Menu
▾
▴
user-mode-linux-devel
|
From: Chris L. <ch...@ex...> - 2005-10-08 16:32:20
|
At the moment, the performance of UBD is disappointing.
For instance, here is a trivial benchmark on a quiet and
reasonably modern P4 server with 3Ware 8xxx RAID (this is
linux 2.6.13.3, but I haven't spent any effort on tuning
the IO subsystem; in particular, the below results are for
the default, anticipatory, IO scheduler, but I don't
expect this choice to make much difference in this test
environment):
# time dd if=/dev/zero of=testfile bs=1M count=32
32+0 records in
32+0 records out
33554432 bytes transferred in 0.118687 seconds (282713683 bytes/sec)
real 0m0.120s
user 0m0.000s
sys 0m0.120s
# time rm testfile
real 0m0.027s
user 0m0.000s
sys 0m0.028s
... while the same experiment on a 2.6.13.3 UML kernel
(booting with parameters ubd0s=filesystem mem=128M)
running on the same hardware gives the following less
impressive results:
# time dd if=/dev/zero of=testfile bs=1M count=32
32+0 records in
32+0 records out
33554432 bytes transferred in 0.761825 seconds (44044809 bytes/sec)
real 0m0.770s
user 0m0.000s
sys 0m0.240s
# time rm testfile
real 1m20.808s
user 0m0.000s
sys 0m0.120s
(in this case the filesystem is from Debian `sarge', but
there's no reason this should make a significant
difference). Note that in both cases I've run the test
several times in order until the timings stabilise a bit.
Note that if you mount the host filesystem `sync' the
cost of creating the file rises a bit but the cost of
unlinking it doesn't change that much. Similarly if you
configure the UBD device without O_SYNC, things get a bit
quicker, but ``I like my data and I want to keep it'', so
this isn't an attractive option. (Though see my comment
about write barriers from earlier in the week.)
I should say also at this stage that no benchmark is
meaningful without context and the best benchmarks are
those which are based on a specific application which you
want to use a system to run. Equally I don't think that
the above pair of commands is an unreasonable thing to
expect to run reasonably swiftly on modern hardware, and
it's an interesting test case because the gap between host
and virtual machine performance is so large.
Matters can be improved a bit by rewriting the UBD code to
accept whole requests at once, use scatter/gather IO
(readv/writev) on the host, and allow there to be more
than one outstanding request at once. Here's a patch
against 2.6.12.5 which does this:
http://ex-parrot.com/~chris/tmp/20051008/ubd-sgio-2.6.12.5.patch
but note that it's very much a work-in-progress (it also
removes support for COW and isn't anywhere near
sufficiently well-tested for real use):
# time dd if=/dev/zero of=testfile bs=1M count=32
32+0 records in
32+0 records out
33554432 bytes transferred in 0.753967 seconds (44503843 bytes/sec)
real 0m0.763s
user 0m0.000s
sys 0m0.320s
# time rm testfile
real 0m1.026s
user 0m0.000s
sys 0m0.140s
Note that, while this comes closer to acceptable
performance, the rm is getting on for two orders of
magnitude slower than on the host.
Jeff Dike also has an AIO reimplementation of UBD in the
works, but I haven't had a chance to look at it yet.
I'm not really sure why this simple test is so slow. A
limitation of the existing UBD implementation is that it
issues requests to the host serially; Jeff's AIO
reimplementation will fix this, and I had a go at making
my implementation multithreaded (N threads submitting up
to N simultaneous IO operations to the host). In fact this
doesn't make a lot of difference to the above test, and
the concurrency is a bit messy (it makes the write
barriers case harder, in particular), so I haven't
investigated in detail.
