RE/flex lexical analyzer generator Wiki
The regex-centric, fast lexical analyzer generator for C++
Brought to you by:
engelen
![]()

![]()
A high-performance C++ regex library and lexical analyzer generator with Unicode support. Extends Flex++ with Unicode, indent/dedent anchors, lazy quantifiers, functions for lex and syntax error reporting and more. The RE/flex lexical analyzer generator accepts Flex lexer specifications and seamlessly integrates with Bison parsers.
See Constructing Lexical Analyzers with RE/flex - a Modern Alternative to Flex for C++ and the RE/flex User Guide for more details.
%skeleton "lalr1.cc" and Bison complete symbols.\p{C}, including Unicode identifier matching for C++11, Java, C#, and Python source code.\t (tab) widths.%class and %init to customize the generated Lexer classes.%include to modularize lexer specifications.yypush_buffer_state saves the scanner state (line, column, and indentation positions), not just the input buffer; no input buffer length limit (Flex has a 16KB limit); line() returns the current line (e.g. for error reporting)The RE/flex software is self-contained. No other libraries are required. PCRE2 and Boost.Regex are optional to use as regex engines.
The RE/flex repo includes tokenizers for Java, Python, C/C++, JSON, XML, YAML.
Use reflex/bin/reflex.exe from the command line or add a Custom Build Step in MSVC++ as follows:
select the project name in Solution Explorer then Property Pages from the View menu (see also custom-build steps in Visual Studio);
add an extra path to the reflex/include folder in the Include Directories under VC++ Directories, which should look like $(VC_IncludePath);$(WindowsSDK_IncludePath);C:\Users\YourUserName\Documents\reflex\include (this assumes the reflex source package is in your Documents folder).
enter "C:\Users\YourUserName\Documents\reflex\bin\reflex.exe" --header-file "C:\Users\YourUserName\Documents\mylexer.l" in the Command Line property under Custom Build Step (this assumes mylexer.l is in your Documents folder);
enter lex.yy.h lex.yy.cpp in the Outputs property;
specify Execute Before as PreBuildEvent.
To compile your program with MSVC++, make sure to drag the folders reflex/lib and reflex/unicode to the Source Files in the Solution Explorer panel of your project. After running reflex.exe drag the generated lex.yy.h and lex.yy.cpp files there as well. If you are using specific reflex command-line options such as --flex, add these in step 3.
You have two options: 1) quick install or 2) configure and make.
For a quick clean build assuming your environment is pretty much standard:
$ ./clean.sh
$ ./build.sh
This compiles the reflex tool and installs it locally in reflex/bin. You can add this location to your $PATH variable to enable the new reflex command:
export PATH=$PATH:/reflex_install_path/bin
The libreflex.a and libreflex.so libraries are saved locally in lib. Link against one of these libraries when you use the RE/flex regex engine in your code. The RE/flex header files are locally located in include/reflex.
To install the library and the reflex command in /usr/local/lib and /usr/local/bin:
$ sudo ./allinstall.sh
The configure script accepts configuration and installation options. To view these options, run:
$ ./configure --help
Run configure and make:
$ ./configure && make
After this successfully completes, you can optionally run make install to install the reflex command and libreflex library:
$ sudo make install
To use Boost.Regex as a regex engine with the RE/flex library and scanner generator, install Boost and link your code against libboost_regex.a
To visualize the FSM graphs generated with reflex option --graphs-file, install Graphviz dot.
There are two ways you can use this project:
For the first option, simply build the reflex tool and run it on the command line on a lex specification:
$ reflex --flex --bison --graphs-file lexspec.l
This generates a scanner for Bison from the Flex specification lexspec.l and saves the finite state machine (FSM) as a Graphviz .gv file that can be visualized with the Graphviz dot tool:
$ dot -Tpdf reflex.INITIAL.gv > reflex.INITIAL.pdf
$ open reflex.INITIAL.pdf
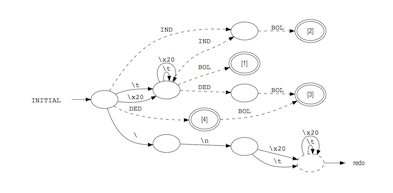
Several examples are included to get you started. See the manual for more details.
For the second option, simply use the new RE/flex matcher classes to start pattern matching on strings, wide strings, files, and streams.
