sqlalchemy-tickets Mailing List for SQLAlchemy (Page 26)
Brought to you by:
zzzeek
You can subscribe to this list here.
| 2006 |
Jan
|
Feb
|
Mar
(174) |
Apr
(50) |
May
(71) |
Jun
(129) |
Jul
(113) |
Aug
(141) |
Sep
(82) |
Oct
(142) |
Nov
(97) |
Dec
(72) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2007 |
Jan
(159) |
Feb
(213) |
Mar
(156) |
Apr
(151) |
May
(58) |
Jun
(166) |
Jul
(296) |
Aug
(198) |
Sep
(89) |
Oct
(133) |
Nov
(150) |
Dec
(122) |
| 2008 |
Jan
(144) |
Feb
(65) |
Mar
(71) |
Apr
(69) |
May
(143) |
Jun
(111) |
Jul
(113) |
Aug
(159) |
Sep
(81) |
Oct
(135) |
Nov
(107) |
Dec
(200) |
| 2009 |
Jan
(168) |
Feb
(109) |
Mar
(141) |
Apr
(128) |
May
(119) |
Jun
(132) |
Jul
(136) |
Aug
(154) |
Sep
(151) |
Oct
(181) |
Nov
(223) |
Dec
(169) |
| 2010 |
Jan
(103) |
Feb
(209) |
Mar
(201) |
Apr
(183) |
May
(134) |
Jun
(113) |
Jul
(110) |
Aug
(159) |
Sep
(138) |
Oct
(96) |
Nov
(116) |
Dec
(94) |
| 2011 |
Jan
(97) |
Feb
(188) |
Mar
(157) |
Apr
(158) |
May
(118) |
Jun
(102) |
Jul
(137) |
Aug
(113) |
Sep
(104) |
Oct
(108) |
Nov
(91) |
Dec
(162) |
| 2012 |
Jan
(189) |
Feb
(136) |
Mar
(153) |
Apr
(142) |
May
(90) |
Jun
(141) |
Jul
(67) |
Aug
(77) |
Sep
(113) |
Oct
(68) |
Nov
(101) |
Dec
(122) |
| 2013 |
Jan
(60) |
Feb
(77) |
Mar
(77) |
Apr
(129) |
May
(189) |
Jun
(155) |
Jul
(106) |
Aug
(123) |
Sep
(53) |
Oct
(142) |
Nov
(78) |
Dec
(102) |
| 2014 |
Jan
(143) |
Feb
(93) |
Mar
(35) |
Apr
(26) |
May
(27) |
Jun
(41) |
Jul
(45) |
Aug
(27) |
Sep
(37) |
Oct
(24) |
Nov
(22) |
Dec
(20) |
| 2015 |
Jan
(17) |
Feb
(15) |
Mar
(34) |
Apr
(55) |
May
(33) |
Jun
(31) |
Jul
(27) |
Aug
(17) |
Sep
(22) |
Oct
(26) |
Nov
(27) |
Dec
(22) |
| 2016 |
Jan
(20) |
Feb
(24) |
Mar
(23) |
Apr
(13) |
May
(17) |
Jun
(14) |
Jul
(31) |
Aug
(23) |
Sep
(24) |
Oct
(31) |
Nov
(23) |
Dec
(16) |
| 2017 |
Jan
(24) |
Feb
(20) |
Mar
(27) |
Apr
(24) |
May
(28) |
Jun
(18) |
Jul
(18) |
Aug
(23) |
Sep
(30) |
Oct
(17) |
Nov
(12) |
Dec
(12) |
| 2018 |
Jan
(27) |
Feb
(23) |
Mar
(13) |
Apr
(19) |
May
(21) |
Jun
(29) |
Jul
(11) |
Aug
(22) |
Sep
(14) |
Oct
(9) |
Nov
(24) |
Dec
|
|
From: Mike B. <iss...@bi...> - 2016-06-01 21:17:39
|
New issue 3720: add TABLESPACE to Index for Postgresql https://bitbucket.org/zzzeek/sqlalchemy/issues/3720/add-tablespace-to-index-for-postgresql Mike Bayer: this would complement TABLESPACE for Table as implemented in #2051. |
|
From: Julius Y. <iss...@bi...> - 2016-05-28 00:33:12
|
New issue 3719: behavior of declared_attr and column_property in a mixin doesn't correspond with documentation https://bitbucket.org/zzzeek/sqlalchemy/issues/3719/behavior-of-declared_attr-and Julius Yang: I'm trying to make this example work: http://docs.sqlalchemy.org/en/rel_1_0/orm/extensions/declarative/mixins.html#mixing-in-deferred-column-property-and-other-mapperproperty-classes This code returns None instead of the expected 15. ``` #!python from sqlalchemy import Column, create_engine, Integer from sqlalchemy.ext.declarative import declarative_base, declared_attr from sqlalchemy.orm import column_property engine = create_engine('sqlite://') Base = declarative_base(engine) class SomethingMixin(object): x = Column(Integer) y = Column(Integer) @declared_attr def x_plus_y(cls): return column_property(cls.x + cls.y) class Something(SomethingMixin, Base): __tablename__ = "something" id = Column(Integer, primary_key=True) foo = Something() foo.x = 10 foo.y = 5 print foo.x_plus_y ``` I'm using SQLAlchemy 1.0.13. My use case: I have several classes with a latitude and longitude coordinate which I want to represent as a geoalchemy2 WKBElement internally, but as lat/long floats externally, so a getter on the mixin needs to convert. |
|
From: Tim J. D. <iss...@bi...> - 2016-05-26 22:30:16
|
New issue 3718: No support for the TABLESAMPLE clause (SQL 2003 / PostgreSQL) https://bitbucket.org/zzzeek/sqlalchemy/issues/3718/no-support-for-the-tablesample-clause-sql Tim Joseph Dumol: There doesn't seem to be any built-in support for the TABLESAMPLE clause (searched docs and asked on SO [3]). [1] https://www.postgresql.org/docs/9.5/static/sql-select.html [2] http://users.atw.hu/sqlnut/sqlnut2-chp-1-sect-2.html [3] https://stackoverflow.com/questions/37429476/how-to-tablesample-with-sqlalchemy |
|
From: Whitney Y. <iss...@bi...> - 2016-05-23 23:51:52
|
New issue 3717: Subquery loading fails to load all objects when through a joinedload https://bitbucket.org/zzzeek/sqlalchemy/issues/3717/subquery-loading-fails-to-load-all-objects Whitney Young: Given the following relations: - `Company` has many `employees` and a `parent` company - `Employee` has an `employer` And the following instances: - Apple w/ employees Tim Cook & Jony Ive - Beats w/ employees Dr. Dre & Jimmy Iovine The following query does not load everything: ```python employees = session.query(Employee).options( joinedload('employer').joinedload('parent').subqueryload('employees') ).filter().all() ``` It appears that it finds all employees and parents properly, but since all the companies get loaded into the session via the joined load, it seems to stop processing at this point and doesn't actually perform the subqueryload of `employees`. This example may seem contrived since it's circling back around through the relationships, but it's a simplified version of