Savant Code
Python Computer Vision & Video Analytics Framework With Batteries Incl
Brought to you by:
bitworkssoft
⭐ Star us on GitHub — it motivates us a lot and helps the project become more visible to developers.
Savant is an open-source, high-level framework for building real-time, streaming, highly efficient multimedia AI
applications on the Nvidia stack. It makes it possible to develop dynamic, fault-tolerant inference pipelines
that utilize the best Nvidia approaches for data center and edge accelerators very quickly.

If you are acquainted with running dockerized applications using Nvidia GPUs:
Trying the demo you will find how to craft the following showcase:

git clone https://github.com/insight-platform/Savant.git
cd Savant/samples/peoplenet_detector
# if you want to share with us where are you from
# run the following command, it is completely optional
curl --silent -O -- https://hello.savant.video/peoplenet.html
# if x86
../../utils/check-environment-compatible && docker compose -f docker-compose.x86.yml up
# if Jetson
../../utils/check-environment-compatible && docker compose -f docker-compose.l4t.yml up
# open 'rtsp://127.0.0.1:8554/city-traffic-processed' in your player
# or visit 'http://127.0.0.1:8888/city-traffic-processed/' (LL-HLS)
# Ctrl+C to stop running the compose bundle
# to get back to project root
cd ../..
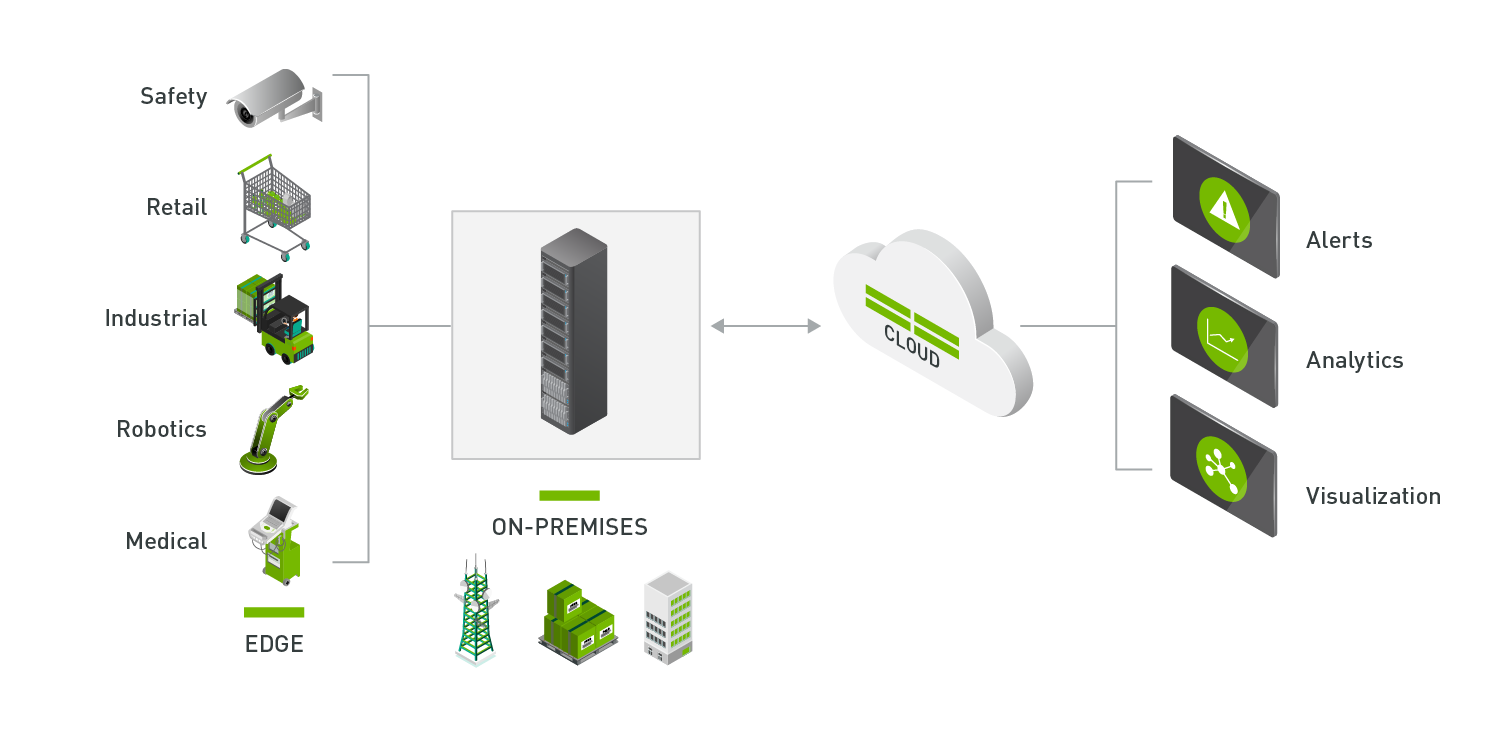
Savant is not for AI model training; it's for building fast streaming inference applications working on Edge and Core Nvidia equipment.
