Thank you so much Igor. I'm glad you've listened. I can feel my code examples influenced you ;-)
Now I'll try to persuade you to include ZSTD, LZ4 and LZ5 compression methods (which are in 7-Zip ZSTD clone https://github.com/mcmilk/7-Zip-zstd).
Recently I've tested ZSTD method on this data - https://github.com/berzerk0/Probable-Wordlists - and it made my jaw drop on the floor. ZSTD method compressed this text data as good as LZMA2 but MUCH MUCH faster.
And there's this famous LZ4 with worse compression, but ASTONISHING speeds.
Please consider merging that fork into the official 7-Zip.
Have a good day.
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:
That graph is telling that the best agoriths are Zstd, and then Ppmd. In my tests Zstd is the best in terms of compression ratio / compression time. Only when size is really critical then Ppmd provides same ratios but taking about half the time as LZMA2.
It is clear for me that Zstd algorithm must be included in the next release of the main 7Zip project.
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:
Oh yeah, yor graphs show us that Zstd is better than Brotli in almost all aspects. What a pity that browser developers had decided to make Brotli a standard compression algorithm in the HTTP. It seems, that Zstd would be better.
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:
It is best to standardize on a single format that can be reliably decompressed with many different software products in the future, as well as on older computers. Zstd is the best candidate with low memory requirements and speed; it is also incluided in the self-extractor of Tino Reichardt's fork. The multiple experimental LZ formats look very confusing, and so do the memory-hungry modules explored by the FreeArc community.
Being tuned for plain-text and HTML, Brotli is unimpressive with multimedia data. Sometimes it is bested by Deflate/Ultra in ratio, and they have similar speed.
I encountered two issues with ZS 1.3.1 R1 (x86):
1) Testing a ZST or LZ4 single file for integrity from inside it with the Test button (to estimate dec. speed) fails after 1 attempt with "Malformed input."
2) Zstandard Level 22 compression produced an error upon decompression on an XP system, after 64.75 megs were correctly decompresed: "Corrupted block detected." The compressor consumed about 1 GB of memory, did not raise an error, and gave a 7z archive of slightly smaller size than Level 21 (with 512 MB of memory).
It would be good if the memory estimates were filled in (decompression of Zstd would need 32, 64, 128 for the top levels).
Last edit: J7N 2017-08-26
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:
Can you open an issue with your two bugs.... I tried to catch them, but everything works, as it should. Please give some more details, so that I find the bug, if there is one.
Calculating the memory requirements is tricky, cause they are dynamic.... because of the threading and compressing block wise. You could watch the needed memory via wtime ...
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:
I have to leave this issue be, because I tried ZSTD on a second computer and there it reported an Allocation Error and didn't write a file for Level 22. So this issue is mostly cosmetic...
It would still be good to read the dictionary sizes on the GUI to determine the minimum Level needed to effectively deduplicate a set of similar files. Even if the dict can't be adjusted directly.
I played some more with Brotli. At Level 11 it is significantly better on heterogenous data. I previously tried it at Level 9. But the encoding speed now is so painfully slow that I can't imagine a use for it, where the encoding computer would be so much better than the consuming computer or the network to make the waiting worthwhile. So it would be especially good to know in advance that Brotli only goes to a 16 MB dictionary.
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:
Zstandard should normally be used up to level 17 (maximum) ... all other levels above this, will consume a lot more memory. I think about 1GB per thread for level 22... so if you have 8 Threads, level 22 will take 8GB just for compressing. This is mostly not useful. I take the levels 5 .. 11 for backup and such things ... it's very fast, and stable. It's 7-Zip ;-)
Last edit: Tino Reichardt 2017-09-10
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:
Hi Igor,
I have read that 7-zip now usually first reserves file space. Doesn't this lead to twice as much drive writing? This may still be a wanted behaviours for normal HDDs but with SSDs this leads to twice as much wear of the SSD.
As I assume that there won't be any disadvantages of fragemntation on an SSD I'd like to propose to deactivate this behaviour when writing to SSDs.
Thanks for this really impressive piece of software.
Last edit: Bodo Thevissen 2017-05-24
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:
Without looking at the source code, reserving file space doesn't involve actual writing, and depending on how you do it, it might not even involve writing to the file system until the file is closed. It's perfectly safe for SSD, so don't worry.