something that w/ filters applied is a very real query in our system. Below is some code to run to show the problem. Just change the connection string to be able to connect to your database, the code will populate a few records for you. ```python import logging from contextlib import contextmanager from sqlalchemy import ( Column, ForeignKey, Integer, MetaData, String, Table, create_engine, inspect, ) from sqlalchemy.orm import ( mapper, relationship, sessionmaker, subqueryload, joinedload, ) class Model(object): def __init__(self, **kwargs): for key, value in kwargs.items(): setattr(self, key, value) class Company(Model): pass class Employee(Model): pass engine = create_engine( 'mysql+pymysql://root:password@localhost/test?charset=utf8mb4', convert_unicode=True, ) metadata = MetaData(bind=engine) Session = sessionmaker(bind=engine) company_table = Table( 'companies', metadata, Column('id', Integer, primary_key=True, autoincrement=True), Column('name', String(255)), Column('parent_id', Integer, ForeignKey('companies.id')), ) employee_table = Table( 'employees', metadata, Column('id', Integer, primary_key=True, autoincrement=True), Column('name', String(255)), Column('employer_id', Integer, ForeignKey('companies.id')), ) company_mapper = mapper(Company, company_table, properties={ 'parent': relationship( Company, uselist=False, remote_side=[company_table.columns.id], ), 'employees': relationship( Employee, uselist=True, back_populates='employer', ), }) employee_mapper = mapper(Employee, employee_table, properties={ 'employer': relationship( Company, uselist=False, back_populates='employees', ) }) connection = engine.connect() metadata.create_all(connection) connection.close() @contextmanager def session_manager(): session = Session() try: yield session; session.commit() except: session.rollback(); raise finally: session.close() def _ensure_loaded(obj, key_path): components = key_path.split('.') for i, key in enumerate(components): if key in inspect(obj).unloaded: raise AttributeError('Attribute {} not loaded during query'.format( '.'.join(components[:i+1]) )) obj = getattr(obj, key) if obj is None: break models = [ Company(id=1, name='Apple'), Company(id=2, name='Beats', parent_id=1), Employee(id=1, name='Tim Cook', company_id=1), Employee(id=2, name='Jony Ive', company_id=1), Employee(id=3, name='Dr. Dre', company_id=2), Employee(id=4, name='Jimmy Iovine', company_id=2), ] for model in models: with session_manager() as session: try: session.add(model) session.commit() except Exception as e: session.close() logging.basicConfig() logging.getLogger('sqlalchemy.engine').setLevel(logging.INFO) with session_manager() as session: employees = session.query(Employee).options( joinedload('employer').joinedload('parent').subqueryload('employees') ).filter(Employee.id == 3).all() for employee in employees: _ensure_loaded(employee, 'employer.parent.employees') # this block of code fails presumably because the parent employer is loaded into the session during # the first joinedload of the employer which doesn't trigger the subqueryload for parent.employees # for the company that actually does have a parent company. with session_manager() as session: employees = session.query(Employee).options( joinedload('employer').joinedload('parent').subqueryload('employees') ).filter().all() for employee in employees: _ensure_loaded(employee, 'employer.parent.employees') ``` |
|
From: Alex P. <iss...@bi...> - 2016-05-18 09:49:02
|
New issue 3716: SQLAlchemy not finding tables in two postgres separate schemas at same time https://bitbucket.org/zzzeek/sqlalchemy/issues/3716/sqlalchemy-not-finding-tables-in-two Alex Petralia: SQLAlchemy version: **1.0.12** I originally raised this issue as a bug with `pandas` but I believe it is actually an issue with SQLAlchemy: https://github.com/pydata/pandas/issues/13210#issuecomment-219881388 I have a SQLAlchemy Engine object: ``` In[11]: SQLALCHEMY_CONN Out[11]: Engine(postgresql://***:***@***:***/***) ``` In the schema `a`, I have a table named `ads_skus` which has a foreign key reference to a table `sku` in the `public` schema. ``` In[12]: SQLALCHEMY_CONN.has_table('ads_skus', schema='a') Out[12]: True ``` SQLAlchemy can find the table in the same schema, but not the foreign table in the public schema: ``` In[13]: from sqlalchemy.schema import MetaData meta = MetaData(SQLALCHEMY_CONN, schema='a') meta.reflect(only=['ads_skus'], views=True) Out[13]: NoSuchTableError: sku ``` |
|
From: Iuri de S. <iss...@bi...> - 2016-05-14 00:46:26
|
New issue 3715: psycopg2 throw an unhandled message https://bitbucket.org/zzzeek/sqlalchemy/issues/3715/psycopg2-throw-an-unhandled-message Iuri de Silvio: I'm receiving this error message: `SSL error: decryption failed or bad record mac` File `app.py` ```python import os from flask import Flask from flask.ext.sqlalchemy import SQLAlchemy application = app = Flask(__name__) app.debug = True app.config['SQLALCHEMY_DATABASE_URI'] = os.getenv("DBURI") db = SQLAlchemy(app) # comment this block to "fix" the bug with app.app_context(): db.session.execute("SELECT 1") @app.route('/') def index(): res = db.session.execute("SELECT 1") return "OK %d" % res.scalar() ``` It happens running with `uwsgi` with multiple workers (`--workers 2`). Works fine with only one worker. ``` $ uwsgi --module app --http-socket :8000 --workers 2 --env=DBURI="postgresql+psycopg2://your_db_uri/db?client_encoding=utf8" ``` |