Here is another simple test. The code in,
http://caesious.beasts.org/~chris/tmp/20051008/ioperformance.tar.gz
will issue random seeks and randomly-sized
reads/writes/synchronous writes against a file or block
device. This gives a measure of the effective seek time
and transfer rate of a block device (with or without an
overlying filesystem). Basic usage as follows:
# tar xzf ioperformance.tar.gz
# cd ioperformance
# make rate
# dd if=/dev/zero of=300M bs=1M count=300
# ./rate writesync 300 > results
[ ... this takes a little while... ]
that gives a text file whose first column is the size of
each IO operation and whose second column is its duration
of that operation. Obviously there will be a distribution
of durations for any given size of (in this case) write
operation, so there are two further scripts in the
distribution, bsmedian and bspercentile, which compute
respectively the median duration of operations of a given
size and the nth percentile points of the distribution for
each size. Here are some sample results, again comparing
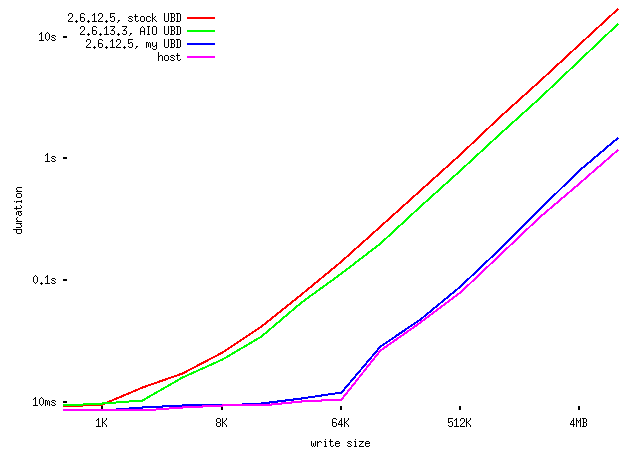
the host with 2.6.12.5 UML kernels:
http://ex-parrot.com/~chris/tmp/20051008/host-vs-uml-io-results.png
Note that while stock UBD in 2.6.12.5 is about an order of
magnitude slower than the host kernel for writes of any
significant size, a more effective implementation can
match the host's performance pretty well, which is as we
expect, since the cost of issuing the writes in UML is
pretty small compared to the actual cost of the disk
operations themselves. (As an aside, I don't really
understand the plateau in the curve above for writes of
smaller than 64KB. This may be an effect of stripe size in
the RAID array, but I'm not sure.)
Thoughts / comments?
--
Commitment can be best illustrated by a breakfast of ham and eggs.
The chicken was involved, the pig was committed. (unknown origin)
|
{kind=link}
|
From: Chris L. <ch...@ex...> - 2005-10-09 08:49:16
|
On Sat, Oct 08, 2005 at 05:32:10PM +0100, Chris Lightfoot wrote:
[...]
> ... while the same experiment on a 2.6.13.3 UML kernel
> (booting with parameters ubd0s=filesystem mem=128M)
> running on the same hardware gives the following less
> impressive results:
>
> # time dd if=/dev/zero of=testfile bs=1M count=32
> 32+0 records in
> 32+0 records out
> 33554432 bytes transferred in 0.761825 seconds (44044809 bytes/sec)
>
> real 0m0.770s
> user 0m0.000s
> sys 0m0.240s
> # time rm testfile
>
> real 1m20.808s
> user 0m0.000s
> sys 0m0.120s
>
> (in this case the filesystem is from Debian `sarge', but
> there's no reason this should make a significant
> difference). Note that in both cases I've run the test
> several times in order until the timings stabilise a bit.
So, the reason this is so slow is that if you do the
unlink immediately after the dd command completes, the IO
for the unlink has to wait until all of the IO for the dd
has been completed. While in principle that should be
pretty quick (and the timings from the dd confused me into
thinking it was) in fact under stock UBD those writes take
*minutes* to complete; the elapsed time for the unlink is
all spent waiting for the queue to drain. If you wait for
that to happen then do the unlink it takes a fraction of a
second, as expected.