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:
~2xxMB EXE use 4 threads LZMA2 compression no problem
5xxMB/7xxMB EXE use 1~3 threads LZMA2 compression no problem
5xxMB/7xxMB EXE use 4+ threads LZMA2 compression fail
1~4GB ISO use 4+ threads LZMA2 compression no problem
Ryzen
Windows 10 Pro x64 1703
7zip 17.00 x64, parameters:7z,Ultra,LZMA2,64MB,64,4GB,4/16 threads
it's not fail.
It's incorrect progress indication for exe files.
It loads exe files to internal buffer and then it doesn't know how much work was made already.
So just wait.
And it will finish it later.
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:
Yes, progress indication and "cancel" code use same callbacks.
So working code doesn't know that you have pressed "cancel".
Now it's difficult to fix that problem.
But it's problem only for Ultra/max modes ( BCJ2 filter) for big exe files with more than 2 cpu threads.
Another cases must work OK.
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:
If you still have problems with large pages 7-Zip, you can write about it to another thread about them.
Also you can do the following test:
Install Ubuntu to another drive.
Ubuntu supports THP (transparent huge pages).
So all programs will use huge/large pages in that case.
And test how Ubuntu is stable with 7-Zip and other software there.
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:
Can 7z support different volume compression packs? For example, can support open 002, 003, currently can open only 001, if 002, 003 Volume pack has errors can not decompress, do not know that the volume pack has errors.
The WinRAR can open all of its volume packets, and the wrong volume pack prompts the specific volume pack when decompressing. 7z can also be supported, including RAR, 7z, zip volume packet decompression error prompts.
7z calibration increases sha256, sha512 support, at present MD5 and SHA1 are unsafe. Also command-line programs can support checking Sha
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:
