Menu
▾
▴
mingw-users
|
From: ralph e. <ral...@gm...> - 2012-07-31 06:52:54
|
Aye it does build though you might get some odd behaviour unless you tell it what terminal emulation to use and outside a posix environment that might be hard, though i suspect you could do it with a bat. Example: I can build dosbox with the internal debugger enabled on windows (uses curses) if i use pdcurses it works ok if i use ncurses it still works though the debugger window looks really strange unless i set term=console. Might be possible to hardcode it hmm ? but that kinda defeats the purpose. |
|
From: waterlan <wat...@xs...> - 2012-07-31 07:29:09
|
ralph engels schreef op 2012-07-31 08:52: > Aye it does build though you might get some odd behaviour unless you > tell it what terminal emulation to use and outside a posix > environment > that might be hard, though i suspect you could do it with a bat. > > Example: I can build dosbox with the internal debugger enabled on > windows (uses curses) > if i use pdcurses it works ok if i use ncurses it still works though > the > debugger window looks really strange > unless i set term=console. Might be possible to hardcode it hmm ? but > that kinda defeats the purpose. > So it builds, but there are problems during run time. Perhaps it is still a good idea to create mingw32 packages for ncurses 5.9 as it is now. Otherwise there will be a chicken egg problem. Because there are no pre-compiled packages the number of users is very small and also the problem reports. So problems won't get fixed. If there are patches available now, I'm happy to include them. I don't have time to debug ncurses myself. regards, -- Erwin Waterlander http://waterlan.home.xs4all.nl/ |
|
From: Thomas D. <di...@hi...> - 2012-07-31 08:37:34
Attachments:
signature.asc
|
On Mon, Jul 30, 2012 at 07:35:02PM +0200, Erwin Waterlander wrote: > Thomas Dickey schreef, Op 30-7-2012 11:38: > > On Mon, Jul 30, 2012 at 11:19:49AM +0200, waterlan wrote: > > > >> If you need Unicode support then your only choice is PDCurses at the > >> moment. > > As I read the code, some programs will behave differently. > > That's because PDCurses differs in the way it handles UTF-8 strings. > > Among other details, I didn't see anything to handle combining characters, > > or double-width cells. > > > > Hi, > > I think you are right. I see that combining characters are not displayed > correctly by pdcurses. I also don't see double width Chinese characters > displayed correctly, but that is also a font problem on my PC. > > How does ncursesw deal with surrogate pairs? I'm wondering, because I It "doesn't". That is, the code currently assumes that the runtime does this. Prompted by this thread and another recent comment, I started investigating the wide-character support on Windows last week. pdcurses essentially uses none of the runtime for supporting wide characters. I wasn't much surprised by that, and did a test-build to decide how I would fit in replacements for missing functions. Oddly there were no missing pieces - so my next step would be to setup proper testing and look for breakage. (this thread's provided me with a to-do list). > noticed that on Linux surrogate pairs are ignored by wcstombs() (leading > and trailing halves are converted individually). On Windows you may > encounter surrogate pairs, because wchar_t is 16 bit. > > regards, > > -- > Erwin Waterlander > http://waterlan.home.xs4all.nl/ > > > ------------------------------------------------------------------------------ > Live Security Virtual Conference > Exclusive live event will cover all the ways today's security and > threat landscape has changed and how IT managers can respond. Discussions > will include endpoint security, mobile security and the latest in malware > threats. http://www.accelacomm.com/jaw/sfrnl04242012/114/50122263/ > _______________________________________________ > MinGW-users mailing list > Min...@li... > > This list observes the Etiquette found at > http://www.mingw.org/Mailing_Lists. > We ask that you be polite and do the same. Disregard for the list etiquette may cause your account to be moderated. > > _______________________________________________ > You may change your MinGW Account Options or unsubscribe at: > https://lists.sourceforge.net/lists/listinfo/mingw-users > Also: mailto:min...@li...?subject=unsubscribe -- Thomas E. Dickey <di...@in...> http://invisible-island.net ftp://invisible-island.net |
