A simple but complete full-attention transformer with a set of promising experimental features from various papers. Proposes adding learned memory key/values prior to attending. They were able to remove feedforwards altogether and attain a similar performance to the original transformers. I have found that keeping the feedforwards and adding the memory key/values leads to even better performance. Proposes adding learned tokens, akin to CLS tokens, named memory tokens, that is passed through the attention layers alongside the input tokens. You can also use the l2 normalized embeddings proposed as part of fixnorm. I have found it leads to improved convergence when paired with small initialization (proposed by BlinkDL). The small initialization will be taken care of as long as l2norm_embed is set to True.
Features
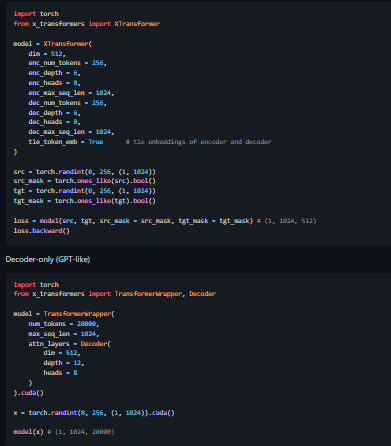
- Decoder-only (GPT-like)
- Encoder-only (BERT-like)
- State of the art image classification
- Augmenting Self-attention with Persistent Memory
- Transformers Without Tears
- Root Mean Square Layer Normalization
Project Samples