The one, who wants:
Nvidia DeepStream is today's most advanced toolkit for developing
high-performance real-time streaming AI applications that run several times faster than conventional AI applications
executed within the runtimes like PyTorch, TensorFlow and similar.
That has been achieved due to specially designed architecture, which uses the best Nvidia accelerator features,
including hardware encoding and decoding for video streams, moving the frames through inference blocks mostly in GPU RAM
without excessive data transfers into CPU RAM and back. It also stands on a highly optimized low-level software
stack (TensorRT) that optimizes inference operations to get the best of the
hardware used.
Why do we develop Savant if DeepStream solves the problem? Because DeepStream is a very tough and challenging to use
technology.
The root cause is that DeepStream is a bunch of plug-ins for Gstreamer - the open-source multimedia framework for
building highly-efficient streaming applications. It makes developing more or less sophisticated DeepStream applications
very difficult because the developer must understand how the Gstreamer processes the data, making the learning curve
steep and almost unreachable for ML engineers focused on model training.
Savant is a very high-level framework over the DeepStream, which hides all the Gstreamer internals from the developer
and provides practical tools for implementing real-life streaming AI applications. So, you implement your inference
pipeline as a set of declarative (YAML) blocks with several user-defined functions in Python (and C/C++ if you would
like to utilize most of the CUDA runtime).
Savant is packed with several killer features which skyrocket the development of Deepstream applications.
In DeepStream, the sources and sinks are an integral part of the Gstreamer pipeline because it's by design. However,
such a design makes it difficult to create reliable applications in the real world.
There are reasons for that. The first one is low reliability. The source and sink are external entities that, being
coupled into the pipeline, make it crash when they are failed or are no longer available. E.g., when the RTSP camera is
not available, the corresponding RTSP Gstreamer source signals the pipeline to terminate.
The problem becomes more serious when multiple sources ingest data into a single pipeline - a natural case in the real
world. You don't want to load multiple instances of the same AI models into the GPU because of RAM limitations and
overall resource overutilization. So, following the natural Gstreamer approach, you have a muxer scheme with a high
chance of failing if any source fails.
That's why you want to have sources decoupled from the pipeline - to increase the stability of the pipeline and avoid
unnecessarily reloads in case of source failure.
Another reason is dynamic source management which is a very difficult task when managed through the Gstreamer directly.
You have to implement the logic which attaches and detaches the sources and sinks when needed.
The third problem is connected with media formats. You have to reconfigure Gstremer pads setting proper capabilities
when the data source changes the format of media, e.g., switching from h.264 to HEVC codec. The simplest way to do that
is to crash and recover, which causes significant unavailability time while AI models are compiled to TensorRT and
loaded in GPU RAM. So, you want to avoid that as well.
The framework implements the handlers, which address all the mentioned problems magically without the need to manage
them someway explicitly. It helps the developer to process streams of anything without restarting the pipeline. The
video files, sets of video files, image collections, network video streams, and raw video frames (USB, GigE) - all is
processed universally (and can be mixed together) without the need to reload the pipeline to attach or detach the
stream.
The framework virtualizes the stream concept by decoupling it from the real-life data source and takes care of a garbage
collection for no longer available streams.
As a developer, you use handy source adapters to ingest media data into the framework runtime and use sink adapters to
get the results out of it. The adapters can transfer the media through the network or locally. We have already
implemented some useful in a real-life, and you can implement the required one for you if needed - the protocol is
simple and utilizes standard open source tools.
The decoupled nature of adapters also provides better reliability because the failed data source affects the adapter
operation, not a framework operation.
Sophisticated ML pipelines can use external knowledge, which helps optimize the results based on additional knowledge
from the environment.
