Menu
▾
▴

MovPrefScraperTab
Movie Preferences - Scraper Tab
All Scraped data from either TheMovieDb or IMDB site is set on this tab. (Excluding artwork)
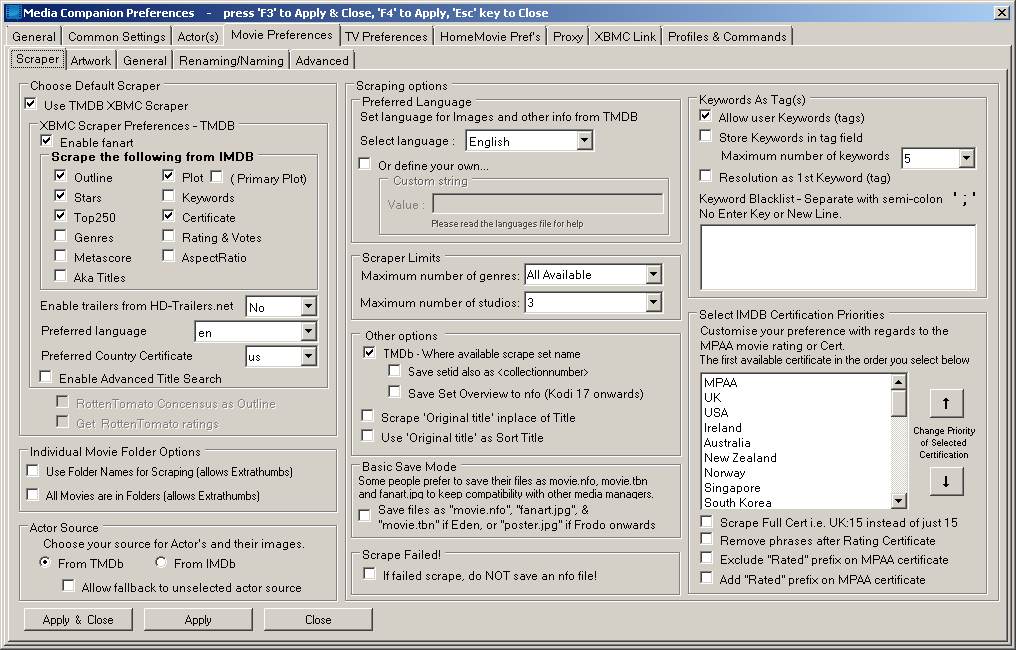
The first section of this tab is selecting the TMDB XBMC scraper, or leaving Media Companion to scrape data from IMDB and using Media Companions own TMBD API for other data.
The default is to use Media Companion’s default IMDB/TMBD scraper. Here users can set the IMDB Mirror, where to scrape Actor Images from and to only scrape primary plot from IMDB.
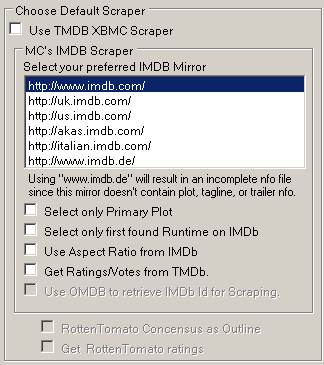
Or Users can select to use XBMC/Kodi TheMovieDB (TMDB) scraper. This scraper is the same as used by XBMC/Kodi, and kept updated. There are a couple of changes or additions to the TMDB Scraper, where we get all Countries, Studio’s and Writers instead of Kodi’s default single Country, Studio and Writer.
Also, User’s can select to get specific fields from IMDB. Stars, Votes, Top250, Rating etc.
And this is where users set their language, preferred certificate and if to download Actor images from TMDB.
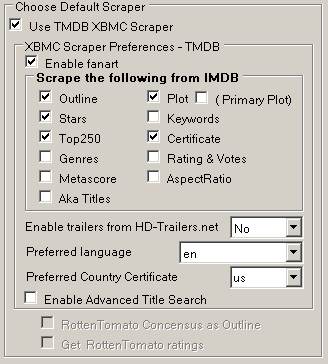
Note the option for scraping Rotten Tomato Concensus and Ratings.
This is only enabled once the user has applied and received a API Key from OMDB and inserted the key into Preferences -> Common tab.

Preferred language for Image artwork is selectable, or users can define their own language ID.
Also set the maximum Genres retrieved, and Studios
If Movies are in their own folders under the Root movie Folder, then selecting either Use Folder Names for scraping or All movies are in folders will allow the saving of ExtraThumbs.
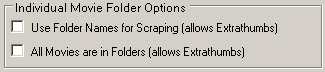
Use Folder Names for Scraping means Media Companion will take the Folder Title as the Movie’s Title and search accordingly. The Movie filename can be unique or set to something like Movie.<extn>. See option Basic Save Mode.
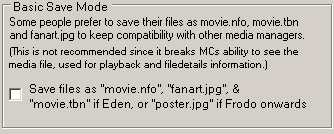
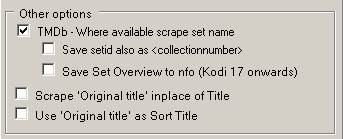
Scraping of Sets (collection) information is enabled here.
A custom option was added to also save the TMDB Set Id in <collectionnumber> tag in the nfo.
And Users of Kodi 16 and onwards (yes, image says Kodi 17, Typo in MC), to save the Set overview into the Nfo. Some Skins and movie layouts support displaying the overview for Sets.
Last option in this image is to choosing to scrape the Movie Title as the Original Title instead of known Title.
</collectionnumber>
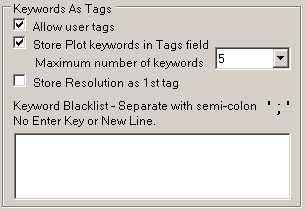
Saving of Keywords as Tag entries. Users can select as many tags as they wish, default is 5.
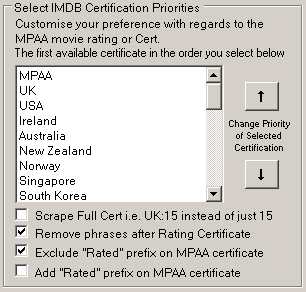
Here users can set their Certificate Rating priority. Top option is chosen first, but if not available, MC will continue down the list till we retrieve a Certification.
Extra options below the list is for users preferred visual result of the retrieved Certificate.
Finally, If the scrape fails, the user can allow or disallow the saving of the nfo. (default is unchecked