--
``Is `colons' the plural of `semi-colon' if you know
you have an even number of them?'' (David Richerby)
|
|
From: Jeff D. <jd...@ad...> - 2005-10-09 18:52:49
|
On Sat, Oct 08, 2005 at 05:32:10PM +0100, Chris Lightfoot wrote: > Jeff Dike also has an AIO reimplementation of UBD in the > works, but I haven't had a chance to look at it yet. Why don't you look at UML with the AIO stuff applied? It's pretty certain that the one-at-a-time pseudo-AIO gives you close to synchronous performance when you have a lot of IO. The AIO work is intended to fix that, and if it doesn't, I like to know why. If you do want to play with the current stuff, I think you can wash out the effects of the pseudo-AIO stuff by slowing down the host and having it do symchronous I/O. If there is still a major difference between UML and the host, it would be interesting to know why. Jeff |
|
From: Chris L. <ch...@ex...> - 2005-10-09 22:51:48
|
On Sun, Oct 09, 2005 at 02:45:42PM -0400, Jeff Dike wrote:
> On Sat, Oct 08, 2005 at 05:32:10PM +0100, Chris Lightfoot wrote:
> > Jeff Dike also has an AIO reimplementation of UBD in the
> > works, but I haven't had a chance to look at it yet.
>
> Why don't you look at UML with the AIO stuff applied? It's pretty certain
> that the one-at-a-time pseudo-AIO gives you close to synchronous
> performance when you have a lot of IO. The AIO work is intended to
> fix that, and if it doesn't, I like to know why.
>
> If you do want to play with the current stuff, I think you can wash
> out the effects of the pseudo-AIO stuff by slowing down the host and
> having it do symchronous I/O. If there is still a major difference
> between UML and the host, it would be interesting to know why.
OK, here are the previous results comparing the AIO
implementation (using the code in the rc7 patches from
2005-08-26 and the ubd patches from 2005-09-17) with the
existing and my implementations:
http://ex-parrot.com/~chris/tmp/20051009/host-vs-uml-io-results-2.png
On this task (random seeks + random synchronous writes)
AIO helps a little bit but not very much.
(TBH I'm surprised that the AIO code shows so little
improvement. The kernel does report that it's using 2.6
host AIO, so it is using the new version. Obviously
issuing the writes segment-by-segment is non-ideal but I'm
surprised it's this bad. Could I be missing some
configuration step?)
--
``I won't let you in until you explain the ending of the movie.''
(unknown US immigration officer, to Arthur C. Clarke, 1969)
|
{kind=link}
|
From: Jeff D. <jd...@ad...> - 2005-10-10 01:42:20
|
On Sun, Oct 09, 2005 at 11:51:28PM +0100, Chris Lightfoot wrote: > (TBH I'm surprised that the AIO code shows so little > improvement. The kernel does report that it's using 2.6 > host AIO, so it is using the new version. Obviously > issuing the writes segment-by-segment is non-ideal but I'm > surprised it's this bad. Could I be missing some > configuration step?) Make sure you've got the o_direct patch, and are using a 4K block filesystem. If you're not doing O_DIRECT, then io_getevents waits - i.e. it's synchronous. Jeff |
|
From: Chris L. <ch...@ex...> - 2005-10-10 09:10:36
|
On Sun, Oct 09, 2005 at 09:35:15PM -0400, Jeff Dike wrote:
> On Sun, Oct 09, 2005 at 11:51:28PM +0100, Chris Lightfoot wrote:
> > (TBH I'm surprised that the AIO code shows so little
> > improvement. The kernel does report that it's using 2.6
> > host AIO, so it is using the new version. Obviously
> > issuing the writes segment-by-segment is non-ideal but I'm
> > surprised it's this bad. Could I be missing some
> > configuration step?)
>
> Make sure you've got the o_direct patch, and are using a 4K block filesystem.
>
> If you're not doing O_DIRECT, then io_getevents waits - i.e. it's synchronous.
