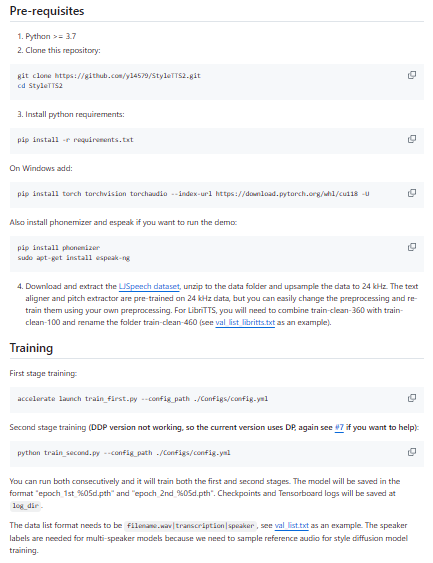
StyleTTS2 is a state-of-the-art text-to-speech system that aims for human-level naturalness by combining style diffusion, adversarial training, and large speech language models. It extends the original StyleTTS idea by introducing a style diffusion model that can sample rich, realistic speaking styles conditioned on reference speech, allowing highly expressive and diverse prosody. The architecture uses a two-stage training process and leverages an auxiliary speech language model to guide generation toward more natural and coherent utterances. StyleTTS2 supports both single-speaker and multi-speaker configurations, with the ability to sample or transfer styles from reference audio, making it powerful for expressive TTS and character voices. The repository includes training scripts, configuration files, and pre-trained auxiliary modules such as a text aligner, pitch extractor, and PL-BERT-based linguistic encoder.
Features
- Style diffusion-based TTS architecture targeting human-level naturalness
- Two-stage training pipeline with adversarial training guided by a speech language model
- Supports style transfer from reference audio and multi-speaker modeling
- Pre-trained text aligner, pitch extractor, and PL-BERT modules included for easier setup
- Configurable for multiple languages by swapping in language-specific or multilingual PL-BERT models
- Fine-tuning scripts and configs to adapt the model with relatively small custom datasets
Project Samples