AFAIK 7Zip works the same as WinRar in that aspect. If the volumes were compressed as 'solid compression', you need to first decompress everything before, and if it has errors, then nothing after the error can be decompressed. If you can open volumes 002 and onwards, then it wasn't a solid archive. 7Zip does solid archives by default, so what you want can't be made; it would be the same as if you asked for WinRar to open volumes after the first even for solid archives.
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:

7-Zip 17.00 beta was released.
7-Zip for 32-bit Windows:
http://7-zip.org/a/7z1700.exe
or
http://7-zip.org/a/7z1700.msi
7-Zip for 64-bit Windows x64:
http://7-zip.org/a/7z1700-x64.exe
or
http://7-zip.org/a/7z1700-x64.msi
What's new after 7-Zip 16.04:
It can reduce file fragmentation.
Thank you so much Igor. I'm glad you've listened. I can feel my code examples influenced you ;-)
Now I'll try to persuade you to include ZSTD, LZ4 and LZ5 compression methods (which are in 7-Zip ZSTD clone https://github.com/mcmilk/7-Zip-zstd).
Recently I've tested ZSTD method on this data - https://github.com/berzerk0/Probable-Wordlists - and it made my jaw drop on the floor. ZSTD method compressed this text data as good as LZMA2 but MUCH MUCH faster.
And there's this famous LZ4 with worse compression, but ASTONISHING speeds.
Please consider merging that fork into the official 7-Zip.
Have a good day.
Brotli also is a very interesting compressor. It would be nice to have support of such fast and efficient compression algorithm in the 7-zip.
Brotli is included in my 7-Zip Edition now.
Here is an overview of the compression speed vs ratio:
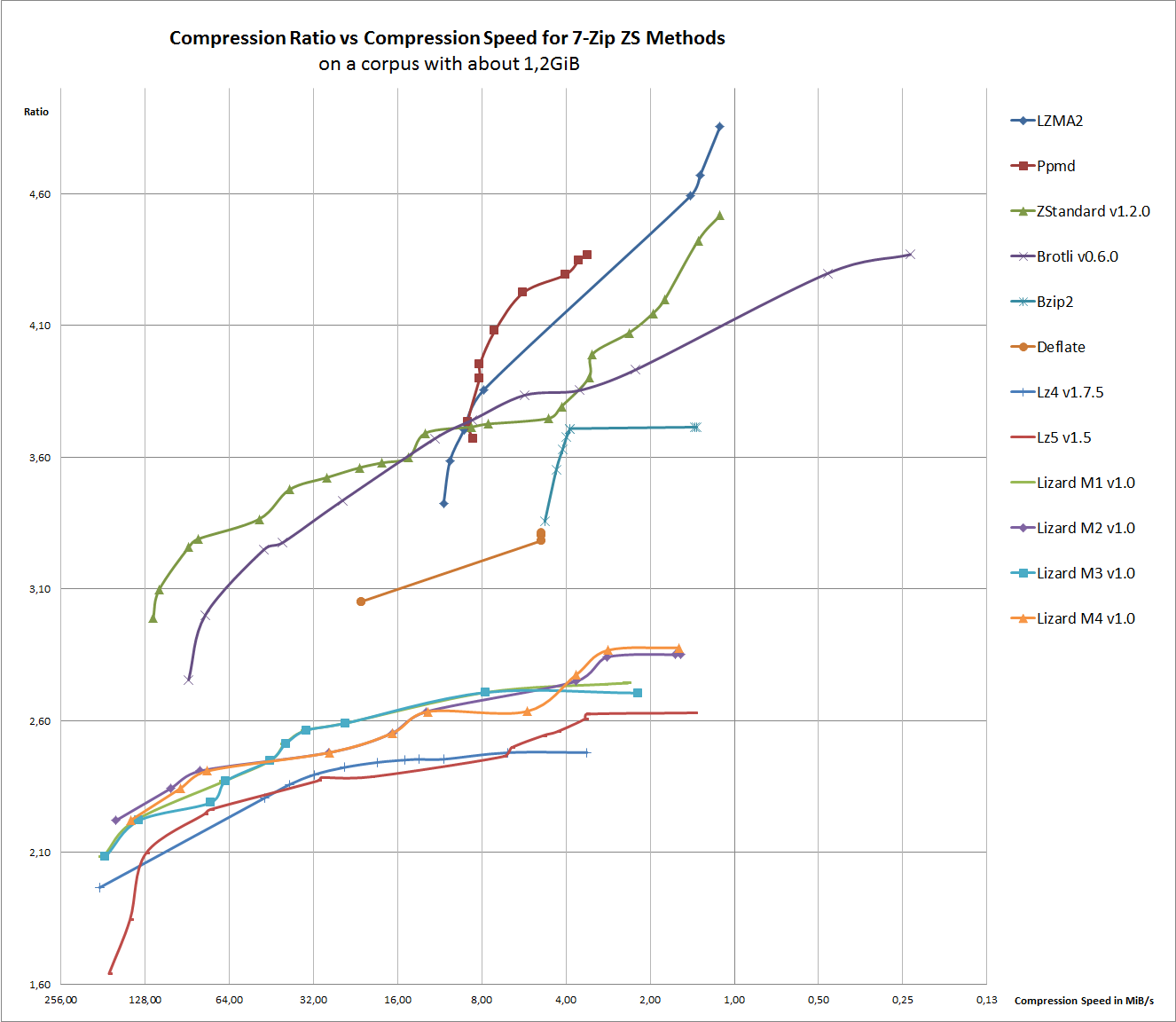
As you can see, LZMA2 is clearly the winner in terms of ratio. Thank you Igor, for this codec. But in terms of speed, there are alternatives.
Here is an overview of the decompression speed in different levels:
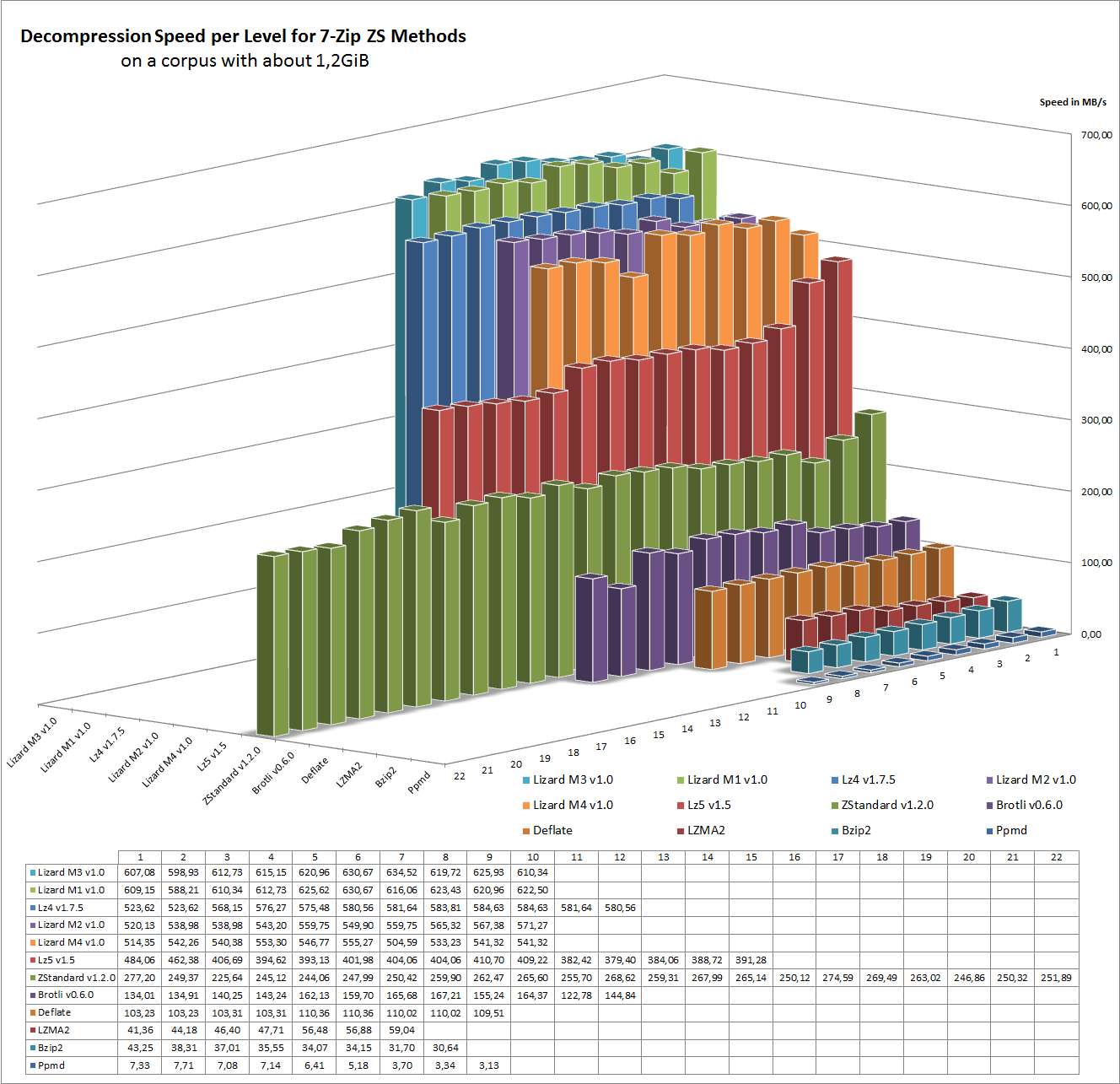
In terms of decompression speed, LZ4 and Lizard are state of the art.
The scripts I used for the benchmark are located here: https://github.com/mcmilk/7-Zip-Benchmarking/
Last edit: Tino Reichardt 2017-06-04
That graph is telling that the best agoriths are Zstd, and then Ppmd. In my tests Zstd is the best in terms of compression ratio / compression time. Only when size is really critical then Ppmd provides same ratios but taking about half the time as LZMA2.