|
From: Thomas D. <di...@hi...> - 2012-07-31 08:45:52
Attachments:
signature.asc
|
On Mon, Jul 30, 2012 at 05:31:57PM +0200, ralph engels wrote: > Latest ncurses source does build as unicode in Msys (version 5.9.0 i > think) but theres some weird stuff when console apps use it. While > pdcurses prints console output correctly the unicode version of ncurses > at default setting seems to > have some odd line dropouts. My best guess its because it needs > something to tell it what console emulation to use > like term=unicode etc. Also ncurses cannot be built as a shared library > on windows yet. well... There's really only one choice for the console emulation. As the readme says, it runs with TERM unset. I would expect to have to verify that the library should check if the window's codepage is one of the ones supporting Unicode or UTF-8 to be workable (and don't see this in pdcurses's source-code). so yes, it builds with the wide-character support, but the runtime needs some workarounds. There's also lots of interesting work past that already done in pdcurses. -- Thomas E. Dickey <di...@in...> http://invisible-island.net ftp://invisible-island.net |
|
From: waterlan <wat...@xs...> - 2012-07-31 14:45:28
|
Thomas Dickey schreef op 2012-07-31 10:45: > On Mon, Jul 30, 2012 at 05:31:57PM +0200, ralph engels wrote: > >> Latest ncurses source does build as unicode in Msys (version 5.9.0 i >> think) but theres some weird stuff when console apps use it. While >> pdcurses prints console output correctly the unicode version of >> ncurses >> at default setting seems to have some odd line dropouts. My best >> guess >> its because it needs something to tell it what console emulation to >> use >> like term=unicode etc. Also ncurses cannot be built as a shared >> library >> on windows yet. > > well... There's really only one choice for the console emulation. > As the readme says, it runs with TERM unset. > > I would expect to have to verify that the library should check if the > window's codepage is one of the ones supporting Unicode or UTF-8 to > be workable (and don't see this in pdcurses's source-code). You can output wide characters (Unicode UTF-16) in a Command Prompt regardless of the active code page if you use the proper Unicode win-api function. For instance WriteConsoleW() will always output wide chars correctly, no matter what the active code page is. The code pages only matter for all the non-wide ANSI (multi-byte) stuff. -- Erwin Waterlander http://waterlan.home.xs4all.nl/ |
|
From: Erwin W. <wat...@xs...> - 2012-08-02 16:48:00
|
Thomas Dickey schreef, Op 31-7-2012 10:45: > so yes, it builds with the wide-character support, but the runtime > needs some workarounds. There's also lots of interesting work past > that already done in pdcurses. Hi Thomas, You mean that it makes no sense at the moment to create a mingw32 release of ncurses*w* 5.9? We have to wait for 5.10? regards, -- Erwin Waterlander http://waterlan.home.xs4all.nl/ |
|
From: Roumen P. <bug...@ro...> - 2012-07-31 14:29:37
|
Mark Mikofski wrote: > [SNIP] > So not sure if ncurses can be built with mingw for windows? Yes. Another question is if ncurses run fine on windows . [SNIP] Roumen |
|
From: Eli Z. <el...@gn...> - 2012-07-31 16:01:27
|
> Date: Tue, 31 Jul 2012 07:49:35 +0200 > From: Erwin Waterlander <wat...@xs...> > > Eli Zaretskii schreef, Op 31-7-2012 4:51: > >> Date: Tue, 31 Jul 2012 01:17:04 +0200 > >> From: Erwin Waterlander<wat...@xs...> > >> > >>> I will try your port. > >>> > >> Eli, > >> I did not try it yet, are your changes needed? > > What changes? > > > > In your source package I see a file 'DIFFS'. I assumed this file > contains changes you made. That's right. I didn't try to build since then, so I don't know if anything was fixed. The changes are pretty self-explanatory, so I'm sure you can see for yourself if they are still needed. |
|
From: Eli Z. <el...@gn...> - 2012-07-31 16:12:49
|
> Date: Sun, 29 Jul 2012 13:35:10 +0300 > From: Roumen Petrov <bug...@ro...> > > Mark Mikofski wrote: > > [SNIP] > > > So not sure if ncurses can be built with mingw for windows? > Yes. > Another question is if ncurses run fine on windows . It does, at least the one I ported. I've run all the test programs that come with the distro, and they all work as expected. |
