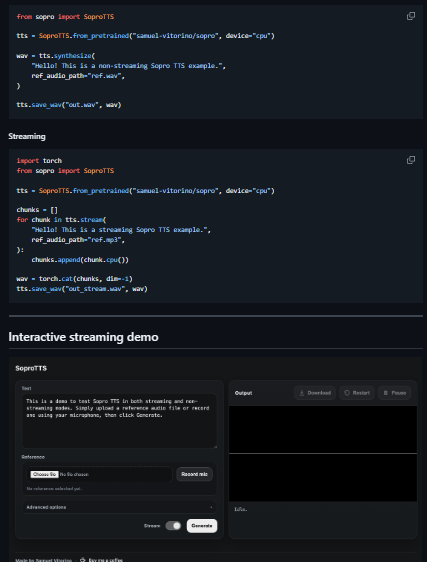
Sopro TTS is an open-source text-to-speech (TTS) project that implements a lightweight model capable of producing speech from text with zero-shot voice cloning, meaning it can mimic a speaker’s voice from only a few seconds of reference audio. Built with a 169 million-parameter architecture that uses dilated convolutions and cross-attention layers instead of large Transformer stacks, it achieves relatively fast real-time performance even on CPUs (about a 0.25 real-time factor measured on an M3 base). The model is designed to work with a small set of dependencies and to be accessible for developers who want offline TTS with customizable voice style, including options for streaming or non-streaming generation modes. Users can install it with standard Python tools, run a demo server locally, and experiment with CLI or Python API usage for producing synthetic speech.
Features
- English text-to-speech generation
- Zero-shot voice cloning from short reference audio
- Lightweight model (~169M parameters)
- Streaming and non-streaming modes
- CLI and Python API usage
- CPU-friendly real-time performance
Project Samples