It is clear for me that Zstd algorithm must be included in the next release of the main 7Zip project.
Oh yeah, yor graphs show us that Zstd is better than Brotli in almost all aspects. What a pity that browser developers had decided to make Brotli a standard compression algorithm in the HTTP. It seems, that Zstd would be better.
Can you add LZFSE (by Apple) and Snappy (by Google) to your comparison?
https://github.com/lzfse/lzfse
https://github.com/google/snappy
Last edit: Evgeny Vrublevsky 2017-06-10
Sorry, these two will not be included. But you can look here for some comparison of the two:
https://quixdb.github.io/squash-benchmark/unstable/
For me lzfse is sth. like an little endian only zstd 0.2... snappy seems a bit faster then zstd or brotli, but with lower ratio.
It is best to standardize on a single format that can be reliably decompressed with many different software products in the future, as well as on older computers. Zstd is the best candidate with low memory requirements and speed; it is also incluided in the self-extractor of Tino Reichardt's fork. The multiple experimental LZ formats look very confusing, and so do the memory-hungry modules explored by the FreeArc community.
Being tuned for plain-text and HTML, Brotli is unimpressive with multimedia data. Sometimes it is bested by Deflate/Ultra in ratio, and they have similar speed.
I encountered two issues with ZS 1.3.1 R1 (x86):
1) Testing a ZST or LZ4 single file for integrity from inside it with the Test button (to estimate dec. speed) fails after 1 attempt with "Malformed input."
2) Zstandard Level 22 compression produced an error upon decompression on an XP system, after 64.75 megs were correctly decompresed: "Corrupted block detected." The compressor consumed about 1 GB of memory, did not raise an error, and gave a 7z archive of slightly smaller size than Level 21 (with 512 MB of memory).
It would be good if the memory estimates were filled in (decompression of Zstd would need 32, 64, 128 for the top levels).
Last edit: J7N 2017-08-26
Can you open an issue with your two bugs.... I tried to catch them, but everything works, as it should. Please give some more details, so that I find the bug, if there is one.