|
From: Eli Z. <el...@gn...> - 2012-07-31 16:18:52
|
> Date: Tue, 31 Jul 2012 16:45:16 +0200 > From: waterlan <wat...@xs...> > > Thomas Dickey schreef op 2012-07-31 10:45: > > You can output wide characters (Unicode UTF-16) in a Command Prompt > regardless of the active code page if you use the proper Unicode win-api > function. For instance WriteConsoleW() will always output wide chars > correctly, no matter what the active code page is. The code pages only > matter for all the non-wide ANSI (multi-byte) stuff. But if the current OEM codepage does not support some character (i.e. the font used doesn't have it), then how can WriteConsoleW produce this miracle? Won't you see question marks or blanks instead of those non-supported characters? Can you show an example program that writes to the console a wide string that includes characters from several non-trivial character blocks, and show how they are displayed when the OEM codepage is something mundane like 1252? |
|
From: Erwin W. <wat...@xs...> - 2012-07-31 18:48:12
|
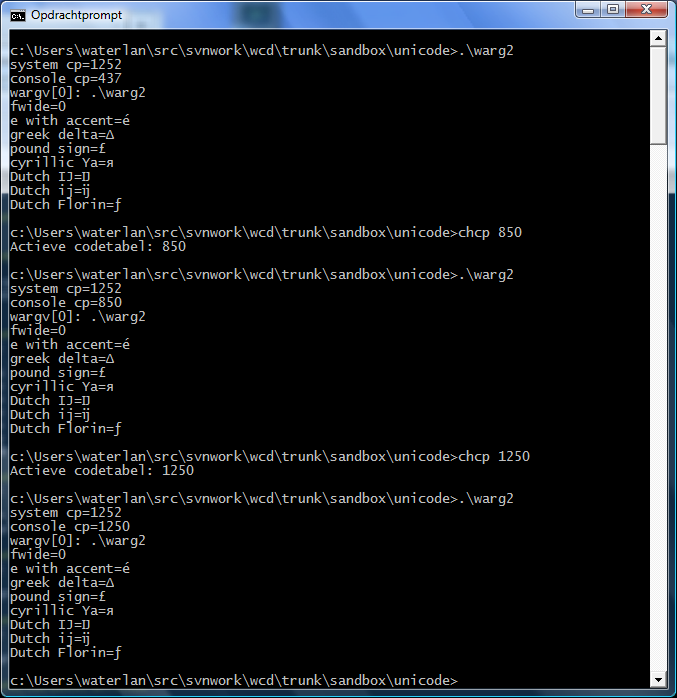
Eli Zaretskii schreef, Op 31-7-2012 18:17: >> Date: Tue, 31 Jul 2012 16:45:16 +0200 >> From: waterlan<wat...@xs...> >> >> Thomas Dickey schreef op 2012-07-31 10:45: >> >> You can output wide characters (Unicode UTF-16) in a Command Prompt >> regardless of the active code page if you use the proper Unicode win-api >> function. For instance WriteConsoleW() will always output wide chars >> correctly, no matter what the active code page is. The code pages only >> matter for all the non-wide ANSI (multi-byte) stuff. > But if the current OEM codepage does not support some character > (i.e. the font used doesn't have it), then how can WriteConsoleW > produce this miracle? Won't you see question marks or blanks instead > of those non-supported characters? I forgot to say that it works only if you select the proper TrueType font (like on every system, including Linux, the font has to support the characters you want to print). If you have your OEM code page set to 850 (which chcp) and your system ANSI code page to 1252 (via the Control Panel), then there is no problem printing accented characters or even Greek characters, provided you set the Command Prompt font to Lucida Console. Asian characters is a bit more trouble, because you have to set the system locale to an Asian locale before the Asian fonts become available in Windows Vista/7. (In Windows XP and before you have to post-install the Asian fonts). I did not try that, because I'm afraid I can't set the locale back any more ;) But for Asian people it should not a problem. > > Can you show an example program that writes to the console a wide > string that includes characters from several non-trivial character > blocks, and show how they are displayed when the OEM codepage is > something mundane like 1252? > 1252 is an ANSI code page. DOS programs (like edit) use the OEM code page which you can change with chcp. Windows programs, like notepad, use the system ANSI code page (change via Control Panel). Here is an example program: http://waterlan.home.xs4all.nl/unicode_example/ Here is the output in cmd.exe: http://waterlan.home.xs4all.nl/unicode_example/unicode_example.png regards, -- Erwin Waterlander http://waterlan.home.xs4all.nl/ |
|
From: Erwin W. <wat...@xs...> - 2012-07-31 19:07:54
|
Erwin Waterlander schreef, Op 31-7-2012 20:48: > Here is an example program: > http://waterlan.home.xs4all.nl/unicode_example/ Note that this program also takes Unicode input parameters, and prints them (regardless of the code page). You can try entering Unicode characters by using "Unicodeinput". See http://www.fileformat.info/tip/microsoft/enter_unicode.htm regards, -- Erwin Waterlander http://waterlan.home.xs4all.nl/ |
|
From: Eli Z. <el...@gn...> - 2012-07-31 19:27:20
|
