
(set! vvv '#())
----------- output for test1.scm -------
$ scheme test1.scm
0
1000
2000
...
99000
----- test2.scm: what's wrong here? -----
(define vvv '#())
(do ((i 0 (+ i 1))) ((>= i 100000)) ; for 100000 times...
(if (= 0 (remainder i 1000)) (begin (write i) (newline))) ; write a log line every 1000 cycles
(do ((j 0 (+ j 1))) ((>= j 1)) ; for 1 time...
(set! vvv (make-vector 5000 "blabla")))) ; overwrite vvv with a new vector
(set! vvv '#())
----------- output for test2.scm -------
$ scheme test2.scm
0
1000
2000
3000
4000
5000
No memory!
----------------------------------------
|
|
From: Sanel Z. <sa...@gm...> - 2014-01-01 17:36:03
|
On 12/28/13, Andrea Rossetti wrote: > In the testcases I'm basically doing > (set! vvv (make-vector ...)) several times, > I expected that garbage collection would > reclaim the previous vectors' memory. > > I'm new to Scheme and I can't understand if the > problem is in my testcases or in TinyScheme. > Thanks in advance for any suggestion or > advice you may provide, kindest regards. Looks like a bug in GC, because these vectors should be collected. From my tests, even putting explicit collection with '(gc)' as part of loop will not help. I would suggest you report it as issue and developers will look it at some point. > Andrea Best, Sanel |
|
From: Kevin C. <ke...@ve...> - 2014-01-01 20:06:40
|
On 14-01-01 12:34 PM, Sanel Zukan wrote:> On 12/28/13, Andrea Rossetti wrote: >> In the testcases I'm basically doing >> (set! vvv (make-vector ...)) several times, >> I expected that garbage collection would >> reclaim the previous vectors' memory. > > Looks like a bug in GC, because these vectors should be > collected. From my tests, even putting explicit collection with '(gc)' > as part of loop will not help. I took a quick look at this but didn't see anything obvious. I'll take a further look at this once I finish the documentation I'm working on for another project. -- Cheers! Kevin. http://www.ve3syb.ca/ |"Nerds make the shiny things that distract Owner of Elecraft K2 #2172 | the mouth-breathers, and that's why we're | powerful!" #include <disclaimer/favourite> | --Chris Hardwick |
|
From: Jonathan S. S. <sh...@er...> - 2014-01-02 01:56:43
|
I haven't looked at the code, but I would be surprised if this turns out to be a GC issue. Three things seem to be going on. Let me explain what I'm thinking. LIVENESS All of the vectors that are getting allocated here are the same size. In both tests, there are *two* vectors alive in memory in the steady state. This is true because at the moment of allocation, the *previous* vector is still referenced by vvv. The newly allocated vector will eventually be assigned to vvv when the call to MAKE-VECTOR returns, but there is a window of time during the allocation where that has not yet occurred. So in particular, the *previous* vector allocated during the GC that is triggered by the *current* vector allocation. Vectors are not allocated from a "large object space" in TinyScheme; they require contiguous space in the primary heap (this was at one time something I intended to fix). This means that a large block of contiguous free space is required in order for an array allocation to be possible. This means, in turn, that a single cons cell in the wrong place can make array allocation impossible. NON-RELOCATION The TinyScheme GC is a non-relocating GC. Most of the time this is fine, because almost every object allocated by TinyScheme is a cons cell. It becomes a problem when vectors are being allocated. If a single CONS cell sits in the middle of some big block of storage, the TinyScheme GC cannot move it out of the way in order to allocate a vector that would otherwise fit. While there is no other obvious allocation going on in test2.scm, the implementation of TinyScheme constructs its stack out of cons cells that are allocated from the heap. This means that the calls to REMAINDER, BEGIN, WRITE, and NEWLINE are actually allocating operations. The effect of this is that the locations of two live vectors are probably *not* always the same. There is some variance, because depending on the actual heap size being used it is possible that GC is not being triggered on every array allocation. When these three issues (two live arrays, CONS allocation, and non-relocation), it is *very* possible that the vectors and cons cells in the heap are getting allocated in oddly arranged locations in the heap, and that just a few of those CONS cells are dangling. Eventually, you have enough dangling CONS cells running around that no contiguous space exists in the heap to support allocation of the next vector. IMPLEMENTATION OF DO I do not recall how DO is implemented in TinyScheme. If it is a macro (as I suspect) that gets turned into a tail-recursive LAMBDA, or