Calculating the memory requirements is tricky, cause they are dynamic.... because of the threading and compressing block wise. You could watch the needed memory via wtime ...
I have to leave this issue be, because I tried ZSTD on a second computer and there it reported an Allocation Error and didn't write a file for Level 22. So this issue is mostly cosmetic...
It would still be good to read the dictionary sizes on the GUI to determine the minimum Level needed to effectively deduplicate a set of similar files. Even if the dict can't be adjusted directly.
I played some more with Brotli. At Level 11 it is significantly better on heterogenous data. I previously tried it at Level 9. But the encoding speed now is so painfully slow that I can't imagine a use for it, where the encoding computer would be so much better than the consuming computer or the network to make the waiting worthwhile. So it would be especially good to know in advance that Brotli only goes to a 16 MB dictionary.
Zstandard should normally be used up to level 17 (maximum) ... all other levels above this, will consume a lot more memory. I think about 1GB per thread for level 22... so if you have 8 Threads, level 22 will take 8GB just for compressing. This is mostly not useful. I take the levels 5 .. 11 for backup and such things ... it's very fast, and stable. It's 7-Zip ;-)
Last edit: Tino Reichardt 2017-09-10
Hi Igor,
I have read that 7-zip now usually first reserves file space. Doesn't this lead to twice as much drive writing? This may still be a wanted behaviours for normal HDDs but with SSDs this leads to twice as much wear of the SSD.
As I assume that there won't be any disadvantages of fragemntation on an SSD I'd like to propose to deactivate this behaviour when writing to SSDs.
Thanks for this really impressive piece of software.
Last edit: Bodo Thevissen 2017-05-24
I don't think so.
Windows probably can do that "Reserve" operation without real writing operation.
Without looking at the source code, reserving file space doesn't involve actual writing, and depending on how you do it, it might not even involve writing to the file system until the file is closed. It's perfectly safe for SSD, so don't worry.
Larger executable compression fail on LZMA2 4 threads or above
https://www.geforce.com/games-applications/pc-applications/a-new-dawn
~2xxMB EXE use 4 threads LZMA2 compression no problem
5xxMB/7xxMB EXE use 1~3 threads LZMA2 compression no problem
5xxMB/7xxMB EXE use 4+ threads LZMA2 compression fail
1~4GB ISO use 4+ threads LZMA2 compression no problem
Ryzen
Windows 10 Pro x64 1703
7zip 17.00 x64, parameters:7z,Ultra,LZMA2,64MB,64,4GB,4/16 threads
Last edit: RyuzenFX 2017-07-17
it's not fail.
It's incorrect progress indication for exe files.
It loads exe files to internal buffer and then it doesn't know how much work was made already.
So just wait.
And it will finish it later.
You are right, but I can't cancel this operation, click cancel box again n again,no effect.
bad experience :(
Yes, progress indication and "cancel" code use same callbacks.
So working code doesn't know that you have pressed "cancel".
Now it's difficult to fix that problem.
But it's problem only for Ultra/max modes ( BCJ2 filter) for big exe files with more than 2 cpu threads.
Another cases must work OK.
So what about "Large Pages" problem?
My system work fine (except 7zip LargePages
I run PRIME95 x64 w/LargePages, Blend stress test(custom1 thread ) but no bsod or error = =;;;
If you still have problems with large pages 7-Zip, you can write about it to another thread about them.
Also you can do the following test:
Install Ubuntu to another drive.
Ubuntu supports THP (transparent huge pages).
So all programs will use huge/large pages in that case.
And test how Ubuntu is stable with 7-Zip and other software there.
Thanks for the update, Igor.
Can 7z support different volume compression packs? For example, can support open 002, 003, currently can open only 001, if 002, 003 Volume pack has errors can not decompress, do not know that the volume pack has errors.
The WinRAR can open all of its volume packets, and the wrong volume pack prompts the specific volume pack when decompressing. 7z can also be supported, including RAR, 7z, zip volume packet decompression error prompts.
7z calibration increases sha256, sha512 support, at present MD5 and SHA1 are unsafe. Also command-line programs can support checking Sha
AFAIK 7Zip works the same as WinRar in that aspect. If the volumes were compressed as 'solid compression', you need to first decompress everything before, and if it has errors, then nothing after the error can be decompressed. If you can open volumes 002 and onwards, then it wasn't a solid archive. 7Zip does solid archives by default, so what you want can't be made; it would be the same as if you asked for WinRar to open volumes after the first even for solid archives.