|
From: Михаил Д. <iss...@bi...> - 2016-05-13 14:25:40
|
New issue 3714: sqlalchemy core returns string instead of date object in mysql but date object in sqlite https://bitbucket.org/zzzeek/sqlalchemy/issues/3714/sqlalchemy-core-returns-string-instead-of Михаил Доронин: ``` #!python dates_to_check = ( from_date - timedelta(days=i) for i in xrange(1, days_limit + 1) ) selects = tuple( select((literal(d).label('td'), literal(d.isoweekday()).label('wd'))) for d in dates_to_check ) data = union(*selects, use_labels=True).alias() ``` I'm creating dates like that and then using it this kind of temporary table to join on date and weekday with other tables. After fetching data in sqlite it returns date object to me, but in mysql sqlalchemy return plain string. I can probably provide test case if needed at monday. Responsible: zzzeek |
|
From: Михаил Д. <iss...@bi...> - 2016-05-12 07:25:36
|
New issue 3713: Add Integer Enum type support https://bitbucket.org/zzzeek/sqlalchemy/issues/3713/add-integer-enum-type-support Михаил Доронин: There are attempts to do this already. [https://gist.github.com/shazow/594861](Link URL) [http://sqlalchemy-utils.readthedocs.io/en/latest/data_types.html#module-sqlalchemy_utils.types.choice](Link URL) But I think that this should be part of sqlalchemy really. Probably everybody knows this but I will state the benefits once more: 1. Takes less space in database 2. Provides higher level interface for cases where for the reason #1 INTEGER, TINYINT etc have been used instead of ENUM or VARCHAR where conceptually we are dealling with enum. Can't really think of everything else right now, but that's should be enough. I can try to add this functionality. I don't know sqlalchemy internals well enough, but the gist above should help and it's shouldn't be that hard in any case I think. The main reason I've maid issue instead of creating pull request right away is that I have a questions about implementation. 1. Should we extend existing Enum type or create a new one? Both ways would work of course, but in the former case would complicate Enum interface a bit (maybe) So I see it this way if native_enum param is False then we look if there is additional 'type' param. 'type' can be one of sqlalchemy types suiting Enum or even database specific type like TINYINT or it could be 'auto', in which case sqlalchemy would choose type based on the amount of enum members (like if we have 3 members that it can use something like TINYINT(2)). Default value for 'type' param would be varchar so old code wouldn't be broken. Another option is to create a new IntEnum type with similar interface. Responsible: zzzeek |
|
From: Alexander M. <iss...@bi...> - 2016-05-11 16:56:25
|
New issue 3712: Documentation issue with Pessimistic Disconnect Handler Example https://bitbucket.org/zzzeek/sqlalchemy/issues/3712/documentation-issue-with-pessimistic Alexander Mohr: The example documented here: http://docs.sqlalchemy.org/en/latest/core/pooling.html#disconnect-handling-pessimistic has an issue in that it doesn't account for the connection.should_close_with_result status. If this is set it means that the select() will close the connection, causing the original request to work on a closed connection and failing. My trivial fix was to stash the state, set it to false, and then resolve after doing the select 1. |
|
From: Mike B. <iss...@bi...> - 2016-05-10 16:34:19
|
New issue 3711: SQL Server repurposing of ORDER BY -> OVER mis-applies label_reference https://bitbucket.org/zzzeek/sqlalchemy/issues/3711/sql-server-repurposing-of-order-by-over Mike Bayer: the select() element wraps each order by with "label_reference()", which is only appropriate to call upon in the ORDER BY. mssql dialect should unwrap these before it moves the order by into OVER: ``` #!python from sqlalchemy import * m = MetaData() t = Table('t', m, Column('x', Integer)) expr1 = func.foo(t.c.x).label('x') expr2 = func.foo(t.c.x).label('y') stmt1 = select([expr1]).order_by(expr1.desc()).offset(1) stmt2 = select([expr2]).order_by(expr2.desc()).offset(1) from sqlalchemy.dialects import mssql print stmt1.compile(dialect=mssql.dialect()) print stmt2.compile(dialect=mssql.dialect()) ``` output: ``` #! SELECT anon_1.x FROM (SELECT foo(t.x) AS x, ROW_NUMBER() OVER (ORDER BY x DESC) AS mssql_rn FROM t) AS anon_1 WHERE mssql_rn > :param_1 SELECT anon_1.y FROM (SELECT foo(t.x) AS y, ROW_NUMBER() OVER (ORDER BY foo(t.x) DESC) AS mssql_rn FROM t) AS anon_1 WHERE mssql_rn > :param_1 ``` |
|
From: Chris W. <iss...@bi...> - 2016-05-10 11:29:08
|