if the internal implementation operates in that sort of way, that would account for why CONS cells related to procedure calls are getting retained. Do we have a way to induce GC and get a dump of the number of heap words in use? If that number, computed immediately after the SET!, is rising, then the problem lies in either DO or WRITE. The first place I would look in the code is the implementation of DO, just to check if a retained CONS cell may be happening there. The second place I would look is the implementation of WRITE. There used to be an ungodly number of GC-related bugs in that part of the code, several of which would be triggered by int->string conversion. I would try nulling out VVV - or at least setting it to #() - before calling make-vector. If both tests pass with that change, then GC is working correctly and the problem is that we have live islands in the heap. That will at least confirm where we need to be looking. But more than anything, I would rerun this under a debugger with a breakpoint on the line that prints "No memory", and confirm that we're actually inside make-vector. I'm wondering if the internal implementation of WRITE may be leaking. In the long term, the right solution to all of this is to implement relocating GC. That would be a fairly major change to the TinyScheme library API, because it would require a different API from the standpoint of C code. Kevin: is TinyScheme being used actively enough at this point to make that sort of reimplementation worth considering? Jonathan On Wed, Jan 1, 2014 at 11:51 AM, Kevin Cozens <ke...@ve...> wrote: > On 14-01-01 12:34 PM, Sanel Zukan wrote:> On 12/28/13, Andrea Rossetti > wrote: > >> In the testcases I'm basically doing > >> (set! vvv (make-vector ...)) several times, > >> I expected that garbage collection would > >> reclaim the previous vectors' memory. > > > > Looks like a bug in GC, because these vectors should be > > collected. From my tests, even putting explicit collection with '(gc)' > > as part of loop will not help. > > I took a quick look at this but didn't see anything obvious. I'll take a > further look at this once I finish the documentation I'm working on for > another project. > > -- > Cheers! > > Kevin. > > http://www.ve3syb.ca/ |"Nerds make the shiny things that > distract > Owner of Elecraft K2 #2172 | the mouth-breathers, and that's why we're > | powerful!" > #include <disclaimer/favourite> | --Chris Hardwick > > > ------------------------------------------------------------------------------ > Rapidly troubleshoot problems before they affect your business. Most IT > organizations don't have a clear picture of how application performance > affects their revenue. With AppDynamics, you get 100% visibility into your > Java,.NET, & PHP application. Start your 15-day FREE TRIAL of AppDynamics > Pro! > http://pubads.g.doubleclick.net/gampad/clk?id=84349831&iu=/4140/ostg.clktrk > _______________________________________________ > Tinyscheme-issues mailing list > Tin...@li... > https://lists.sourceforge.net/lists/listinfo/tinyscheme-issues > > |
|
From: Kevin C. <ke...@ve...> - 2014-01-02 02:47:13
|
On 14-01-01 08:56 PM, Jonathan S. Shapiro wrote: > Kevin: is TinyScheme being used actively enough at this point to make that > sort of reimplementation worth considering? I know it is used in GIMP as part of Script-Fu. I don't know how actively it is used outside of GIMP. I can port any changes to TinyScheme to the version used in GIMP if the Api changes. -- Cheers! Kevin. http://www.ve3syb.ca/ |"Nerds make the shiny things that distract Owner of Elecraft K2 #2172 | the mouth-breathers, and that's why we're | powerful!" #include <disclaimer/favourite> | --Chris Hardwick |
|
From: Jonathan S. S. <sh...@er...> - 2014-01-02 03:00:16
|
If I were going to do a rework of that magnitude, I'd frankly be tempted to ditch call/cc in favor of exceptions as we discussed long ago. I'd be concerned about the impact of that on GIMP, though. Is there a quick way to grep through their scheme code to see what use they are making of call/cc? I'd guess that it's all in the way of implementing non-local return, but it might be good to check. The other problem with ditching call/cc, of course, is that Scheme without call/cc isn't really scheme. Jonathan On Wed, Jan 1, 2014 at 6:33 PM, Kevin Cozens <ke...@ve...