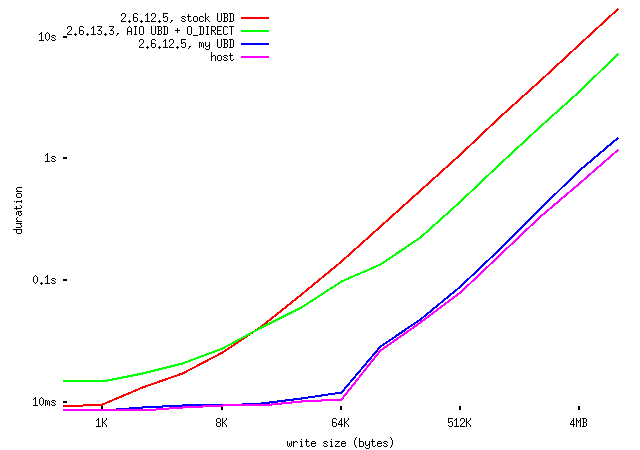
OK. The host is indeed using a 4K block filesystem; I
couldn't find your O_DIRECT patch, but turning on O_DIRECT
with fcntl just after opening the backing file gives these
results:
http://ex-parrot.com/~chris/tmp/20051010/host-vs-uml-io-results-3.png
i.e., the AIO implementation is now slower than the stock
implementation for writes of size up to about 8KB, but
faster for larger writes; it's still quite a bit slower
than the host.
--
Never has one man's death brought
so much pleasure to so many people (newspaper obituary of Stalin)
|
{kind=link}
|
From: Jeff D. <jd...@ad...> - 2005-10-10 14:45:29
|
On Mon, Oct 10, 2005 at 10:10:24AM +0100, Chris Lightfoot wrote: > OK. The host is indeed using a 4K block filesystem; I > couldn't find your O_DIRECT patch, but turning on O_DIRECT > with fcntl just after opening the backing file gives these > results: > http://ex-parrot.com/~chris/tmp/20051010/host-vs-uml-io-results-3.png > i.e., the AIO implementation is now slower than the stock > implementation for writes of size up to about 8KB, but > faster for larger writes; it's still quite a bit slower > than the host. There aren't very good labels on that graph, but it looks consistent with my experience, which is 25-30% faster kernel builds with AIO/O_DIRECT. The next question is where the slowdown is happening. Jeff |
|
From: Chris L. <ch...@ex...> - 2005-10-10 15:44:21
|
On Mon, Oct 10, 2005 at 10:38:03AM -0400, Jeff Dike wrote: > On Mon, Oct 10, 2005 at 10:10:24AM +0100, Chris Lightfoot wrote: > > OK. The host is indeed using a 4K block filesystem; I > > couldn't find your O_DIRECT patch, but turning on O_DIRECT > > with fcntl just after opening the backing file gives these > > results: > > http://ex-parrot.com/~chris/tmp/20051010/host-vs-uml-io-results-3.png > > i.e., the AIO implementation is now slower than the stock > > implementation for writes of size up to about 8KB, but > > faster for larger writes; it's still quite a bit slower > > than the host. > > There aren't very good labels on that graph, but it looks consistent with my > experience, which is 25-30% faster kernel builds with AIO/O_DIRECT. Not sure what additional labels you want, but here are the raw results (format as described previously): http://caesious.beasts.org/~chris/tmp/20051010/uml-2.6.12.5 http://caesious.beasts.org/~chris/tmp/20051010/uml-2.6.12.5-128M http://caesious.beasts.org/~chris/tmp/20051010/uml-2.6.12.5-newubd http://caesious.beasts.org/~chris/tmp/20051010/uml-2.6.13.3-aio http://caesious.beasts.org/~chris/tmp/20051010/uml-2.6.13.3-aio-direct http://caesious.beasts.org/~chris/tmp/20051010/host-2.6.13.3-skas3-v9-pre7-skas3-v7 http://caesious.beasts.org/~chris/tmp/20051010/host-cfq-2.6.13.3-skas3-v9-pre7-skas3-v7 -- names should be self-explanatory. > The next question is where the slowdown is happening. Well, it's got to be either O_DIRECT, aio, or breaking the requests up, I guess.... -- ``My years of hip-hop sessions came in handy as I could converse well with Fast Fingers. I knew the lingo and when to use it, and as far as he was concerned, I was one of the brothers. Strangely, neither of us was one of the brothers, but I figure that's just a technicality.'' (`MixerMan') |
×

Want the latest updates on software, tech news, and AI?
Get latest updates about software, tech news, and AI from SourceForge directly in your inbox once a month.
Thanks for helping keep SourceForge clean.
X