New issue 3710: Delayed configuration of polymorphic subclasses leads to duplicate event handler registration https://bitbucket.org/zzzeek/sqlalchemy/issues/3710/delayed-configuration-of-polymorphic Chris Wilson: We have a complex system with mapped classes defined in many different files, used by different applications. Therefore we use derived-map polymorphic loading to load only those classes which are needed, sometimes when processing query results. We have been running into problems with SQLAlchemy generating SQL that tries to violate database constraints, for example trying to insert the same row twice in a many-to-many association secondary table: ``` IntegrityError: (psycopg2.IntegrityError) duplicate key value violates unique constraint "cons_m2m_primary_key" DETAIL: Key (id_foo, id_bar)=(182145, 29586) already exists. [SQL: 'INSERT INTO m2m (id_foo, id_bar) VALUES (%(id_foo)s, %(id_bar)s)'] [parameters: ({'id_foo': 182145, 'id_bar': 29586}, {'id_foo': 182145, 'id_bar': 29586})] ``` We tracked this down to delayed initialisation of polymorphic classes and their subclasses resulting in duplicate event listeners being added for the backref relationship. This results in A.bs == [b], but B.as == [a, a]. Depending on the order in which the unitofwork flushes these out to the database, 50% of the time it will try to flush B.as first and generate SQL which violates the database constraints, as above. Please consider the following abstract example, where the base class Animal is registered first, along with its relationship to Home, and then the polymorphic subclasses Mammal and Dog are loaded and configured in a separate step: ``` #!python from sqlalchemy import Column, ForeignKey, Integer, Table, Text, create_engine, event from sqlalchemy.ext.declarative import declarative_base, declared_attr from sqlalchemy.orm import Mapper, configure_mappers, relationship, sessionmaker from sqlalchemy.orm.mapper import _mapper_registry # This event listener may be useful for debugging: if False: @event.listens_for(Mapper, 'mapper_configured') def receive_mapper_configured(mapper, class_): # assets_allowed = mapper._props.get('assets_allowed') homes = getattr(class_, 'homes', None) if homes is not None: dispatch = list(homes.dispatch.append) if len(dispatch) > 2: print "{} failed: {} ({})".format(class_, mapper, dispatch) assert len(dispatch) <= 2, "{}: {}".format(class_, dispatch) print "{} configured: {} ({})".format(class_, mapper, repr(homes)) _mapper_registry.clear() Base = declarative_base() # Register these classes first, including the concrete polymorphic base class with the M2M association: class Home(Base): __tablename__ = 'home' id = Column(Integer, primary_key=True) name = Column(Text) class Animal(Base): __tablename__ = 'mammal' id = Column(Integer, primary_key=True) name = Column(Text) homes_table = Table("mammal_home", Base.metadata, Column('id_mammal', Integer, ForeignKey(id), primary_key=True), Column('id_home', Integer, ForeignKey(Home.id), primary_key=True) ) homes = relationship(Home, secondary=homes_table, backref='animals') species = Column(Text) @declared_attr def __mapper_args__(cls): return { 'polymorphic_on': cls.species, 'polymorphic_identity': cls.__name__, } # Register the first set of classes and create their Mappers configure_mappers() # Simulate dynamic loading of additional mapped classes class Mammal(Animal): pass class Dog(Mammal): pass # These new classes should not be configured at this point: unconfigured = [m for m in _mapper_registry if not m.configured] assert len(unconfigured) == 2, str(unconfigured) # Now register them in a separate pass. # # If we take the first branch, this test will fail randomly 50% of the time, depending on the order of # Mammal and Dog in _mapper_registry. The second branch manipulates the registry and calls configure_mappers() # twice to force the Mappers to register in the wrong order, causing the test to fail every time. if True: configure_mappers() else: old_mapper_registry = dict(_mapper_registry) del _mapper_registry[Mammal.__mapper__] Mapper._new_mappers = True configure_mappers() _mapper_registry[Mammal.__mapper__] = old_mapper_registry[Mammal.__mapper__] Mapper._new_mappers = True configure_mappers() # In this case, we know that we have hit the error: the event listeners are registered twice: assert len(Dog.homes.dispatch.append) == 4, list(Dog.homes.dispatch.append) assert len(Home.animals.dispatch.append) == 2, list(Home.animals.dispatch.append) assert len(Mammal.homes.dispatch.append) == 2, list(Mammal.homes.dispatch.append) # This assertion will fail 50% of the time if the first branch is taken, so I've commented it out, # and copied it under the second branch above where it should always "succeed" (indicating that the # event listeners are wrongly double-configured): # assert len(Dog.homes.dispatch.append) == 4, list(Dog.homes.dispatch.append) engine = create_engine('sqlite:///sqlalchemy_example.db') Base.metadata.create_all(engine) DBSession = sessionmaker(bind=engine) session = DBSession(autocommit=True) session.begin() home = Home(name="localhost") dog = Dog(name="fido", homes=[home]) assert len(dog.homes) == 1 assert len(home.animals) == 1, "This fails: Dog is listed twice in home.animals: {}".format(home.animals) print "Test passed: this will happen 50% of the time if the first branch is taken" ``` When `configure_mappers()` is called to configure the subclasses, it loops over the `_mapper_registry` in random order. Thus, it may configure `Dog` first and then `Mammal`, or vice versa. When it configures `Dog` and `Mammal`, it will add two event listeners to their `homes.dispatch.append` list: `append` and `emit_backref_from_collection_append_event`. The latter adds the Dog/Mammal to the backref