> wrote: > On 14-01-01 08:56 PM, Jonathan S. Shapiro wrote: > > Kevin: is TinyScheme being used actively enough at this point to make > that > > sort of reimplementation worth considering? > > I know it is used in GIMP as part of Script-Fu. I don't know how actively > it > is used outside of GIMP. I can port any changes to TinyScheme to the > version > used in GIMP if the Api changes. > > -- > Cheers! > > Kevin. > > http://www.ve3syb.ca/ |"Nerds make the shiny things that > distract > Owner of Elecraft K2 #2172 | the mouth-breathers, and that's why we're > | powerful!" > #include <disclaimer/favourite> | --Chris Hardwick > > > ------------------------------------------------------------------------------ > Rapidly troubleshoot problems before they affect your business. Most IT > organizations don't have a clear picture of how application performance > affects their revenue. With AppDynamics, you get 100% visibility into your > Java,.NET, & PHP application. Start your 15-day FREE TRIAL of AppDynamics > Pro! > http://pubads.g.doubleclick.net/gampad/clk?id=84349831&iu=/4140/ostg.clktrk > _______________________________________________ > Tinyscheme-issues mailing list > Tin...@li... > https://lists.sourceforge.net/lists/listinfo/tinyscheme-issues > > |
|
From: Kevin C. <ke...@ve...> - 2014-01-02 17:19:25
|
On 14-01-01 10:00 PM, Jonathan S. Shapiro wrote: > If I were going to do a rework of that magnitude, I'd frankly be tempted to > ditch call/cc in favor of exceptions as we discussed long ago. I'd be > concerned about the impact of that on GIMP, though. [snip] > The other problem with ditching call/cc, of course, is that Scheme without > call/cc isn't really scheme. There will be no immediate impact on GIMP. It contains a copy of TinyScheme in its source tree. I had to modify it to include support for UTF-8 coded characters and strings. If UTF-8 support was added to TinyScheme I would be able to directly drop in changes to the version in GIMP instead of copying patches back and forth between the two versions. GIMP does not have any Scheme based scripts in its source tree that make use of call/cc, AFAICT. I have no idea if there are any third party scripts that use it. I doubt there are many, if any, scripts for GIMP using call/cc since most scripts aren't doing anything very complex. They are mostly just a way to automate some processes and apply effects to images. -- Cheers! Kevin. http://www.ve3syb.ca/ |"Nerds make the shiny things that distract Owner of Elecraft K2 #2172 | the mouth-breathers, and that's why we're | powerful!" #include <disclaimer/favourite> | --Chris Hardwick |
|
From: Sanel Z. <sa...@gm...> - 2014-01-03 11:50:42
|
On 01/01/14,Jonathan S. Shapiro wrote: > If I were going to do a rework of that magnitude, I'd frankly be > tempted to ditch call/cc in favor of exceptions as we discussed long > ago. I'd be concerned about the impact of that on GIMP, though. Maybe this isn't very good option. Beside it will render TS as uncompatible Scheme implementation, there are out some code which uses call/cc; at least I have it used on some places. > Jonathan Best, Sanel |
|
From: Sanel Z. <sa...@gm...> - 2014-01-03 12:20:58
|
On 01/01/14,Jonathan S. Shapiro wrote: > I haven't looked at the code, but I would be surprised if this turns > out to be a GC issue. Three things seem to be going on. Let me > explain what I'm thinking. Thanks for giving some details about GC internals. I always found TS GC the only 'hairy' part I didn't understand fully, especially because there aren't any builtin helpers, except (gc-verbose), to see what is going on. > IMPLEMENTATION OF DO > > I do not recall how DO is implemented in TinyScheme. If it is a macro > (as I suspect) that gets turned into a tail-recursive LAMBDA, or if > the internal implementation operates in that sort of way, that would > account for why CONS cells related to procedure calls are getting Yes, DO is macro. > In the long term, the right solution to all of this is to implement > relocating GC. That would be a fairly major change to the TinyScheme > library API, because it would require a different API from the > standpoint of C code. Will it require changing existing code that uses TinyScheme? Btw. when you are all here guys, I have some further questions regarding to GC and other things :) First, how hard is to add ability to dump image from loaded coded? I have a bit of Scheme code, loaded from couple of init-like files and it takes some time to start either REPL or binaries linked with TinyScheme. If you give me some pointers, I'll put it in my TS 'fork' and provide a patch for those who are interested about this feature. The second one is about GC. I'm loading TinyCLOS, not directly, but as part of some test suite and is dog slow; I assume it is because GC is called very often. Now I plan to use it extensively, but this slowness is unbearable for normal use. I tested it with s7 (https://ccrma.stanford.edu/software/snd/snd/s7.html) which is fork of TinyScheme and the load is instant. The same with other implementations... Any ideas what is going on? > Jonathan Best, Sanel |
|
From: Andrea R. <and...@gm...> - 2014-01-03 14:21:20
|
Hello Jonathan, hello everyone reading.
