Menu
▾
▴
[[embed url=https://www.youtube.com/watch?v=PG9X9k7KXRo]]


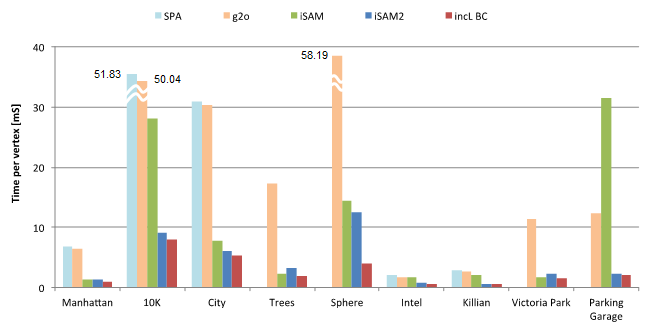
![Timing results on standard graph datasets, excerpt from the ICRA 2015 paper]
(https://sourceforge.net/p/slam-plus-plus/screenshot/slampp_eval_icra15_smf.png)
Home
SLAM++ 2.3 Released
A new version of SLAM++ was released. Online documentation is available. The new feature is an experimental incremental dogleg solver for fast bundle adjustment, as described in our 3DV 2017 paper.
SLAM++ 2.2 Release Candidate 4
This is a maintenance release, adding a few features such as robust cost functions, geometry and support for AVX family of instruction sets and a better support for ARM and NEON. Our benchmarks show up to 40% reduction in runtime for bundle adjustment problems (on x86_64 CPUs).
SLAM++ 2.1
A new release of SLAM++ just went public (download, documentation, online documentation)! Several new features are now integrated in SLAM++ 2.10. Those are showcased on the following examples:
- SLAM++ compact pose SLAM with data association examples - implements an algorithm which maintains a compact representation of the SLAM. This is based on calculating two measures: relative distance between poses weighted by uncertainty and mutual information of each edge. The algorithm also provides a scheme for loop closure detection. This is described in our newest paper. The below figures illustrate the differences between the full and compact solutions. We show that we can increase the speed without sacrificing much of the precision.
- BA parameterizations ACRA - tests several parameterization for the structure from motion estimation. Three types of point parameterization are implemented: euclidean coordinates, inverse depth and inverse distance. Points can also be represented in world coordinate or relative to a reference camera. Several camera vertex types are implemented: SE(3), SE(3) with calibration parameters and Sim(3) which integrates a scale parameter as well. This directly affects the convergence in the incremental solving; on the image below, this is easily seen (orange vertices have high magnitude of the update, green and blue vertices have low).
SLAM++ 2.0 Release Candidate
The new SLAM++ is here (download, documentation, online documentation)! It is backwards compatible and has some exciting new features:
- blazing-fast marginal covariance recovery. More details can be found here.
- added native support for hypergraphs (the current version supports hypergraphs, but does not contain any hypergraph edge implementations)
- improved Lambda solver for faster bundle adjustment
- support for GPU acceleration (experimental; need to enable that in CMake)
While the interface will not change, this version is a release candidate: some of the features planned for 2.0 are not included and we would like to include some more examples to make it easier for you to use. Keep an eye out for updates.
There was also recently a seminar on using SLAM++ held at BUT (video, slides).
ICRA 2015 Demos
Did you like the interactive poster at our booth at ICRA 2015 conference? Here you can download the source codes and windows binaries. This demo did compile on Windows using Visual Studio 2008, it should probably compile also on Linux / OS X but there is no makefile. You could use it for your own presentations, as the presentation is defined in declarative manner which is not entirely difficult to understand. Provided "as is".
SLAM++
SLAM++ is an efficient implementation of incremental nonlinear least squares solvers. It is written in C++ and it is very fast due to the fact that it exploits the block structure the problems and offers very fast solutions to manipulate block matrices within iterative nonlinear solvers. It currently depends on Eigen and on CSparse or CHOLMOD but we are working on making it more stand-alone.
The above figure shows time comparison on standard graph SLAM datasets (our implementation in red). It currently supports 2D and 3D datasets. These are incremental timings (update and solve every new variable), as this is where our implementation brings the advantage.
We are well and alive
In case you are wondering what is going on with SLAM++, and whether there will be a new version, you are in the right place. There are going to be new versions, and we are working on them non-stop (about 22 thousand new lines of code was written since the last release). The new version will be available as soon as our new papers are accepted for publication (especially ICRA 2015, HPC 2015). Some of the new features:
- blazing-fast marginal covariance recovery. More details can be found here.
- added native support for hypergraphs (the current version supports hypergraphs, but does not contain any hypergraph edge implementations)
- improved Lambda solver for faster bundle adjustment
- some ability to remove edges and vertices from the system
- constant vertices
- robust cost functions
- support for GPU acceleration
- we are developing a computer-vision frontend (which is OpenCV compatible but OpenCV-free, and will come with a plenty of cool demos)
The new version will be compatible with the existing code, so in the meanwhile you can just grab the source code and continue with the resources below.
If you just want to try it out, see compiling and running for the first time.
In case you are into 3D reconstruction or 3D SLAM, you can use our GraphViewer utility which we use for debugging and visualisation.