relationship, unconditionally (even if already present), so it must only be called once. However, if it configures `Dog` first and `Mammal` second, then when it configures `Mammal` it loops over `mapper.self_and_descendants` (in `_register_attribute`) and thus registers the same event listeners on `Dog.homes.dispatch.append` again. So whenever a `Dog` is given some `homes`, it will be added **twice** to the `animals` collection on each of those `Homes`. This does not happen if `Mammal` is registered first and `Dog` second, because when post-configuring `Dog.homes`, `mapper.class_manager._attr_has_impl(self.key)` returns True and it is not initialised again. I think the problem is related to the comment on `_post_configure_properties` which says "This is a deferred configuration step which is intended to execute once all mappers have been constructed." However this function is called whenever `configure_mappers()` finds unconfigured mappers, not only once. Possibly this changed at some point and violated some assumptions? One fix would be to check `mapper.class_manager._attr_has_impl(key)` on each mapper when looping over `mapper.self_and_descendants`, to avoid registering it twice. However that might be a layering violation. Another fix might be, when looping over mappers in `configure_mappers()` looking for unconfigured ones, to walk up the ancestor chain of each unconfigured mapper until we find the most ancient unconfigured one, and configure that first, followed by its children, and their children, and so on. |
|
From: matteo n. <iss...@bi...> - 2016-05-09 10:14:08
|
New issue 3709: failed basic arithmetic with Date() objects with sqlite3 backend https://bitbucket.org/zzzeek/sqlalchemy/issues/3709/failed-basic-arithmetic-with-date-objects matteo nunziati: hello, I'm trying to perform basic arithmetic in a query which involves Date() objects. I've tried this with sqlalchemy 1.0.5 and 1.0.12. My backend is sqlite. Namely, I'm trying to subtract two dates (stored ad Date()) and I only got year delta as result. Basically, it seems that only year is involved in computation. Attached is a small demonstrative code. |
|
From: pkyosx <iss...@bi...> - 2016-05-07 03:26:57
|
New issue 3708: Inconsistent behavior when updating foreign key https://bitbucket.org/zzzeek/sqlalchemy/issues/3708/inconsistent-behavior-when-updating pkyosx: Suppose we have Parent and Child classes as One-To-Many relationship. If I move child from one parent to another, the order of changing foreign_key and foreign_object result in different behavior. Following are the briefing of reproducing steps. Attachments are runnable reproducing scripts. It still happens in 1.1.0b1.dev0 build. ``` #!python // Models class Parent(Base): __tablename__ = 'parent' id = Column(Integer, primary_key=True) children = relationship("Child", back_populates="parent") class Child(Base): __tablename__ = 'child' id = Column(Integer, primary_key=True) parent_id = Column(Integer, ForeignKey('parent.id')) parent = relationship("Parent", back_populates="children") // Initial Setting p1 = Parent() p2 = Parent() c = Child() c.parent = p1 s.commit() // Scenario1: Move c from p1 to p2 c.parent_id = p2.id c.parent = p2 assert c in p2.children, "this will fail" // Scenario 2: Move c from p1 to p2 c.parent = p2 c.parent_id = p2.id assert c in p2.children, "this will success" ``` |
|
From: kuthair <iss...@bi...> - 2016-05-05 20:08:46
|
New issue 3706: Text() with Group by causes 'TextClause' object has no attribute 'c' https://bitbucket.org/zzzeek/sqlalchemy/issues/3706/text-with-group-by-causes-textclause kuthair: I get the following error when trying to apply text() to a group_by clause. `query = query.group_by(text(group_by))` **Error:** 'TextClause' object has no attribute 'c' Without text(), I get the following warning: `SAWarning: Can't resolve label reference 'import_first_name, import...'; converting to text() (this warning may be suppressed after 10 occurrences)` Here's the stack trace of the error: ```File \"<string>\", line 2, in group_by\n File \"/Code/.api2.env/lib/python3.5/site-packages/sqlalchemy/orm/base.py\", line 201, in generate\n fn(self, *args[1:], **kw)\n File \"/Code/.api2.env/lib/python3.5/site-packages/sqlalchemy/orm/query.py\", line 1550, in group_by\n criterion = list(chain(*[_orm_columns(c) for c in criterion]))\n File \"/Code/.api2.env/lib/python3.5/site-packages/sqlalchemy/orm/query.py\", line 1550, in <listcomp>\n criterion = list(chain(*[_orm_columns(c) for c in criterion]))\n File \"/Code/.api2.env/lib/python3.5/site-packages/sqlalchemy/orm/base.py\", line 348, in _orm_columns\n return [c for c in insp.selectable.c]\nAttributeError: 'TextClause' object has no attribute 'c'\n"``` |
|
From: delijati <iss...@bi...> - 2016-05-04 10:29:47
|
New issue 3704: Example dictlike-polymorphic not working https://bitbucket.org/zzzeek/sqlalchemy/issues/3704/example-dictlike-polymorphic-not-working delijati: There are error. First is easy to fix: ``` #!python ... class Animal(ProxiedDictMixin, Base) # corrected version ... ``` The second one throws: ``` #!python Animal.value))))... NotImpementedError: <__main__.value object at ...> ``` |
|
From: LMendy <iss...@bi...> - 2016-05-03 22:24:58
|