Some more tests and your advice convinced me too
that DO is retaining some cells. Here's what I tried:
"Jonathan S. Shapiro" <sh...@er...> writes:
>
> The first place I would look in the code is the implementation of DO, just
> to check if a retained CONS cell may be happening there.
> ....
> The second place I would look is the implementation of WRITE. There used to
> be an ungodly number of GC-related bugs in that part of the code, several
> of which would be triggered by int->string conversion.
- test3.scm: if I remove the (write ...) statement
in test2.scm, I still get a "No memory!" message; so WRITE
is probably not the issue here
- test4.scm: if I replace in test3.scm (make-vector 5000 ...)
with (make-vector 1 ...), I still get a "No memory!" message;
it takes more cycles of DO though (I think around 14000);
so I suspect that the error message can't be provoked by
memory fragmentation problems
- test5.scm: if I replace in test4.scm (do ((j 0 (+ j 1))) ((>= j 1)) ...)
with something "equivalent" like (when #t ...), (unless #f ...)
or (if #t ...), then the program runs until the end
without error messages
> But more than anything, I would rerun this under a debugger with a
> breakpoint on the line that prints "No memory", and confirm that we're
> actually inside make-vector. I'm wondering if the internal implementation
> of WRITE may be leaking.
I ran "scheme.exe test2.scm" in gdb, breakpoint on
fprintf(stderr,"No memory!\n"). Variables' inspection
at breakpoint time showed that:
- pcd->name="make-vector"
- sc->dump_size=2686868
It's the first time I see the TinyScheme sources, I tried to
"guess" and could have missed other relevant variables; in that
case please let me know, I'll be happy to report.
Kindest regards, best wishes for this new year.
Andrea
------------- test3.scm: No memory! --------------
(define vvv '#())
(do ((i 0 (+ i 1))) ((>= i 100000)) ; for 100000 times...
(do ((j 0 (+ j 1))) ((>= j 1)) ; for 1 time...
(set! vvv (make-vector 5000 "blabla")))) ; overwrite vvv with a new vector
(set! vvv '#())
------------- test4.scm: No memory! --------------
(define vvv '#())
(do ((i 0 (+ i 1))) ((>= i 100000)) ; for 100000 times...
(do ((j 0 (+ j 1))) ((>= j 1)) ; for 1 time...
(set! vvv (make-vector 1 "blabla")))) ; overwrite vvv with a new vector
(set! vvv '#())
------------- test5.scm: OK ----------------------
(define vvv '#())
(do ((i 0 (+ i 1))) ((>= i 100000)) ; for 100000 times...
(when #t ;
(set! vvv (make-vector 5000 "blabla")))) ; overwrite vvv with a new vector
(set! vvv '#())
|
|
From: Jonathan S. S. <sh...@er...> - 2014-01-03 17:35:03
|
Sanel: On Fri, Jan 3, 2014 at 3:19 AM, Sanel Zukan <sa...@gm...> wrote: Thanks for giving some details about GC internals. I always found TS > GC the only 'hairy' part I didn't understand fully, especially > because there aren't any builtin helpers, except (gc-verbose), to see > what is going on. > Yup. It really would be convenient if there were some sort of gc status call. The GC itself isn't really that hairy. The hairy part is understanding the relationship between the C code of the interpreter (where locals are not tracked) and the state variables of the interpreter state machine (which are tracked). When I first started looking at the code, it took me a while to wrap my head around that. The last time I looked, there are significant errors in that code down in the I/O subsystem. In particular, the error diagnostic printing code is likely to do entertaining things if the stderr stream is redirected to a string stream. The problem is that in the special case of string stream, the PUT-CHAR call can allocate (because string stream, under the covers, is implemented by a list of characters). The implementation of WRITE was done without recognition that PUT-CHAR could allocate. I put in a fair bit of effort at one point to fix it, but it was in the middle of an unrelated change, and I got bogged down. > > > IMPLEMENTATION OF DO > > > > I do not recall how DO is implemented in TinyScheme. If it is a macro > > (as I suspect) that gets turned into a tail-recursive LAMBDA, or if > > the internal implementation operates in that sort of way, that would > > account for why CONS cells related to procedure calls are getting > > Yes, DO is macro. > Kevin: My scheme is really rusty, and macros are hairy under the best of conditions. I took a look at the DO macro and couldn't figure this out. Could you take a hard look at the DO macro and confirm that it is properly tail recursive. If it isn't, that would account for the leak here. I'd also check that the interpreter implements tail-recursive call correctly, though I'm pretty sure it does. > > In the long term, the right solution to all of this is to implement > > relocating GC. That would be a fairly major change to the TinyScheme > > library API, because it would require a different API from the > > standpoint of C code. > > Will it require changing existing code that uses TinyScheme? > Yes. If we change to a relocating GC, then any C code that holds pointers into the scheme heap needs to pin/unpin those objects. Either that or we need to do a conservative mark on the C stack (which is probably easier, but requires a small amount of