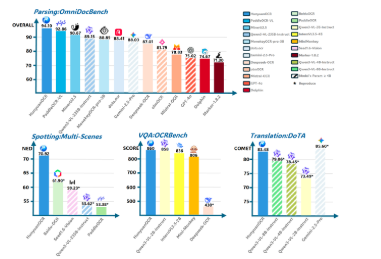
HunyuanOCR is an open-source, end-to-end OCR (optical character recognition) Vision-Language Model (VLM) developed by Tencent‑Hunyuan. It’s designed to unify the entire OCR pipeline, detection, recognition, layout parsing, information extraction, translation, and even subtitle or structured output generation, into a single model inference instead of a cascade of separate tools. Despite being fairly lightweight (about 1 billion parameters), it delivers state-of-the-art performance across a wide variety of OCR tasks, outperforming many traditional OCR systems and even other multimodal models on benchmark suites. HunyuanOCR handles complex documents: multi-column layouts, tables, mathematical formulas, mixed languages, handwritten or stylized fonts, receipts, tickets, and even video-frame subtitles. The project provides code, pretrained weights, and inference instructions, making it feasible to deploy locally or on a server, and to integrate with applications.
Features
- End-to-end OCR Vision-Language Model: detection, recognition, layout parsing, translation, and structured output generation in a single inference pass
- Lightweight (~1 billion parameters) yet achieves state-of-the-art performance across benchmarks for complex documents, multilingual text, handwritten/stylized fonts, receipts, tickets, and more
- Supports complex layouts including columns, tables, formulas, multi-language text, mixed fonts/styles, and video subtitles/frames
- Produces structured outputs (e.g., JSON, HTML, Markdown, LaTeX, translated text), enabling downstream processing like automated form filling or data extraction
- Open-source with code, pretrained weights and inference scripts — easy to integrate locally or in production workflows
- Efficient inference pipeline (via a native-resolution encoder + adaptive visual adapter + light LLM), lowering computational cost compared to massive models
Project Samples