New issue 3702: multiple insert fails with percentage symbol (%) in column name https://bitbucket.org/zzzeek/sqlalchemy/issues/3702/multiple-insert-fails-with-percentage LMendy: I am trying to use sqlalchemy (version 1.0.12) to perform a multi-insert on a table that has columns with percentage symbols in the column names. Rows can be inserted one at a time without a problem, but when the performing a multi-insert with con.execute() a OperationalError exception is raised. The code below reproduces the problem. Two tables are created, one with percentage names in columns, the other without. 1. The multi-insert on the table with % in the column names fails. 2. Inserting rows one by one in the table with the % in column names works. 3. Multi-insert on the table without % in column names works. ``` #!python from sqlalchemy import * USER = 'root' PASSWORD = '' HOST = '127.0.0.1' DBNAME = 'test' connect_str = "mysql://{USER}:{PASSWORD}@{HOST}/{DBNAME}".format( USER = USER, PASSWORD = PASSWORD, HOST = HOST, DBNAME = DBNAME ) engine = create_engine(connect_str, echo = False) metadata = MetaData() table_with_percent = Table('table_with_percent', metadata, Column('A%', Integer), Column('B%', Integer) ) table_no_percent = Table('table_no_percent', metadata, Column('A', Integer), Column('B', Integer) ) metadata.create_all(engine, checkfirst = True) ##################################### # Create rows to be inserted rows = [(1,2), (3,4), (5,6)] table_with_percent_rows = [dict(zip(table_with_percent.c.keys(), row)) for row in rows] table_no_percent_rows = [dict(zip(table_no_percent.c.keys(), row)) for row in rows] ######################### # Try the inserts con = engine.connect() # 1. THIS FAILS! Mutli insert on table with percentage symbol in column names. # OperationalError: (_mysql_exceptions.OperationalError) (1054, "Unknown column 'A%%' in 'field list'") [SQL: u'INSERT INTO table_with_percent (`A%%`, `B%%`) VALUES (%s, %s)'] [parameters: ((1, 2), (3, 4), (5, 6))] con.execute(table_with_percent.insert(), table_with_percent_rows) # 2. But the rows can be inserted one by one: for row in table_with_percent_rows: con.execute(table_with_percent.insert(), row) # 3. This works! Multi insert on table with no percent in columns con.execute(table_no_percent.insert(), table_no_percent_rows) con.close() ``` |
|
From: John V. <iss...@bi...> - 2016-05-03 08:21:21
|
New issue 3701: cymysql fails in get_isolation_level during engine.connect() https://bitbucket.org/zzzeek/sqlalchemy/issues/3701/cymysql-fails-in-get_isolation_level John Vandenberg: While connecting, the following error occurs. ``` ==================================== ERRORS ==================================== ______________________ ERROR at setup of test_2010_count _______________________ request = <SubRequest 'connection' for <Function 'test_2010_count'>> engine = Engine(mysql+cymysql://travis@localhost/era_data) @pytest.fixture(scope="module") def connection(request, engine): > connection = engine.connect() ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/pytest_sqlalchemy.py:27: _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/engine/base.py:2018: in connect return self._connection_cls(self, **kwargs) ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/engine/base.py:72: in __init__ if connection is not None else engine.raw_connection() ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/engine/base.py:2104: in raw_connection self.pool.unique_connection, _connection) ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/engine/base.py:2074: in _wrap_pool_connect return fn() ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/pool.py:318: in unique_connection return _ConnectionFairy._checkout(self) ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/pool.py:713: in _checkout fairy = _ConnectionRecord.checkout(pool) ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/pool.py:480: in checkout rec = pool._do_get() ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/pool.py:1060: in _do_get self._dec_overflow() ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/util/langhelpers.py:60: in __exit__ compat.reraise(exc_type, exc_value, exc_tb) ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/pool.py:1057: in _do_get return self._create_connection() ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/pool.py:323: in _create_connection return _ConnectionRecord(self) ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/pool.py:454: in __init__ exec_once(self.connection, self) ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/event/attr.py:246: in exec_once self(*args, **kw) ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/event/attr.py:256: in __call__ fn(*args, **kw) ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/util/langhelpers.py:1319: in go return once_fn(*arg, **kw) ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/engine/strategies.py:165: in first_connect dialect.initialize(c) ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/dialects/mysql/base.py:2633: in initialize default.DefaultDialect.initialize(self, connection) ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/engine/default.py:249: in initialize self.get_isolation_level(connection.connection) _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ self = <sqlalchemy.dialects.mysql.cymysql.MySQLDialect_cymysql object at 0x1db15d0> connection = <cymysql.connections.Connection object at 0x1db19d0> def get_isolation_level(self, connection): cursor = connection.cursor() cursor.execute('SELECT @@tx_isolation') val = cursor.fetchone()[0] cursor.close() if util.py3k and isinstance(val, bytes): val = val.decode() > return val.upper().replace("-", " ") E AttributeError: 'NoneType' object has no attribute 'upper' ../../../virtualenv/python2.7_with_system_site_packages/local/lib/python2.7/site-packages/sqlalchemy/dialects/mysql/base.py:2502: AttributeError ``` https://travis-ci.org/jayvdb/era_data/jobs/127444574 |