machine-dependent code). Even if we do conservative mark on the C stack, any globals that retain pointers into the scheme heap need to be registered. Globals containing references can safely be relocated if the target object is unpinned. Caveat to all of above: if the C code is multithreaded, and it multiple C threads may have pointers into the scheme heap, the conservative marking approach becomes *much* more complicated. As an example, consider that the boehm collector alone is larger than the entire TinyScheme implementation. But under the single-threaded assumption, I think it's very doable. The concern about global roots already exists, so we could probably adapt the implementation of existing macros for that part. So yeah, we'd probably need to keep both GCs (as a compile-time choice) for a few releases while people transition their C code, but the transition shouldn't be terribly invasive. In a lot of ways, the current inability to register roots on the C stack easily is a bug that needs to be addressed in any case. > First, how hard is to add ability to dump image from loaded coded? I > have a bit of Scheme code, loaded from couple of init-like files and > it takes some time to start either REPL or binaries linked with > TinyScheme. If you give me some pointers, I'll put it in my TS 'fork' > and provide a patch for those who are interested about this feature. > I don't think it will help. When TS loads one of those init files, it simply forms a sequence of in-heap lists. There is no internal bytecode; TS interpretation proceeds directly from the "as a list" version of the original source code. So the only thing you would save here is the time to tokenize at load time. The thing is, you'd still have to tokenize the result of dump-heap, because it would get dumped out in a form that is very close to the original text. Most of the tokenization time is taken up recognizing atoms, and that would have to be done on re-load even from a dump file. Because of this, I think a better investment would be to work on speeding up the tokenizer implementation. The switch-case dispatch trick that is used in the TS implementation was very clever for the needs of the original implementation, which had a heavily constrained code space requirement. But the compiler cannot do much to optimize it. The most important optimization, I think, would be to split the implementation of READ into a general form and a filestream-specific form. The general form should test the stream type, and if it is a filestream it should call the specific implementation. The specific implementation can then inline the use of GET-CHAR, and a whole *lot* of speedup can be had there. Oh. Also need to check that the binding of GET-CHAR hasn't been changed. One problem with implementing scheme is that standard identifiers can be whacked by SET!. > The second one is about GC. I'm loading TinyCLOS, not directly, but as > part of some test suite and is dog slow; I assume it is because GC is > called very often. Now I plan to use it extensively, but this slowness > is unbearable for normal use. > > I tested it with s7 > (https://ccrma.stanford.edu/software/snd/snd/s7.html) which is fork of > TinyScheme and the load is instant. The same with other implementations... > > Any ideas what is going on? Well the obvious thing would be to check the respective default heap sizes. I'm not familiar with S7. At the risk of asking a dumb question, why not just use S7 if it's doing what you need? Jonathan |
|
From: Sanel Z. <sa...@gm...> - 2014-01-08 01:04:10
|
On 01/03/14,Jonathan S. Shapiro wrote:
> The GC itself isn't really that hairy. The hairy part is
> understanding the relationship between the C code of the interpreter
> (where locals are not tracked) and the state variables of the
> interpreter state machine (which are tracked). When I first started
> looking at the code, it took me a while to wrap my head around that.
Do you have some time to write a short .txt file (it can be on TS
repository) describing GC and relationship between the C code and
state variables? Maybe mentioning intents behind current desing?
I think this will be quite useful for us to easier follow the code and
provide patches for 'hairier' code parts. Also, for some time, I'm
planning to write a series of articles about TinyScheme on my blog; I
noticed there are a lot of misconceptions about the interpreter
either because people used it badly or not at all.
> > > IMPLEMENTATION OF DO
> > >
> > > I do not recall how DO is implemented in TinyScheme. If it is a
> > > macro (as I suspect) that gets turned into a tail-recursive
> > > LAMBDA, or if the internal implementation operates in that sort
> > > of way, that would account for why CONS cells related to
> > > procedure calls are getting
> >
> > Yes, DO is macro.
> >
>
> Kevin: My scheme is really rusty, and macros are hairy under the best
> of conditions. I took a look at the DO macro and couldn't figure this
> out. Could you take a hard look at the DO macro and confirm that it
> is properly tail recursive. If it isn't, that would account for the
> leak here. I'd also check that the interpreter implements
> tail-recursive call correctly, though I'm pretty sure it does.