> Date: Tue, 31 Jul 2012 20:48:01 +0200 > From: Erwin Waterlander <wat...@xs...> > > If you have your OEM code page set to 850 (which chcp) and your system > ANSI code page to 1252 (via the Control Panel), then there is no problem > printing accented characters or even Greek characters, provided you set > the Command Prompt font to Lucida Console. > > Asian characters is a bit more trouble, because you have to set the > system locale to an Asian locale before the Asian fonts become available > in Windows Vista/7. (In Windows XP and before you have to post-install > the Asian fonts). I did not try that, because I'm afraid I can't set the > locale back any more ;) But for Asian people it should not a problem. Well, maybe by Asia you mean Far East, in which case I will defer to your opinion. But for other Asian cultures, the best we have is Lucida, which is insufficient, as it covers only European stuff. > Here is an example program: > http://waterlan.home.xs4all.nl/unicode_example/ > > Here is the output in cmd.exe: > http://waterlan.home.xs4all.nl/unicode_example/unicode_example.png Thanks, this is revealing. AFAIU, WriteConsoleW bypasses the output codepage entirely, and needs only the font to support the characters that are being written. |
|
From: Erwin W. <wat...@xs...> - 2012-07-31 20:32:41
|
Eli Zaretskii schreef, Op 31-7-2012 21:26: > >> Here is an example program: >> > Thanks, this is revealing. AFAIU, WriteConsoleW bypasses the output > codepage entirely, and needs only the font to support the characters > that are being written. > > I'm not an experienced Windows programmer, but as far as I understand it the core of Windows NT (and the NTFS file system) is UTF-16 Unicode. The Win-Api provides wide-char Unicode (ending with W) and Ansi (ending with A) functions. The Ansi functions are just a layer on top of Unicode for backward compatibility. When translation is not possible your ansi program gets a question mark. If you use the Unicode functions you bypass the Ansi layer. Microsoft advises to use the Unicode functions. The Command Prompt fully supports Unicode. You can create files and directories with Unicode chars with the help of UnicodeInput. If you then type "dir" the file names are printed properly (with font Lucida). I think that in the long term the OEM code pages will go away with the last 32 bit Windows. The OEM code pages are now already unusable on 64 bit Windows, because you can't run DOS programs. Windows non-unicode console programs use the system ANSI code page. Powershell standardises on UTF-16. If you type 'echo hello > foo.txt', you will get a file foo.txt in UTF-16, regardless of the code page. At the time when MS chose to use UTF-16, UTF-8 was not in use yet. Unicode fitted in 16 bits, and all Linux distros where still 8 bit then. In the mean time Linux moved to UTF-8, and Unicode requires at least 21 bits. To support all Unicode characters with 16 bit wide chars, surrogate pair code points have been added to the Unicode spec. Correct me if I'm wrong. regards, -- Erwin Waterlander http://waterlan.home.xs4all.nl/ |
|
From: Jim M. <jmi...@ya...> - 2012-08-01 02:54:03
|
I don't know why this library is named curses - must be some sick joke. it's not descriptive. a side note: nobody likes curses or likes to be cursed, so it's just not appropriate for anyone. the name goes through my mind every time I have to deal with anything that contains this library, and frankly, I am tired of it. how about renaming libsurses and libpdcurses to libcursor, which gives a little more hint of what it does what it does and is still terse? if you don't mind something elongated but descriptive, how about libcursorcontrol or libcursorctrl? as a developer, I like names that are descriptive. just a friendly suggestion. Jim Michaels >________________________________ >From: Erwin Waterlander <wat...@xs...> >To: min...@li... >Sent: Tuesday, July 31, 2012 1:32 PM >Subject: Re: [Mingw-users] rename libpdcurses to libcurses? > >Eli Zaretskii schreef, Op 31-7-2012 21:26: >> >>> Here is an example program: >>> >> Thanks, this is revealing. AFAIU, WriteConsoleW bypasses the output >> codepage entirely, and needs only the font to support the characters >> that are being written. >> >> > >I'm not an experienced Windows programmer, but as far as I understand it >the core of Windows NT (and the NTFS file system) is UTF-16 Unicode. The >Win-Api provides wide-char Unicode (ending with W) and Ansi (ending >with A) functions. The Ansi functions are just a layer on top of Unicode >for backward compatibility. When translation is not possible your ansi >program gets a question mark. If you use the Unicode functions you >bypass the Ansi layer. Microsoft advises to use the Unicode functions. > >The Command Prompt fully supports