Menu
▾
▴


Compiling and running
How to compile SLAM++
Let's begin by downloading the source code. Alternately, you can get the sources from the svn:
mkdir slam
cd slam
svn checkout svn://svn.code.sf.net/p/slam-plus-plus/code/trunk .
Build depends on your operating system. For Windows users, there is a ready-to-use Visual Studio workspace in the build folder. You need to just open it, compile and run.
For Linux, Mac or BSD you can use commandline, like this:
cd build
cmake -i ..
<CMake will now show you configuration options>
make
You can avoid the config options by omitting the -i switch. It is possible to use parallel build command to build faster:
make -j 8
Where 8 is the number of CPUs on your machine.
That should take care of the build. Don't use CMake for Visual Studio, there is a link conflict in Eigen, there are some files in different directories that generate the same .obj files, overwriting each other. Either download the configured workspace from SorceForge, or if you must, generate, open the workspace in Visual Studio, open Solution Explorer and in project eigen3, right-click on complex_double.cpp, go to "C++" and "Output Files", and change "Object File Name" from "$(IntDir)\" to "$(IntDir)\lapack\" (the second slash is important). Now click on the second complex_double.cpp and repeat the procedure, only put "$(IntDir)\blas\". This needs to be repeated also for complex_single.cpp, double.cpp and single.cpp.
Note that with CMake, there is no way to do multiple target x86 / x64 builds in Visual Studio.
Also, it's good to tweak optimizations in Visual Studio, you can turn "Full Optimization" on, enable link-time code generation, and importantly enable OpenMP support.
Some Ubuntu distributions have linking problem which yields errors such as:
Timer.cpp:(.text+0x18): undefined reference to `clock_gettime'
This is solved by adding the -Wl,--no-as-needed (written together, exactly like that) in the EXE_LINKER_FLAGS field in CMake (the -lrt option is already there by default and adding it won't change anything).
How to run SLAM++
First, you need some data to run it with. The current implementation allows parsing standard graph SLAM datasets (vertices and edges). The graph files can be downloaded from the data folder. There are several simulated and real datasets. The later were obtained from processing sensor readings.
Now let's say we want to see the Manhattan:
./bin/slam_plus_plus -i data/manhattanOlson3500.txt --lambda --pose-only
What does that do? We just specify the incremental flag '-i', the input file, the solver to use (the lambda solver, in this case) and finally the --pose-only flag specifies that the dataset only contains poses and optimized code path can be used.
This should produce the following input (if it does not, look here):
> ./SLAM_plus_plus -i data/manhattanOlson3500.txt --lambda --pose-only
SLAM++ version x64 (compiled at Feb 14 2013)
built with the following flags:
_OPENMP (8 threads)
__USE_CSPARSE
EIGEN_VECTORIZE
EIGEN_VECTORIZE_SSE
EIGEN_VECTORIZE_SSE2
EIGEN_VECTORIZE_SSE3
__BLOCK_BENCH_BLOCK_TYPE_A
__BLOCK_BENCH_CHOLESKY_USE_AMD
__SLAM_COUNT_ITERATIONS_AS_VERTICES
__SEGREGATED_MAKE_CHECKED_ITERATORS
__SE_TYPES_SUPPORT_NONLINEAR_SOLVER_A
__SE_TYPES_SUPPORT_NONLINEAR_SOLVER_LAMBDA
__SE_TYPES_SUPPORT_NONLINEAR_SOLVER_L
warning: running in batch mode. ignoring time spent in parser
=== nonlinear optimization: iter #0 ===
Cholesky rulez!
residual norm: 685.2099
=== nonlinear optimization: iter #1 ===
Cholesky rulez!
residual norm: 136.7427
=== nonlinear optimization: iter #2 ===
Cholesky rulez!
residual norm: 19.7558
=== nonlinear optimization: iter #3 ===
Cholesky rulez!
residual norm: 0.4239
=== nonlinear optimization: iter #4 ===
Cholesky rulez!
residual norm: 0.0379
done. it took 00:00:00.14192 (0.141921 sec)
solver took 5 iterations
solver spent 0.016707 seconds in parallelizable section (updating lambda)
solver spent 0.125214 seconds in serial section
out of which:
ata: 0.000000
gaxpy: 0.000000
chol: 0.125118
norm: 0.000096
total: 0.125214
denormalized chi2 error: 136.84
If you don't want the timing breakup, use --no-detailed-timing, if you don't want the other stuff, use --silent. It also writes some output files, especially initial.tga and solution.tga. The initial.tga contains the initial prior and the solution.tga contains the optimized system:
The initial prior is on the top, the solution below. What you see is a trajectory of a robot, navigating streets of a fictional Manhattan. There is simulated sensor noise, which makes the initial prior all mixed up. We can see that the problem converged, as the solution image looks relatively ordered (the edges at the corners are caused by the robot not being able to get all the correspondences correctly, and those are already in the dataset). In case you don't want the images to be generated (e.g. for benchmarking purposes), use --no-bitmaps.
