Steem Ruby Tutorial Wiki
Brought to you by:
krischik
All examples from this tutorial can be found as fully functional scripts on GitHub:
This tutorial shows how to interact with the Steem blockchain and Steem database using Ruby. When using Ruby you have three APIs available to chose: steem-api, steem-mechanize and radiator which differentiates in how return values and errors are handled:
This tutorial takes a special look at the steem-mechanize API.
Basic knowledge of Ruby programming is needed. It is necessary to install at least Ruby 2.5 as well as the following ruby gems:
gem install bundler
gem install colorize
gem install contracts
gem install steem-mechanize
Note: All APIs steem-ruby, steem-mechanize and radiator provide a file called steem.rb. This means that:
If there is anything not clear you can ask in the comments.
For reader with programming experience this tutorial is basic level.
Printing all delegation from and to a list of accounts, as shown in the last tutorial, hast proven to be a time consuming operation — easily lasting over an hour.
On way to improve performance is to skip over the delegations of the “steem” account who delegates to most accounts below a steem power of ≈30000 VEST / 15 STEEM. This brings the run time down to about half an hour. Which is still a lot.
Another way to improve performance is the use of steem-mechanize a combination of steem-ruby and mechanize. Mechanize improved performance by using Persistent HTTP connections.
steem-mechanize is a drop in replacement for steem-ruby and theoretically the only change to the code needed is the use of require 'steem-mechanize' instead require 'steem-ruby'.
# use the "steem.rb" file from the steem-ruby gem. This is
# only needed if you have both steem-api and radiator
# installed.
gem "steem-ruby", :require => "steem"
require 'pp'
require 'colorize'
require 'steem-mechanize'
# The Amount class is used in most Scripts so it was moved
# into a separate file.
require_relative 'Steem/Amount'
However in praxis there is one more Problem: steem-mechanize is to fast for https://api.steemit.com and you will be get an “Error 403” / “HTTP Forbidden” if you try.
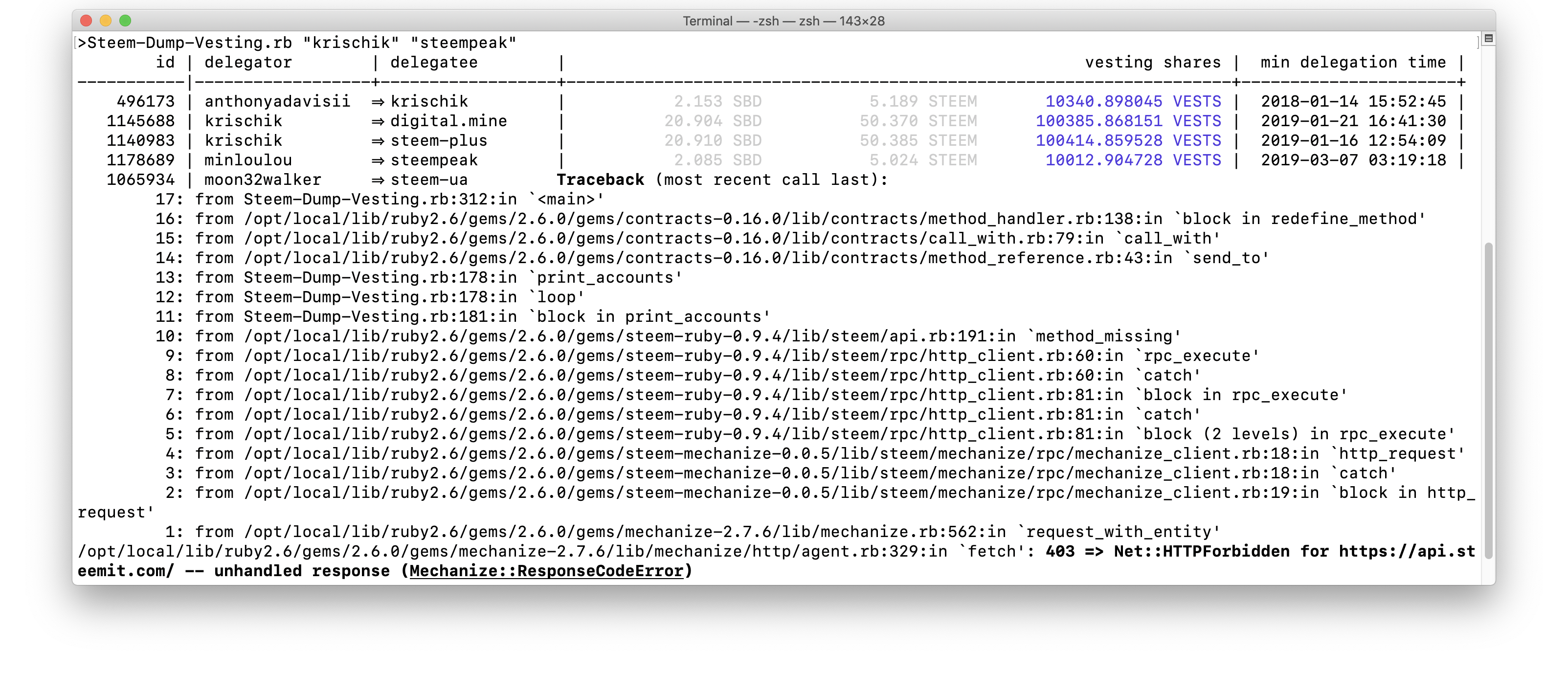
This suggest that Steemit has an upper limit on how many the accesses per seconds it allows which makes it necessary to add additional error handling and a little sleep. To avoid duplication only the differences to the original version is shown.
