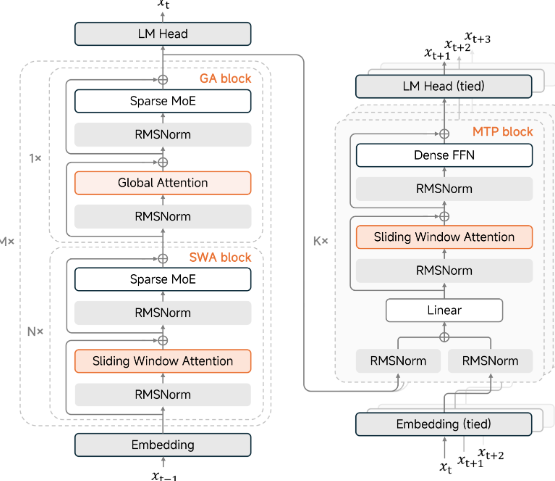
MiMo-V2-Flash is a large Mixture-of-Experts language model designed to deliver strong reasoning, coding, and agentic-task performance while keeping inference fast and cost-efficient. It uses an MoE setup where a very large total parameter count is available, but only a smaller subset is activated per token, which helps balance capability with runtime efficiency. The project positions the model for workflows that require tool use, multi-step planning, and higher throughput, rather than only single-turn chat. Architecturally, it highlights attention and prediction choices aimed at accelerating generation while preserving instruction-following quality in complex prompts. The repository typically serves as a launch point for running the model, understanding its intended use cases, and reproducing or extending its evaluation on reasoning and agent-style tasks. In short, MiMo-V2-Flash targets the “high-speed, high-competence” lane for modern LLM applications.
Features
- Mixture-of-Experts design for efficient high-capacity inference
- Optimised for reasoning-heavy and coding-oriented workloads
- Built for agentic workflows including planning and tool use patterns
- Multi-token prediction style to improve throughput per step
- Scales across deployment modes from local to server inference
- Repository guidance for running, testing, and evaluating the model
Project Samples