Unicode. You can create files and >directories with Unicode chars with the help of UnicodeInput. If you >then type "dir" the file names are printed properly (with font Lucida). >I think that in the long term the OEM code pages will go away with the >last 32 bit Windows. The OEM code pages are now already unusable on 64 >bit Windows, because you can't run DOS programs. Windows non-unicode >console programs use the system ANSI code page. Powershell standardises >on UTF-16. If you type 'echo hello > foo.txt', you will get a file >foo.txt in UTF-16, regardless of the code page. > >At the time when MS chose to use UTF-16, UTF-8 was not in use yet. >Unicode fitted in 16 bits, and all Linux distros where still 8 bit then. >In the mean time Linux moved to UTF-8, and Unicode requires at least 21 >bits. To support all Unicode characters with 16 bit wide chars, >surrogate pair code points have been added to the Unicode spec. >Correct me if I'm wrong. > >regards, > >-- >Erwin Waterlander >http://waterlan.home.xs4all.nl/ > > >------------------------------------------------------------------------------ >Live Security Virtual Conference >Exclusive live event will cover all the ways today's security and >threat landscape has changed and how IT managers can respond. Discussions >will include endpoint security, mobile security and the latest in malware >threats. http://www.accelacomm.com/jaw/sfrnl04242012/114/50122263/ >_______________________________________________ >MinGW-users mailing list >Min...@li... > >This list observes the Etiquette found at >http://www.mingw.org/Mailing_Lists. >We ask that you be polite and do the same. Disregard for the list etiquette may cause your account to be moderated. > >_______________________________________________ >You may change your MinGW Account Options or unsubscribe at: >https://lists.sourceforge.net/lists/listinfo/mingw-users >Also: mailto:min...@li...?subject=unsubscribe > > > |
|
From: Earnie B. <ea...@us...> - 2012-08-01 13:51:07
|
On Tue, Jul 31, 2012 at 10:53 PM, Jim Michaels wrote: I have a gnawing in the back of my mind to set the moderation flag. DO NOT TOP POST and trim the fat. > I don't know why this library is named curses - must be some sick joke. it's > not descriptive. a side note: nobody likes curses or likes to be cursed, so > it's just not appropriate for anyone. the name goes through my mind every > time I have to deal with anything that contains this library, and frankly, I > am tired of it. > > how about renaming libsurses and libpdcurses to libcursor, which gives a > little more hint of what it does what it does and is still terse? if you > don't mind something elongated but descriptive, how about libcursorcontrol > or libcursorctrl? You will not receive support for this suggestion from MinGW. We only deliver a package from upstream maintainers and we don't have a problem with the name. A package developer is free to name his package whatever he chooses, even if it is to create a "sick joke", so you'll need to go back several years and probably a few decades to complain. -- Earnie -- https://sites.google.com/site/earnieboyd |
|
From: Konrad H. <ko...@pa...> - 2012-08-01 14:24:42
|
> -----Original Message----- > From: Earnie Boyd [mailto:ea...@us...] > Sent: Wednesday, August 01, 2012 8:51 AM > To: MinGW Users List > Subject: Re: [Mingw-users] rename libpdcurses to libcurses? > > On Tue, Jul 31, 2012 at 10:53 PM, Jim Michaels wrote: > > I have a gnawing in the back of my mind to set the moderation flag. > DO NOT TOP POST and trim the fat. > > > I don't know why this library is named curses - must be some sick joke. it's > > not descriptive. a side note: nobody likes curses or likes to be cursed, so > > it's just not appropriate for anyone. the name goes through my mind every > > time I have to deal with anything that contains this library, and frankly, I > > am tired of it. > > > > how about renaming libsurses and libpdcurses to libcursor, which gives a > > little more hint of what it does what it does and is still terse? if you > > don't mind something elongated but descriptive, how about libcursorcontrol > > or libcursorctrl? > > You will not receive support for this suggestion from MinGW. We only > deliver a package from upstream maintainers and we don't have a > problem with the name. A package developer is free to name his > package whatever he chooses, even if it is to create a "sick joke", so > you'll need to go back several years and probably a few decades to > complain. Yes. Curses has a long history -- in fact it was probably born before most of the people posting on this list. http://en.wikipedia.org/wiki/Ncurses -- kjh |