|
From: Gabor G. <iss...@bi...> - 2016-04-29 12:07:12
|
New issue 3700: synchronize_session='evaluate' does not work when filtering by relation https://bitbucket.org/zzzeek/sqlalchemy/issues/3700/synchronize_session-evaluate-does-not-work Gabor Gombas: Hi, It seems Query.delete(synchronize_session='evaluate') does not work if there is a filter condition which references a relation instead of a column. Tested with SQLAlchemy 1.0.11. Gabor |
|
From: Mike B. <iss...@bi...> - 2016-04-27 16:19:24
|
New issue 3699: BuffferedColumnResultProxy with compiled_cache corrupts result metadata https://bitbucket.org/zzzeek/sqlalchemy/issues/3699/buffferedcolumnresultproxy-with Mike Bayer: ``` #!python from sqlalchemy import create_engine, select, TypeDecorator, String, literal from sqlalchemy.engine import default from sqlalchemy.engine import result class ExcCtx(default.DefaultExecutionContext): def get_result_proxy(self): return result.BufferedColumnResultProxy(self) engine = create_engine("sqlite://") engine.dialect.execution_ctx_cls = ExcCtx class MyType(TypeDecorator): impl = String() def process_result_value(self, value, dialect): return "HI " + value with engine.connect() as conn: stmt = select([literal("THERE", type_=MyType())]) for i in range(2): r = conn.execute(stmt) assert r.scalar() == "HI THERE" with engine.connect() as conn: cache = {} conn = conn.execution_options(compiled_cache=cache) stmt = select([literal("THERE", type_=MyType())]) for i in range(2): r = conn.execute(stmt) assert r.scalar() == "HI THERE" ``` |
|
From: John M. <iss...@bi...> - 2016-04-26 21:11:58
|
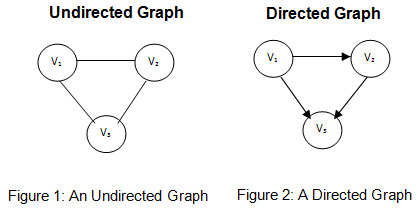
New issue 3698: Error in Directed Graph Documentation https://bitbucket.org/zzzeek/sqlalchemy/issues/3698/error-in-directed-graph-documentation John Mercouris: If you look in the examples, the documentation mentions that you may setup directed graphs: http://docs.sqlalchemy.org/en/rel_1_0/orm/examples.html#module-examples.graphs The code for the directed graph can be found here: http://docs.sqlalchemy.org/en/rel_1_0/_modules/examples/graphs/directed_graph.html Unfortunately the code for the directed graph is actually for an undirected graph (directed vs undirected graph) http://www.differencebetween.com/wp-content/uploads/2011/05/DifferenceBetween_Directed_UnDirected_Graphs1.jpg The reason it is a directed graph is because you may not add a relationship from n1->n2 as well as from n2->n1. The program will crash and complain that there is a duplicate entry. For your convenience I have modified the program to show an example of a directed graph: (http://pastebin.com/xJDPdvYJ) - also attached to this issue. Also attached is the database generated from running the file. You can run the program to demonstrate it for yourself, thank you for your time. |
|
From: Mikko O. <iss...@bi...> - 2016-04-26 21:11:41
|
New issue 3697: Add bitbucket link to github.com/zzzeek/sqlalchemy https://bitbucket.org/zzzeek/sqlalchemy/issues/3697/add-bitbucket-link-to-githubcom-zzzeek Mikko Ohtamaa: Currently Github mirrors Bitbucket repository, but Github page does not say directly where on the bitbucket the primary copy is hosted. Maybe it could be possible that on Github project, edit the project and add link https://bitbucket.org/zzzeek/sqlalchemy as the project website. This way the link would so on Github project page as the first thing. |
|
From: Rudolf C. <iss...@bi...> - 2016-04-26 14:13:10
|
New issue 3696: Documentation error in mssql+pymssql connection string https://bitbucket.org/zzzeek/sqlalchemy/issues/3696/documentation-error-in-mssql-pymssql Rudolf Cardinal: The docs at http://docs.sqlalchemy.org/en/latest/dialects/mssql.html#module-sqlalchemy.dialects.mssql.pymssql give the following prototype connection string for SQL Server (mssql) via pymssql: ``` #!python mssql+pymssql://<username>:<password>@<freetds_name>?charset=utf8 ``` However (with SQL Alchemy 1.0.12 via "pip install"), this fails. Traceback below. But the basic reason appears to be that the "?charset=utf8" gets incorporated into the "host" parameter. The URL used was: ``` #!python mssql+pymssql://researcher:blibble@crate_sqlserver_test?charset=utf8 ``` where crate_sqlserver_test is defined in /etc/freetds/freetds.conf. Inserting a debugging print statement into DefaultDialect.connect(), in sqlalchemy/engine/default.py, where it calls ``` #!python return self.dbapi.connect(*cargs, **cparams) ``` gives the following: ``` #!python cargs: () cparams: {'password': 'blibble', 'host': 'crate_sqlserver_test?charset=utf8', 'user': 'researcher'} ``` **(note the error for host).