Here is a macro expander I wrote before some time (for never-completed
compiler for TS), that should expand macro fully:
(define (macro-expand-all form)
(define (symbol->macro? sym)
(macro?
(catch #f
(eval sym))))
(cond
((atom? form) form)
((and (symbol? (car form))
(symbol->macro? (car form))
(macro-expand-all (macro-expand form))))
(else
(map macro-expand-all form))))
It can help with further debugging...
> > First, how hard is to add ability to dump image from loaded coded? I
> > have a bit of Scheme code, loaded from couple of init-like files and
> > it takes some time to start either REPL or binaries linked with
> > TinyScheme. If you give me some pointers, I'll put it in my TS
> > 'fork' and provide a patch for those who are interested about this
> > feature.
> >
>
> I don't think it will help. When TS loads one of those init files, it
> simply forms a sequence of in-heap lists. There is no internal
> bytecode; TS interpretation proceeds directly from the "as a list"
> version of the original source code. So the only thing you would save
> here is the time to tokenize at load time.
>
> The thing is, you'd still have to tokenize the result of dump-heap,
> because it would get dumped out in a form that is very close to the
> original text. Most of the tokenization time is taken up recognizing
> atoms, and that would have to be done on re-load even from a dump
> file.
>
> Because of this, I think a better investment would be to work on
> speeding up the tokenizer implementation. The switch-case dispatch
> trick that is used in the TS implementation was very clever for the
> needs of the original implementation, which had a heavily constrained
> code space requirement. But the compiler cannot do much to optimize
> it.
>
> The most important optimization, I think, would be to split the
> implementation of READ into a general form and a filestream-specific
> form. The general form should test the stream type, and if it is a
> filestream it should call the specific implementation. The specific
> implementation can then inline the use of GET-CHAR, and a whole *lot*
> of speedup can be had there.
>
> Oh. Also need to check that the binding of GET-CHAR hasn't been
> changed. One problem with implementing scheme is that standard
> identifiers can be whacked by SET!.
I'll try to follow your pointers and hopefully comes up with something
faster.
> Well the obvious thing would be to check the respective default heap
> sizes. I'm not familiar with S7.
>
> At the risk of asking a dumb question, why not just use S7 if it's
> doing what you need?
It is not dumb for sure :) Well, I considered this option couple of
times, but code size (TS is about 5K, S7 around 60K), zipped in single
file, is a bit scary to get along with. Also, I get used with TS all
these years, including issues that comes with it...
> Jonathan
Best,
Sanel
|
|
From: Jonathan S. S. <sh...@er...> - 2014-01-03 19:01:23
|
On Fri, Jan 3, 2014 at 2:49 AM, Sanel Zukan <sa...@gm...> wrote: > On 01/01/14,Jonathan S. Shapiro wrote: > > If I were going to do a rework of that magnitude, I'd frankly be > > tempted to ditch call/cc in favor of exceptions as we discussed long > > ago. I'd be concerned about the impact of that on GIMP, though. > > Maybe this isn't very good option. Beside it will render TS as > uncompatible Scheme implementation, there are out some code which uses > call/cc; at least I have it used on some places. You are right. It isn't a good option. Let me describe the problem and give a better solution. The existence of first-class continuations, per se, isn't the problem. The problem is the existence of *reentrant* continuations (that is: continuations that can be called more than once). Reentrant continuations mean that an abandoned stack can be resurrected from below. This is a mess even from a pure scheme perspective. The interaction between CALL/CC and DYNAMIC-WIND is so complicated that R6RS must devote an entire appendix section to describing it (section A.10) in the formal small-step semantics ( http://www.r6rs.org/final/html/r6rs/r6rs-Z-H-2.html), and it still manages to leave it's higher-level semantics unspecified. New interactions with dynamic-wind are introduced in R6RS because they added exceptions to the language. But for TinyScheme there is a more immediate problem. It is possible for Scheme to call C, and for C in turn to call Scheme. This can leave you with a sequence that looks like: (define the-future nil) ... something that calls C ... [ C stack here ] ... something in C that calls Scheme ... [ Scheme stack here ] (begin (call/cc (lambda (re-enter-here) (set! the-future re-enter-here)) ... deep trouble: code that just returns normally ---) (the-future) The