What we just did was so called batch optimization: the initial priors of the systems were calculated, and then the system was optimized at once. This doesn't always work, sometimes the initial priors are "too tangled up" and the problem can not be solved at once. Then we use incremental optimization to solve the problem in smaller batches at every step, slowly building towards the complete solution (but really fast in our implementation). For incremental mode we use:
> ./SLAM_plus_plus -i data/victoria-park.txt --lambda --silent --nonlinear-solve-period 100
SLAM++ version x64 (compiled at Feb 14 2013)
built with the following flags:
_OPENMP (8 threads)
__USE_CSPARSE
EIGEN_VECTORIZE
EIGEN_VECTORIZE_SSE
EIGEN_VECTORIZE_SSE2
EIGEN_VECTORIZE_SSE3
__BLOCK_BENCH_BLOCK_TYPE_A
__BLOCK_BENCH_CHOLESKY_USE_AMD
__SLAM_COUNT_ITERATIONS_AS_VERTICES
__SEGREGATED_MAKE_CHECKED_ITERATORS
__SE_TYPES_SUPPORT_NONLINEAR_SOLVER_A
__SE_TYPES_SUPPORT_NONLINEAR_SOLVER_LAMBDA
__SE_TYPES_SUPPORT_NONLINEAR_SOLVER_L
done. it took 00:00:02.67555 (2.675548 sec)
solver took 146 iterations
solver spent 0.392879 seconds in parallelizable section (updating lambda)
solver spent 2.282669 seconds in serial section
out of which:
ata: 0.000000
gaxpy: 0.000000
chol: 2.281537
norm: 0.001132
total: 2.282669
denormalized chi2 error: 144.84
The --nonlinear-solve-period switch says to solve for each 100 vertices. The solution is on the following image:
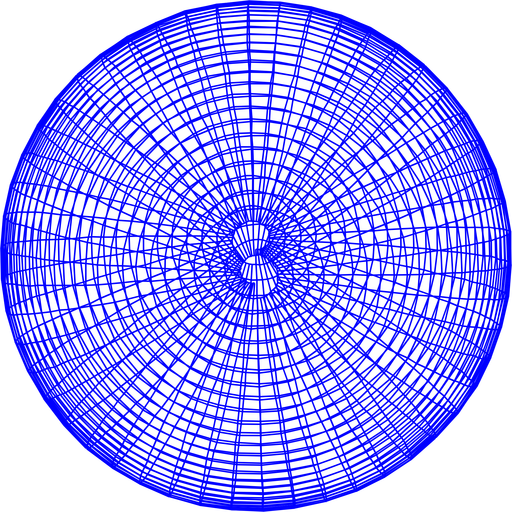
Running the 3D datasets is just as easy, just use:
./bin/slam_plus_plus -i data/sphere2500.txt --lambda --pose-only
And you will get:
Commandline reference
To get full commandline reference, simply use the --help switch:
General use:
./SLAM_plus_plus -i <filename> --no-detailed-timing
To run the pose-only datasets more quickly:
./SLAM_plus_plus -i <filename> --pose-only --no-detailed-timing
To run incrementally:
./SLAM_plus_plus -lsp <optimize-each-N-steps> -i <filename> --no-detailed-timing
This generates initial.txt and initial.tga, a description and image of the
system before the final optimization, and solution.txt and solution.tga, a
description and image of the final optimized system (unless --no-bitmaps
is specified).
--help|-h displays this help screen
--verbose|-v displays verbose output while running (may slow down,
especially in windows and if running incrementally)
--silent|-s suppresses displaying verbose output
--no-show|-ns doesn't show output image (windows only)
--no-commandline doesn't echo command line
--no-flags doesn't show compiler flags
--no-detailed-timing doesn't show detailed timing breakup (use this, you'll
get confused)
--no-bitmaps doesn't write bitmaps initial.tga and solution.tga (neither
the text files)
--pose-only|-po enables optimisation for pose-only slam (will warn and ignore
on datasets with landmarks (only the first 1000 lines checked
in case there are landmarks later, it would segfault))
--use-old-code|-uogc uses the old CSparse code (no block matrices in it)
--a-slam|-A uses A-SLAM (default)
--lambda|-,\ uses lambda-SLAM (preferred batch solver)
--l-slam|-L uses L-SLAM
--fast-l-slam|-fL uses the new fast L-SLAM solver (preferred incremental solver)
--infile|-i <filename> specifies input file <filename>; it can cope with
many file types and conventions
--parse-lines-limit|-pll <N> sets limit of lines read from the input file
(handy for testing), note this does not set limit of vertices
nor edges!
--linear-solve-period|-lsp <N> sets period for incrementally running linear
solver (default 0: disabled)
--nonlinear-solve-period|-nsp <N> sets period for incrementally running
non-linear solver (default 0: disabled)
--max-nonlinear-solve-iters|-mnsi <N> sets maximal number of nonlinear
solver iterations (default 10)
--nonlinear-solve-error-thresh|-nset <f> sets nonlinear solve error threshold
(default 20)
--max-final-nonlinear-solve-iters|-mfnsi <N> sets maximal number of final
optimization iterations (default 5)
--final-nonlinear-solve-error-thresh|-fnset <f> sets final nonlinear solve
error threshold (default .01)
--run-matrix-benchmarks|-rmb <benchmark-name> <benchmark-type> runs block
matrix benchmarks (benchmark-name is name of a folder with
UFLSMC benchmark, benchmark-type is one of alloc, factor, all)
--run-matrix-unit-tests|-rmut runs block matrix unit tests