The framework enables dynamic configuration of the pipeline operational parameters with:
Savant supports custom OpenCV CUDA bindings which allow accessing DeepStream's in-GPU frames with a broad range of OpenCV CUDA
utilities: the feature helps implement highly efficient video transformations, including but not limited to blurring, cropping, clipping, applying banners and graphical elements over the frame, and others.
To use the functionality, a developer doesn't need anything rather than Python. However, the performance is way better than what can be achieved with a naive map/change/unmap approach which is available through standard Nvidia python bindings for DeepStream.
In our practice, when we develop commercial inference software, we often meet the cases where the bounding boxes rotated
relative to a video frame (oriented bounding boxes). For example, it is often the case when the camera observes the
viewport from the ceiling when the objects reside on the floor.
Such cases require placing the objects within boxes in a way to overlap minimally. To achieve that,
we use special models that introduce bounding boxes that are not orthogonal to frame axes. Take a look
at RAPiD to get the clue.

Such models require additional post-processing, which involves the rotation - otherwise, you cannot utilize most
of the classifier models as they need orthogonal boxes as their input.
Savant supports the bounding box rotation preprocessing function out of the box. It is applied to the boxes right before
passing them to the classifier models.
The framework is designed and developed in such a way to run the pipelines on both edge Nvidia devices (Jetson Family)
and datacenter devices (like Tesla, Quadro, etc.) with minor or zero changes.
Despite the enormous efforts of Nvidia to make the devices fully compatible, there are architectural features that
require special processing to make the code compatible between discrete GPU and Jetson appliances.
Even DeepStream itself sometimes behaves unpredictably in certain conditions. The framework code handles those corner
cases to avoid crashes or misbehavior.
When running an inference application on an edge device, the developer usually wants real-time performance. Such
requirement is due to the nature of the edge - the users place devices near the live data sources like sensors or video
cameras, and they expect the device capacity is enough to handle incoming messages or video-stream without the loss.
Edge devices usually are low in computing resources, including the storage, CPU, GPU, and RAM, so their overuse is not
desired because it could lead to data loss.
On the other hand, the data transmitted to the data center are expected to be processed with latency and delay (because
the transmission itself introduces that delay and latency).
Servers deployed in the data center have a lot of resources - dozens of cores, lots of RAM, a bunch of very powerful GPU
accelerators, and a large amount of storage. It makes it possible to ingest the data to devices from the files or
message brokers (like Apache Kafka) to utilize 100% of the device, limiting the rate only by the backpressure of the
processing pipeline. Also, the data center system processes a high number of data streams in parallel - by increasing
the number of GPU accelerators installed on the server and by partitioning the data among available servers.
Savant provides the configuration means to run the pipeline in a real-time mode, which skips the data if the device is
incapable of handling them in the real-time, and in synchronous mode, which guarantees the processing of all the data in
a capacity way, maximizing the utilization of the available resources.
From a user perspective, the Savant pipeline is a self-contained service that accepts input data through Apache Avro
API. It makes Savant ideal and ready for deployment within the systems. Whether developers use provided handy adapters
or send data into a pipeline directly, both cases use API provided by the Savant.
We have implemented several ready-to-use adapters, which you can utilize as is or use as a foundation to develop your
own.
Currently, the following source adapters are available:
There are basic sink adapters implemented:
The framework uses an established protocol based on Apache Avro, both for sources and sinks. The sources and sinks talk
to Savant through ZeroMQ sockets.
The framework and the adapters are delivered as Docker images. To implement the pipeline, you take the base image, add AI
models and a custom code with extra dependencies, then build the resulting image. Some pipelines which don't require
additional dependencies can be implemented just by mapping directories with models and user functions into the docker
image.
As for now, we provide images for x86 architecture and for Jetson hardware.
We welcome anyone who wishes to contribute, report, and learn.
The In-Sight team is a ML/AI department of Bitworks Software. We develop custom high performance CV applications for various industries providing full-cycle process, which includes but not limited to data labeling, model evaluation, training, pruning, quantization, validation, and verification, pipelines development, CI/CD. We are mostly focused on Nvidia hardware (both datacenter and edge).
Contact us: info@bw-sw.com

 Denis Medyantsev
Denis Medyantsev
 Denis Medyantsev
Denis Medyantsev
 Pavel A. Tomskikh
Pavel A. Tomskikh
 Bitworks LLC
Bitworks LLC
 Oleg Abramov
Oleg Abramov