problem is that C has no concept that the stack can be re-entered from below. The scheme stack can be saved here. The C stack can't. There are hacks for the C stack that will work 80% of the time, but that's not good enough to use in a production scripting language. The bottom line is that *it isn't possible* to implement CALL/CC in compliance with the scheme specification. Worse, there is no easy way to distinguish survivable invocations to CALL/CC from non-survivable calls to CALL/CC. But if continuations are non-reentrant, the entire problem is eliminated. Historically, call/cc was introduced before formal semantics for control flow was well understood. I think it says something that *every single one* of the serious players in the world of programming language semantics has argued, compellingly, that [reentrant] first-class continuations are a bad idea. When I originally discussed this with Kevin many years ago, I suggested that we remove DYNAMIC-WIND and CALL/CC and replace them with an exception handling mechanism. Since that time, R6RS has done half the work for us by adding exception handling to the standard. For most programmers, RAISE and CATCH are much easier to understand than DYNAMIC-WIND and CALL/CC. The purpose of TinyScheme is to act as a scripting language, so ease of comprehension actually does matter. But in the years since that discussion, I've had a lot of time to think about and work on this same issue in BitC, and I now think that my proposal to Kevin was not the right way to proceed. A better approach is to make continuations non-reentrant by making them consume-on-use. Will Clinger did a pretty careful study at one point of every piece of scheme code he could track down. To first and second order, in real code, continuations are used solely for non-local return. The reentrancy capabilities of continuations are never used. That change is 99.44% compatible, and it wouldn't break any existing code. I think the best way to implement this would probably be with a self-modifying procedure object. CALL/CC creates one of these. When the procedure object is first invoked for non-local exit, the procedure object is modified by the interpreter to point to an internal procedure. The internal procedure, if it is ever invoked, prints a diagnostic that TinyScheme does not support reentrant continuations. The resulting implementation will be 99.44% compatible with existing use of TinyScheme, will eliminate the possibility of ugly surprises from the C stack, and preserves the spirit of Scheme. When die-hards complain, tell them we'll fix it when they can explain how to solve the C stack problem. Jonathan |
|
From: Sanel Z. <sa...@gm...> - 2014-01-08 00:36:25
|
n 01/03/14,Jonathan S. Shapiro wrote: > You are right. It isn't a good option. Let me describe the problem > and give a better solution. > > The existence of first-class continuations, per se, isn't the > [...] I shorten up a little bit so reply can be seen. Thanks for these very valuable informations! CALL/CC is still a bit black box for me, so I'll leave someone experienced to provide patch describing this technique. There are some patches floating around on TS bugtracker so I'm not sure are they full fixes CALL/CC issue or just something on by case basis... > Jonathan Best, Sanel |
|
From: Jonathan S. S. <sh...@er...> - 2014-01-03 19:11:25
|
On Fri, Jan 3, 2014 at 6:21 AM, Andrea Rossetti <and...@gm...>wrote: > Some more tests and your advice convinced me too > that DO is retaining some cells. Andrea: I *think* you can explicitly call (gc)? If so, try something like this: 1. Turn on gcverbose. 2. Run a big do loop over i printing i. Invoke (gc) explicitly when i == 1, i == 2, and i = 100000 See if the retained heap space grows. Kevin: if this reveals retention, I'm afraid I'm not likely to be able to debug the DO macro. Jonathan |
|
From: Andrea R. <and...@gm...> - 2014-01-04 16:38:30
|
"Jonathan S. Shapiro" <sh...@er...> writes:
> Andrea: I *think* you can explicitly call (gc)? If so, try something like
> this:
>
> 1. Turn on gcverbose.
> 2. Run a big do loop over i printing i. Invoke (gc) explicitly when i == 1,
> i == 2, and i = 100000
>
> See if the retained heap space grows.
>
Hello Jonathan,
I ran the proposed test, I did a (gc) when i == 0, 1, 99999.
Kindest regards, Andrea
---- test-shapiro-1.scm: OK (no "No memory!" messages) ------
(do ((i 0 (+ 1 i))) ((>= i 100000))
(write i) (newline)
(if (or (= i 0) (= i 1) (= i 99999))
(begin (gc-verbose #t) (gc) (gc-verbose #f))))
----- output produced is: -----------------------------------
0
gc...done: 9348 cells were recovered.
1
gc...done: 9348 cells were recovered.
2
3
...
...
99998
99999
gc...done: 9348 cells were recovered.