At the beginning of the file a constant indicating the maximum retries to be done.
##
# Maximum retries to be done when a
#
Max_Retry_Count = 3
At the beginning of the main loop a retry counter is added.
# empty strings denotes start of list
_previous_end = ["", ""]
# counter keep track of the amount of retries left
_retry_count = Max_Retry_Count
loop do
At then end of the loop a sleep is added to throttle the loop to 20 http requests per second. Test have shown that this is usually enough to make the loop run though.
For the few cases where throttling is not sufficient an error handler is added to allow up to three (Max_Retry_Count) retries.
# Throttle to 20 http requests per second. That
# seem to be the acceptable upper limit for
# https://api.steemit.com
sleep 0.05
# resets the counter that keeps track of the
# retries.
_retry_count = Max_Retry_Count
rescue => error
if _retry_count == 0 then
# We made Max_Retry_Count repeats ⇒ giving up.
print Delete_Line
Kernel::abort ("\nCould not read %1$s with %2$d retrys :\n%3$s".red) % [_previous_end, Max_Retry_Count, error.to_s]
end
# wait one second before making the next retry
_retry_count = _retry_count - 1
sleep 1.0
end
Hint: Follow this link to Github for the complete script with comments and syntax highlighting: Steem-Dump-Vesting.rb.
The output of the command (for my own and the steem account) looks just like before:
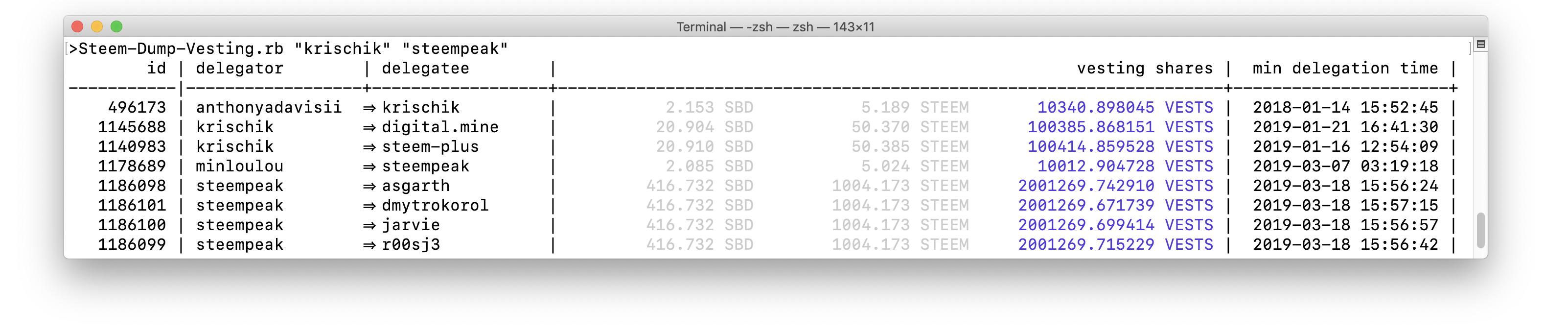
However it steem-mechanize version is just about 2½ faster:
| API used | Time elapsed |
|---|---|
| steem-ruby | 27'58" |
| steem-mechanize | 11'49" |