|
From: Erwin W. <wat...@xs...> - 2012-08-02 16:58:32
|
Thomas Dickey schreef, Op 31-7-2012 10:37: > On Mon, Jul 30, 2012 at 07:35:02PM +0200, Erwin Waterlander wrote: >> Thomas Dickey schreef, Op 30-7-2012 11:38: >>> As I read the code, some programs will behave differently. >>> That's because PDCurses differs in the way it handles UTF-8 strings. >>> Among other details, I didn't see anything to handle combining characters, >>> or double-width cells. >>> >> Hi, >> >> I think you are right. I see that combining characters are not displayed >> correctly by pdcurses. I also don't see double width Chinese characters >> displayed correctly, but that is also a font problem on my PC. >> >> How does ncursesw deal with surrogate pairs? I'm wondering, because I > It "doesn't". That is, the code currently assumes that the runtime > does this. Prompted by this thread and another recent comment, I > started investigating the wide-character support on Windows last week. > > pdcurses essentially uses none of the runtime for supporting wide characters. > I wasn't much surprised by that, and did a test-build to decide how I would > fit in replacements for missing functions. Oddly there were no missing > pieces - so my next step would be to setup proper testing and look for > breakage. (this thread's provided me with a to-do list). > I tried printing surrogate pairs with ncurses 5.9 on Cygwin in a mintty terminal. On Cygwin wchar_t is also 16 bit. It gave me only blanks. But this could also be a font problem. I don't know. -- Erwin Waterlander http://waterlan.home.xs4all.nl/ |
|
From: Andy K. <and...@gm...> - 2012-08-02 19:18:55
|
On 2 August 2012 17:58, Erwin Waterlander wrote: > Thomas Dickey schreef, Op 31-7-2012 10:37: >> On Mon, Jul 30, 2012 at 07:35:02PM +0200, Erwin Waterlander wrote: >>> Thomas Dickey schreef, Op 30-7-2012 11:38: >>>> As I read the code, some programs will behave differently. >>>> That's because PDCurses differs in the way it handles UTF-8 strings. >>>> Among other details, I didn't see anything to handle combining characters, >>>> or double-width cells. >>>> >>> Hi, >>> >>> I think you are right. I see that combining characters are not displayed >>> correctly by pdcurses. I also don't see double width Chinese characters >>> displayed correctly, but that is also a font problem on my PC. >>> >>> How does ncursesw deal with surrogate pairs? I'm wondering, because I >> It "doesn't". That is, the code currently assumes that the runtime >> does this. Prompted by this thread and another recent comment, I >> started investigating the wide-character support on Windows last week. >> >> pdcurses essentially uses none of the runtime for supporting wide characters. >> I wasn't much surprised by that, and did a test-build to decide how I would >> fit in replacements for missing functions. Oddly there were no missing >> pieces - so my next step would be to setup proper testing and look for >> breakage. (this thread's provided me with a to-do list). >> > > I tried printing surrogate pairs with ncurses 5.9 on Cygwin in a mintty > terminal. On Cygwin wchar_t is also 16 bit. It gave me only blanks. But > this could also be a font problem. I don't know. Fwiw, mintty does support surrogate pairs, as does Cygwin's C library. Font coverage can indeed be an issue, but, for example, pasting http://codepoints.net/U+20000 into mintty does display correctly on a Windows 7 system here with the font set to the default Lucida Console (whereby Windows' font linking automatically fills in holes using other fonts, probably SimSun-ExtB in this case). Also, some programs such as bash treat surrogate pairs as two characters, whereas others such as vim or emacs handle them correctly. Andy |
|
From: Thomas D. <di...@hi...> - 2012-08-02 23:42:32
Attachments:
signature.asc
|