You can select matchers that are based on different regex engines:
#include <reflex/matcher.h> and use reflex::Matcher;#include <reflex/boostmatcher.h> and use reflex::BoostMatcher or reflex::BoostPosixMatcher;#include <reflex/stdmatcher.h> and use reflex::StdMatcher or reflex::StdPosixMatcher.Each matcher may differ in regex syntax features (see the full documentation), but they have the same methods and iterators:
matches() returns nonzero if the input from begin to end matches;find() search input and return nonzero if a match was found;scan() scan input and return nonzero if input at current position matches;split() return nonzero for a split of the input at the next match;find.begin()...find.end() filter iterator;scan.begin()...scan.end() tokenizer iterator;split.begin()...split.end() splitter iterator.For example:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to check if the birthdate string is a valid date
if (reflex::BoostMatcher("\\d{4}-\\d{2}-\\d{2}", birthdate).matches() != 0)
std::cout << "Valid date!" << std::endl;
With a group capture to fetch the year:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to check if the birthdate string is a valid date
reflex::BoostMatcher matcher("(\\d{4})-\\d{2}-\\d{2}", birthdate);
if (matcher.matches() != 0)
std::cout << std::string(matcher[1].first, matcher[1].second) << " was a good year!" << std::endl;
To search a string for words \w+:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to search for words in a sentence
reflex::BoostMatcher matcher("\\w+", "How now brown cow.");
while (matcher.find() != 0)
std::cout << "Found " << matcher.text() << std::endl;
The split method is roughly the inverse of the find method and returns text located between matches. For example using non-word matching \W+:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to search for words in a sentence
reflex::BoostMatcher matcher("\\W+", "How now brown cow.");
while (matcher.split() != 0)
std::cout << "Found " << matcher.text() << std::endl;
To pattern match the content of a file that may use UTF-8, 16, or 32 encodings:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to search and display words from a FILE
FILE *fd = fopen("somefile.txt", "r");
if (fd == NULL)
exit(EXIT_FAILURE);
reflex::BoostMatcher matcher("\\w+", fd);
while (matcher.find() != 0)
std::cout << "Found " << matcher.text() << std::endl;
fclose(fd);
Same again, but this time with a C++ input stream:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to search and display words from a stream
std::ifstream file("somefile.txt", std::ifstream::in);
reflex::BoostMatcher matcher("\\w+", file);
while (matcher.find() != 0)
std::cout << "Found " << matcher.text() << std::endl;
file.close();
Stuffing the search results into a container using RE/flex iterators:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
#include <vector> // std::vector
// use a BoostMatcher to convert words of a sentence into a string vector
reflex::BoostMatcher matcher("\\w+", "How now brown cow.");
std::vector<std::string> words(matcher.find.begin(), matcher.find.end());
Use C++11 range-based loops with RE/flex iterators:
#include <reflex/stdmatcher.h> // reflex::StdMatcher, reflex::Input, std::regex
// use a StdMatcher to to search for words in a sentence
for (auto& match : reflex::StdMatcher("\\w+", "How now brown cow.").find)
std::cout << "Found " << match.text() << std::endl;
RE/flex also allows you to convert expressive regex syntax forms such as \p Unicode classes, character class set operations such as [a-z--[aeiou]], escapes such as \X, and (?x) mode modifiers, to a regex string that the underlying regex library understands and will be able to use:
std::string reflex::Matcher::convert(const std::string& regex)std::string reflex::BoostMatcher::convert(const std::string& regex)std::string reflex::StdMatcher::convert(const std::string& regex)For example:
#include <reflex/matcher.h> // reflex::Matcher, reflex::Input, reflex::Pattern
// use a Matcher to check if sentence is in Greek:
static const reflex::Pattern pattern(reflex::Matcher::convert("[\\p{Greek}\\p{Zs}\\pP]+"));
if (reflex::Matcher(pattern, sentence).matches() != 0)
std::cout << "This is Greek" << std::endl;
Conversion is fast (it runs in linear time in the size of the regex), but it is not without some overhead. Making converted regex patterns static as shown above saves the cost of conversion to just once to support many matchings.
You can use convert with option reflex::convert_flag::unicode to make . (dot), \w, \s and so on match Unicode.
RE/flex by Robert van Engelen, Genivia Inc.
Copyright (c) 2015-2017, All rights reserved.
RE/flex is distributed under the BSD-3 license LICENSE.txt.
Use, modification, and distribution are subject to the BSD-3 license.