In case you wish to implement your custom problem solver, here is how.
We have tried SLAM++ on Raspberry Pi, here are some notes on that.
Check out the new online documentation. There is also a new page for simple SLAM++ example and for online example.
Do you have a very fast computer? Dare to participate in our speed challenge?
Did you ran into any problems? See our Help and FAQ.
Feeling bored? Check out our new C++ bug atlas, which describes cures for some of the less known compiler error messages!
ICRA 2013 Demos
Did you like the demos at our booth at ICRA 2013 conference? Here you can download TetriX or TetriX running upside down (used at the booth to keep the power cables away from the audience). These demos are only compatible with Android phones and tablets. Since these are not distributed through market, you will need to change settings on your mobile device to "allow installing applications from unknown sources".
Acknowledgements
The research leading to these results has received funding from the EU 7th FP, grants 316564-IMPART and 247772-SRS, Artemis JU grant 100233-R3-COP, and the IT4Innovations Centre of Excellence, grant n. CZ.1.05/1.1.00/02.0070, supported by Operational Programme Research and Development for Innovations funded by Structural Funds of the European Union and the state budget of the Czech Republic.
We publish
If you want to read more about what's going on in our library, you can read our papers. If you are publishing a work based on ours, please cite these. In case you would like to put a link to SLAM++ in your paper, you can use \footnote{\url{http://sf.net/p/slam-plus-plus/}}. Please, do not substitute citations of academic papers with the URL. Also, note that BibTeX changes case of words in publication names so one needs to put the word "SLAM" in curly braces as {SLAM}, otherwise it will typeset as "Slam".
V Ila, L Polok, M Solony and K Istenic, "Fast Incremental Bundle Adjustment with Covariance Recovery", proceedings of the International Conference on 3D Vision (3DV). Qingdao, China, 2017.
V Ila, L Polok, M Šolony and P Svoboda, "SLAM++. A Highly Efficient and Temporally Scalable Incremental SLAM Framework (arxiv.org)", International Journal of Robotics Research, 2017.
L Polok, V Ila and P. Smrž, "3D Reconstruction Quality Analysis and Its Acceleration on GPU Clusters," in proceedings of European Signal Processing Conference 2016. Budapest, 2016.
L Polok, V Lui, V Ila, T Drummond, R Mahony, "The Effect of Different Parameterisations in Incremental Structure from Motion," proceedings of the Australian Conference on Robotics and Automation, Australia, 2015.
L. Polok and P. Smrz, "Increasing Double Precision Throughput on NVIDIA Maxwell GPUs," proceedings of the 24th High Performance Computing Symposium, Pasadena / Los Angeles, USA, 2016.
S. Pabst, H. Kim, L. Polok, V. Ila, T. Waine, A. Hilton, J. Clifford and P. Smrz, "Jigsaw - Multi-Modal Big Data Management in Digital Film Production," SIGGRAPH (poster), Los Angeles, 2015.
L. Polok, S. Pabst, J. Clifford, "A GPU-Accelerated Bundle Adjustment Solver," GPU Technology Conference, 2015, San Diego, USA, 2015.
M. Solony, E. Imre, V. Ila, L. Polok, H. Kim and P. Zemcik, "Fast and Accurate Refinement Method for 3D Reconstruction from Stereo Spherical Images," proceedings of the 10th International Conference on Computer Vision Theory and Applications. Berlin: Institute of Electrical and Electronics Engineers, Germany, 2015.
V. Ila, L. Polok, M. Solony, P. Zemcik, P. Smrz, "Fast covariance recovery in incremental nonlinear least square solvers," proceedings of IEEE International Conference on Robotics and Automation (ICRA), Seatle, USA, 2015.
L. Polok, V. Ila, P. Smrz, "Fast Sparse Matrix Multiplication on GPU," 23rd High Performance Computing Symposia, Alexandria, USA, 2015
L. Polok, V. Ila, P. Smrz, "Fast Radix Sort for Sparse Linear Algebra on GPU," 22nd High Performance Computing Symposia, Tampa, USA, 2014
L. Polok, V. Ila, M. Solony, P. Smrz and P. Zemcik, "Incremental Block Cholesky Factorization for Nonlinear Least Squares in Robotics," in Proceedings of Robotics: Science and Systems 2013, MIT Press, 2013
L. Polok, M. Solony, V. Ila, P. Smrz and P. Zemcik, "Incremental Cholesky Factorization for Least Squares Problems in Robotics," in Proceedings of The 2013 IFAC Intelligent Autonomous Vehicles Symposium, IFAC, 2013.
L. Polok, M. Solony, V. Ila, P. Zemcik, and P. Smrz, "Efficient implementation for block matrix operations for nonlinear least squares problems in robotic applications," in Proceedings of the IEEE International Conference on Robotics and Automation, IEEE, 2013.
L. Polok, V. Ila and P. Smrz, "Cache Efficient Implementation for Block Matrix Operations," in Proceedings of the 21st High Performance Computing Symposia (HPC'13), SCS, 2013.
Project Admins:
Viorela Ila's homepage
Lukas Polok's homepage