On Thu, Aug 02, 2012 at 06:58:21PM +0200, Erwin Waterlander wrote: > Thomas Dickey schreef, Op 31-7-2012 10:37: > > On Mon, Jul 30, 2012 at 07:35:02PM +0200, Erwin Waterlander wrote: > >> Thomas Dickey schreef, Op 30-7-2012 11:38: > >>> As I read the code, some programs will behave differently. > >>> That's because PDCurses differs in the way it handles UTF-8 strings. > >>> Among other details, I didn't see anything to handle combining characters, > >>> or double-width cells. > >>> > >> Hi, > >> > >> I think you are right. I see that combining characters are not displayed > >> correctly by pdcurses. I also don't see double width Chinese characters > >> displayed correctly, but that is also a font problem on my PC. > >> > >> How does ncursesw deal with surrogate pairs? I'm wondering, because I > > It "doesn't". That is, the code currently assumes that the runtime > > does this. Prompted by this thread and another recent comment, I > > started investigating the wide-character support on Windows last week. > > > > pdcurses essentially uses none of the runtime for supporting wide characters. > > I wasn't much surprised by that, and did a test-build to decide how I would > > fit in replacements for missing functions. Oddly there were no missing > > pieces - so my next step would be to setup proper testing and look for > > breakage. (this thread's provided me with a to-do list). > > > > I tried printing surrogate pairs with ncurses 5.9 on Cygwin in a mintty > terminal. On Cygwin wchar_t is also 16 bit. It gave me only blanks. But > this could also be a font problem. I don't know. It's possible that the problem is simply that ncurses isn't dealing with surrogate pairs (I'll be looking into this, but do most of my ncurses work on the weekend - other programs generally get the weekdays). -- Thomas E. Dickey <di...@in...> http://invisible-island.net ftp://invisible-island.net |
|
From: Erwin W. <wat...@xs...> - 2012-08-03 06:14:31
|
Op 3-8-2012 1:42, Thomas Dickey schreef: > On Thu, Aug 02, 2012 at 06:58:21PM +0200, Erwin Waterlander wrote: >> Thomas Dickey schreef, Op 31-7-2012 10:37: >>> On Mon, Jul 30, 2012 at 07:35:02PM +0200, Erwin Waterlander wrote: >>>> Thomas Dickey schreef, Op 30-7-2012 11:38: >>>>> As I read the code, some programs will behave differently. >>>>> That's because PDCurses differs in the way it handles UTF-8 strings. >>>>> Among other details, I didn't see anything to handle combining characters, >>>>> or double-width cells. >>>>> >>>> Hi, >>>> >>>> I think you are right. I see that combining characters are not displayed >>>> correctly by pdcurses. I also don't see double width Chinese characters >>>> displayed correctly, but that is also a font problem on my PC. >>>> >>>> How does ncursesw deal with surrogate pairs? I'm wondering, because I >>> It "doesn't". That is, the code currently assumes that the runtime >>> does this. Prompted by this thread and another recent comment, I >>> started investigating the wide-character support on Windows last week. >>> >>> pdcurses essentially uses none of the runtime for supporting wide characters. >>> I wasn't much surprised by that, and did a test-build to decide how I would >>> fit in replacements for missing functions. Oddly there were no missing >>> pieces - so my next step would be to setup proper testing and look for >>> breakage. (this thread's provided me with a to-do list). >>> >> I tried printing surrogate pairs with ncurses 5.9 on Cygwin in a mintty >> terminal. On Cygwin wchar_t is also 16 bit. It gave me only blanks. But >> this could also be a font problem. I don't know. > It's possible that the problem is simply that ncurses isn't dealing > with surrogate pairs (I'll be looking into this, but do most of my > ncurses work on the weekend - other programs generally get the weekdays). > In UTF-8 format the characters print Okay in Cygwin when displayed with cat, less, or vim. So the font is Okay. Only when converted to wide chars, I get blanks with ncursesw. I tried mbstowcs() and MultiByteToWideChar() to convert the UTF-8 to wide chars. regards, -- Erwin Waterlander http://waterlan.home.xs4all.nl/ |
|
From: Thomas D. <di...@hi...> - 2012-08-02 23:45:44
Attachments:
signature.asc
|