-------------------------------------------------------------
|
|
From: Andrea R. <and...@gm...> - 2014-01-04 17:11:48
|
Hello everyone again. I did another test involving only DO and nothing else, and I got the "No memory!" message. I think it's really the minimum-sized example we can get (i.e. seems to only happen when nesting DOs). Slightly off-topic note: I tried to make a graph of the "N cells were recovered" messages produced by (gc), see "run 2" below. A nice and bizarre saw-shaped pattern appeared, you may see it here: http://andrear.altervista.org/old/test-nested-do.png Kindest regards, Andrea ------------ test-nested-do.scm: prints "No memory!" ------- (do ((i 0 (+ 1 i))) ((>= i 20000)) (do ((j 0 (+ 1 j))) ((>= j 1)))) -------- run 1: without gc-verbose ------------------------- $ scheme test-nested-do.scm No memory! -------- run 2: with gc-verbose, get a PNG graph------------ $ scheme -c "(gc-verbose 1) (load \"test-nested-do.scm\")" \ | grep "^gc\.\.\.done:" \ | sed -e 's/[^0-9]//g' \ | gnuplot -e "set term png; set output 'test-nested-do.png'; plot '-' with lines; set output '-'; quit" No memory! |
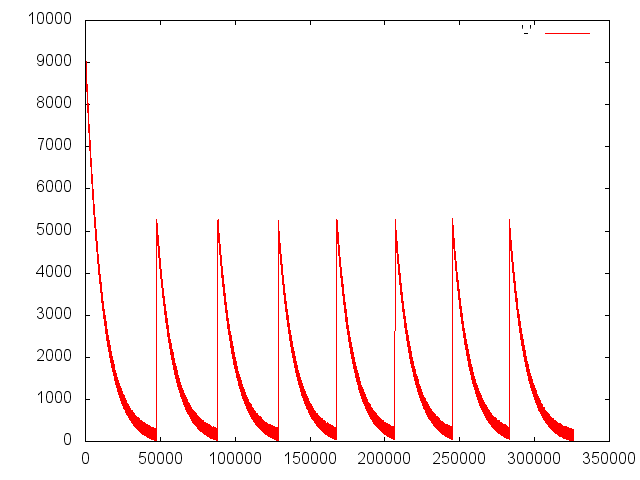{kind=link}
|
From: Jonathan S. S. <sh...@er...> - 2014-01-04 17:46:46
|
So it sounds like nested DO us the culprit. Yuck. Now we need to hand-expand the macros and whittle down from there unless Kevin has a better idea on how to go at this. |
|
From: Jonathan S. S. <sh...@er...> - 2014-01-04 17:56:55
|
Andrea: I should perhaps explain that I'm no longer really active on tinyscheme. I'm very happy to try to help you trace this down, and if we can get it down to something manageable I'll happily look at the code and see about a fix, but TS has been out of my head for years. I apologize that this is pushing the test burden back on you. Bottom line is that right now you are better able to do that than I am. Hopefully we'll find this in short order. |
|
From: Andrea R. <and...@gm...> - 2014-01-05 00:28:27
|
"Jonathan S. Shapiro" <sh...@er...> writes:
> I apologize that this is pushing the test burden back on you.
No problem, really; I'm happy if it helped
to at least restrict the search field.
There's another interesting thing I noticed:
the oblist grows linearly with the count of cycles
of the external DO; there are several symbols
named gensym-NNN. The oblist also grows by one
on a single non-nested DO.
Reproducible cases are shown in the interactive
sessions here below.
Kindest regards,
Andrea
------- interactive session 1 (nested DOs) ----------------
$ scheme
TinyScheme 1.41
ts> (write (length (oblist)))
383#t
ts> (do ((i 0 (+ 1 i))) ((>= i 10))
(do ((j 0 (+ 1 j))) ((>= j 1))))
()
ts> (write (length (oblist)))
395#t <---------------------------------------- oblist grew!
ts> (do ((i 0 (+ 1 i))) ((>= i 10))
(do ((j 0 (+ 1 j))) ((>= j 1))))
()
ts> (write (length (oblist)))
406#t <----------------------------------- oblist grew again!
ts> (gc)
#t
ts> (write (length (oblist)))
406#t <-------------------------------- gc could not recollect
ts> (quit)
------- interactive session 1 (plain DO) ----------------
$ scheme
TinyScheme 1.41
ts> (do ((i 0 (+ 1 i))) ((>= i 1)))
()
ts> (write (length (oblist)))
384#t
ts> (do ((i 0 (+ 1 i))) ((>= i 1)))
()
ts> (write (length (oblist)))
385#t
ts> (gc)
#t
ts> (write (length (oblist)))
385#t
ts> (quit)
|
Thanks for helping keep SourceForge clean.
X