** ``` #!python Traceback (most recent call last): File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/pool.py", line 1044, in _do_get return self._pool.get(wait, self._timeout) File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/util/queue.py", line 145, in get raise Empty sqlalchemy.util.queue.Empty During handling of the above exception, another exception occurred: Traceback (most recent call last): File "pymssql.pyx", line 635, in pymssql.connect (pymssql.c:10699) File "_mssql.pyx", line 1900, in _mssql.connect (_mssql.c:21951) File "_mssql.pyx", line 636, in _mssql.MSSQLConnection.__init__ (_mssql.c:6545) _mssql.MSSQLDriverException: Connection to the database failed for an unknown reason. During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/engine/base.py", line 2074, in _wrap_pool_connect return fn() File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/pool.py", line 318, in unique_connection return _ConnectionFairy._checkout(self) File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/pool.py", line 713, in _checkout fairy = _ConnectionRecord.checkout(pool) File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/pool.py", line 480, in checkout rec = pool._do_get() File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/pool.py", line 1060, in _do_get self._dec_overflow() File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/util/langhelpers.py", line 60, in __exit__ compat.reraise(exc_type, exc_value, exc_tb) File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/util/compat.py", line 184, in reraise raise value File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/pool.py", line 1057, in _do_get return self._create_connection() File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/pool.py", line 323, in _create_connection return _ConnectionRecord(self) File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/pool.py", line 449, in __init__ self.connection = self.__connect() File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/pool.py", line 607, in __connect connection = self.__pool._invoke_creator(self) File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/engine/strategies.py", line 97, in connect return dialect.connect(*cargs, **cparams) File "/home/rudolf/venvs/crate/lib/python3.4/site-packages/sqlalchemy/engine/default.py", line 387, in connect return self.dbapi.connect(*cargs, **cparams) File "pymssql.pyx", line 644, in pymssql.connect (pymssql.c:10856) pymssql.InterfaceError: Connection to the database failed for an unknown reason. ``` |
|
From: aCLr <iss...@bi...> - 2016-04-22 13:42:36
|
New issue 3695: update error using vertica-python https://bitbucket.org/zzzeek/sqlalchemy/issues/3695/update-error-using-vertica-python aCLr: Hi. I use your library (1.0.12) with vertica_python adapter(0.5.5) and get that situation: ``` #!sql 2016-04-22 16:26:24,691 INFO sqlalchemy.engine.base.Engine UPDATE orders SET comment=:comment, ts_last_activity=:ts_last_activity, state=:state, previous_state=:previous_state, flags=:flags WHERE orders.id = :orders_id 2016-04-22 16:26:24,691 INFO sqlalchemy.engine.base.Engine {'comment': '"last_activity"=>"2016-04-22 13:26"', 'orders_id': 2000205, 'previous_state': 500, 'state': 300, 'flags': 2048, 'ts_last_activity': 1461320780} 2016-04-22 16:26:24,790 INFO sqlalchemy.engine.base.Engine ROLLBACK StaleDataError: UPDATE statement on table 'orders' expected to update 1 row(s); -1 were matched. ``` Here I'm checking the session state: ``` #!python >>> SessionVertica.identity_map <sqlalchemy.orm.identity.WeakInstanceDict object at 0x7f43c5e46f90> >>> SessionVertica.identity_map.check_modified() True >>> SessionVertica.identity_map.keys() [(<class 'hasoffers.core.model.order.S'>, (2000205,))] >>> recounted_base.id 2000205 ``` As you see, I have rows for update, but i get the error above. Do you have any idea, what does it means? |
|
From: Arnout v. M. <iss...@bi...> - 2016-04-14 20:17:20
|
New issue 3694: Incorrect processing of has_key parameter on JSONB columns with custom types https://bitbucket.org/zzzeek/sqlalchemy/issues/3694/incorrect-processing-of-has_key-parameter Arnout van Meer: In our codebase we have a custom type based on JSONB and noticed has_key wasn't working. This seems to be due to parameter to has_key getting run through the bind processor which results in unintended quoting of the parameter string. Repro case, tested with 1.0.12: ``` #!python from sqlalchemy import create_engine, Column, Table, MetaData, select, types from sqlalchemy.dialects.postgresql import JSONB class CustomJSONBType(types.TypeDecorator): impl = JSONB e = create_engine("postgresql://localhost/jsonb_test", echo=True) c = e.connect() t = c.begin() # this works table = Table('jsonb_test', MetaData(), Column('data', JSONB)) table.create(c) c.execute(table.insert(), [{"data": {"x": 2}}]) assert c.scalar(select([table]).where(table.c.data.has_key('x'))) # this doesn't work table = Table('custom_jsonb_test', MetaData(), Column('data', CustomJSONBType)) table.create(c) c.execute(table.insert(), [{"data": {"x": 2}}]) assert c.scalar(select([table]).where(table.c.data.has_key('x'))) ``` |
{kind=link}
{kind=link}
{kind=link}
{kind=link}