On Thu, Aug 02, 2012 at 06:47:54PM +0200, Erwin Waterlander wrote: > Thomas Dickey schreef, Op 31-7-2012 10:45: > > so yes, it builds with the wide-character support, but the runtime > > needs some workarounds. There's also lots of interesting work past > > that already done in pdcurses. > > Hi Thomas, > > You mean that it makes no sense at the moment to create a mingw32 > release of ncurses*w* 5.9? We have to wait for 5.10? I'll probably be more focused on the mingw port (as I noted, had gotten interested in other areas, and only recalled that there were some issues with specific toolsets). Given the time since 5.9 (over a year ago), it's likely that I'll work til mingw wide-characters looks okay, and call _that_ 5.10. But you're free to sample the in-progress code to see if/when it looks useful for packaging. -- Thomas E. Dickey <di...@in...> http://invisible-island.net ftp://invisible-island.net |
|
From: Erwin W. <wat...@xs...> - 2012-08-03 06:19:24
|
Op 3-8-2012 1:45, Thomas Dickey schreef: > On Thu, Aug 02, 2012 at 06:47:54PM +0200, Erwin Waterlander wrote: >> Hi Thomas, >> >> You mean that it makes no sense at the moment to create a mingw32 >> release of ncurses*w* 5.9? We have to wait for 5.10? > I'll probably be more focused on the mingw port (as I noted, had > gotten interested in other areas, and only recalled that there were > some issues with specific toolsets). > > Given the time since 5.9 (over a year ago), it's likely that I'll > work til mingw wide-characters looks okay, and call _that_ 5.10. > But you're free to sample the in-progress code to see if/when it > looks useful for packaging. > I have also limited time... First I will work on a plain ncurses package. That helps already a lot of people. It will take some time. People who are in a hurry can use the package from ezwinports. regards, -- Erwin Waterlander http://waterlan.home.xs4all.nl/ |
|
From: Erwin W. <wat...@xs...> - 2012-08-03 08:13:32
|
Op 2-8-2012 21:18, Andy Koppe schreef: > Fwiw, mintty does support surrogate pairs, as does Cygwin's C library. Well, I know that libc's wcstombs() ignores them. I converts the UTF-16 surrogate halves individually to UTF-8. Some programs can read the resulting UTF-8, but others, including Windows Notepad, not. Perhaps this is a shortcoming of notepad. I don't know if it is legal in UTF-8 to have surrogate pairs individually encoded. Anyway, I worked around it in dos2unix by using WideCharToMultiByte() instead of wcstombs() with mingw32 and Cygwin. On Linux I decode the surrogate pair myself to a single UTF-32 character, before running wcstombs(). -- Erwin Waterlander http://waterlan.home.xs4all.nl/ |
|
From: <min...@sp...> - 2012-08-03 18:16:42
|
Erwin Waterlander - wat...@xs... wrote: > Op 2-8-2012 21:18, Andy Koppe schreef: >> Fwiw, mintty does support surrogate pairs, as does Cygwin's C library. > > Well, I know that libc's wcstombs() ignores them. I converts the UTF-16 > surrogate halves individually to UTF-8. Some programs can read the > resulting UTF-8, but others, including Windows Notepad, not. Perhaps > this is a shortcoming of notepad. I don't know if it is legal in UTF-8 > to have surrogate pairs individually encoded. Anyway, I worked around it > in dos2unix by using WideCharToMultiByte() instead of wcstombs() with > mingw32 and Cygwin. On Linux I decode the surrogate pair myself to a > single UTF-32 character, before running wcstombs(). It appears they're not valid UTF-8: http://en.wikipedia.org/wiki/UTF-8#Invalid_code_points > According to the UTF-8 definition (RFC 3629) the high and low > surrogate halves used by UTF-16 (U+D800 through U+DFFF) are not legal > Unicode values, and the UTF-8 encoding of them is an invalid byte > sequence and thus should be treated as described above. And the more official... http://tools.ietf.org/html/rfc3629#page-5 > The definition of UTF-8 prohibits encoding character numbers between > U+D800 and U+DFFF, which are reserved for use with the UTF-16 > encoding form (as surrogate pairs) and do not directly represent > characters. When encoding in UTF-8 from UTF-16 data, it is > necessary to first decode the UTF-16 data to obtain character > numbers, which are then encoded in UTF-8 as described above. This > contrasts with CESU-8 [CESU-8], which is a UTF-8-like encoding that > is not meant for use on the Internet. CESU-8 operates similarly to > UTF-8 but encodes the UTF-16 code values (16-bit quantities) instead > of the character number (code point). This leads to different > results for character numbers above 0xFFFF; the CESU-8 encoding of > those characters is NOT valid UTF-8. Mark. |

{kind=link}
Thanks for helping keep SourceForge clean.
X