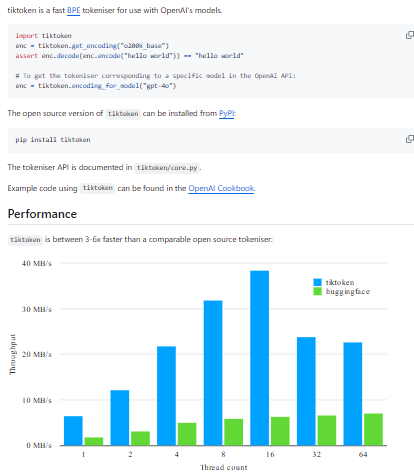
tiktoken is a high-performance, tokenizer library (based on byte-pair encoding, BPE) designed for use with OpenAI’s models. It handles encoding and decoding text to token IDs efficiently, with minimal overhead. Because tokenization is a fundamental step in preparing text for models, tiktoken is optimized for speed, memory, and correctness in model contexts (e.g. matching OpenAI’s internal tokenization). The repo supports multiple encodings (e.g. “cl100k_base”) and lets users switch encoding names to match different model contexts. It also offers extension mechanisms so that custom encodings can be registered. Internally, it includes the core tokenizer logic (often implemented in Rust or efficient lower-level code), APIs for encoding, decoding, and counting tokens, and binding layers to Python (and sometimes other languages) for easy use.
Features
- Fast BPE-based tokenizer for text ↔ token ID conversion
- Support for multiple encoding schemes (e.g. “cl100k_base”)
- APIs to encode, decode, and count tokens efficiently for prompt length control
- Extension / plugin mechanism for registering custom encodings
- Language bindings (Python / Rust / etc.) for integration in different environments
- Used for cost estimation, truncation logic, and alignment with OpenAI model expectations
Project Samples