Menu
▾
▴
The 4tH preprocessor
Preprocessor architecture and background
Introduction
4tH has a preprocessor, which is rare for a Forth-like language. This article will go into the background of this preprocessor, its history and its design.
Why a preprocessor
4tH has always had a very specific philosophy concerning its architecture and design objectives:
- As small as possible;
- As fast as possible;
- As complete and versatile as possible;
- Fully C standard compliant;
- Easily portable to a wide array of platforms and environments;
- Easily extensible and embeddable;
- Easy integration with the C tool chain;
- Well documented;
- A clean and simple design.
Although 4tH comes with a fairly large library, the library itself is completely isolated from the compiler itself. True, it allows for include files by providing INCLUDE and passing parameters to include files by providing [PRAGMA], but it doesn't expect any include files, nor any constructs defined there.
This worked pretty fine until the library started to support double numbers and floating point numbers. Although it was perfectly possible to write FP programs the syntax was full of "noise" words and less than obvious constructs.
Now that was a problem. The design objectives forbid to add this kind of facilities to the compiler itself, but still some kind of support was required. The cleanest solution was to create a preprocessor which transformed ANS constructs to 4tH constructs. In other words: move all the dirty stuff to the preprocessor.
A preprocessor had been in use for C since the beginning and others (like Oracle) had added their own preprocessor to C. Even C++ had started its life as a mere preprocessor. So from an architectural point of view there was nothing wrong with this solution.
Since the 4tH preprocessor source got its own extension it was possible to write a few MAKE rules, so the preprocessor would kick in when needed:
%.c : %.4th
4th cgq $< $@
%.c : %.hx
4th lgq $< $@
%.4th : %.4pp
pp4th -o $@ $<
This made it all very transparent to the developer. The next question was: what should the preprocessor support? In short: everything ANS-Forth which couldn't or wouldn't be supported by the 4tH compiler itself. Few people are aware of it, but most ANS-Forth constructs are functionally supported by 4tH. It just requires some rewriting to make it work.
History
The first question was: in what language should the preprocessor be written? 4tH was already perfectly suited for writing tools like this. It had a standard conversion template, good parsing and excellent string support. All these tools would have to be rewritten if it was to be developed in C.
Better, a CASE..OF..ENDOF..ENDCASE converter was already available. It had an excellent structure which was well suited for expansion and experimentation. It was a good place to start. In the end, the preprocessor was simply there and the question itself became superfluous. Since 4tH is perfectly capable to produce stand alone executables and speed didn't prove to be too much of an issue (at least not on modern machines) there was no need to rewrite it.
But that wasn't the end of it. With each and every release, the preprocessor capabilities grew, up to the point that all ANS-Forth extensions could even be written in the preprocessors own language - including CASE..OF..ENDOF..ENDCASE constructs.
With the introduction of 4tH v3.62.2 the last remnants of the original CASE..OF..ENDOF..ENDCASE converter were finally removed. Some users had asked for better integration of the preprocessor in the 4tH environment.
The solution was found in expanding the capabilities to include most of the standard library functions, so a preprocessor program could be preprocessed, compiled and executed in one go. It was modeled after GCC, so the average programmer should have no trouble to familiarize himself with its calling conventions.
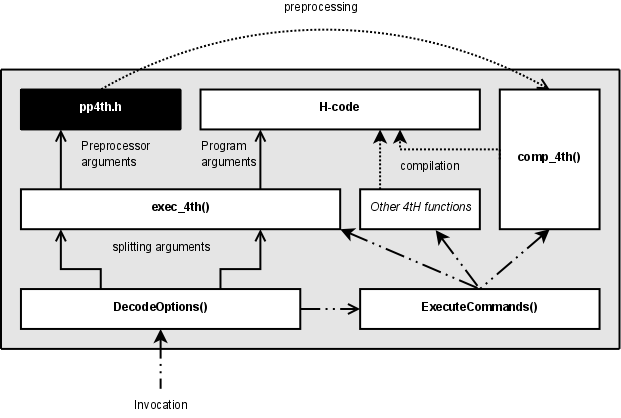
The 4tH source code of the preprocessor needed to be only marginally changed to accommodate this and is now embedded in a C program, much like the other 4tH executables (the black rectangle). It can still be converted and compiled in the classical way, if the programmer prefers.
Basic structure
The preprocessor consists of three subsystems:
- Built in keywords, including
INCLUDEsubsystem; - User defined macros, including variables;
- Reading, parsing and conversion.
Built in keywords
The built-in keywords take care of some ANS keywords, like radix modifications, strings and comments. Furthermore, it expands the include files and strips the comments.
If a keyword is encountered it simply executes the code associated with it which does all the rewriting. If it is not a keyword it is either a word the preprocessor doesn't know about or a macro. If it is the latter, the word is passed to the macro subsystem. If it is the former, it is written to the output file.
The code associated with the [NEEDS and INCLUDE keywords does a bit more. It will throw the current file and parsing information on the preprocessor include-stack and will switch to the new file. When it has finished, it will pop the information from the include stack, seek the former file position, reinstate the parsing parameters and buffers and continue processing.
This is an entirely different method of file inclusion when compared to the 4tH compiler itself. The 4tH compiler will reserve additional memory and include the file in place during the tokenizing stage, so when parsing begins, the entire file is already assembled in memory. The advantage is twofold. When file inclusion was added in the v3.3 series, the parser itself didn't need any changes to accommodate this feature (never trash well-working code). Second, 4tH can handle any level of file nesting.
The preprocessor can handle file nesting up to 32 levels deep. After that it quits. The advantage is that the preprocessor requires very little memory for file inclusion. At any moment there is only one single line in memory.
The $64,000 question is: if 4tH itself can handle file inclusion, why does the preprocessor have to handle that. After all, it doesn't feature conditional compilation as well. There are four reasons for that:
- If inclusion fails, it can serve as a debugging tool;
- It is of help in memory constrained environments, since comments are stripped as well;
- Preprocessors traditionally handle file inclusion;
- It was not too difficult to add - and cool to write;
- It made it possible to create preprocessor libraries.
The latter was certainly not intended, but it proved to be invaluable when in v3.62.2 all floating point and double number words were moved to an external preprocessor library. The new preprocessor capabilities had made this possible. Although it may seem like a minor change, it was of great importance.
Note one of the reasons for making the preprocessor had been to facilitate writing floating point programs and to avoid cluttering the compiler itself with external dependencies. In laymans terms, we had created a "clean" compiler and a "dirty" preprocessor. And now the preprocessor itself had become as clean as a whistle.
Evaluation of conditional compilation is much harder, so that is left to the compiler for the time being. The reason is that the preprocessor cannot deal with constants and arithmetic in the same way the compiler (and its optimizer) can. Chances are that even if something would be implemented, it would turn out to be bloated, buggy and unreliable.
Macros
A macro is recorded when the :MACRO keyword is encountered. At that moment the preprocessor is put into a different state where the words read aren't written to the output file, but to the macro buffer.
While words are being recorded, the internal keywords are expanded before being written to the macro buffer. Macros itself are copied verbatim. The point is that it is known how internal keywords are expanded - contrary to macros. Include files aren't allowed at all. Not only can a lengthy include file consume the entire macro buffer, it is also considered to be BAD STYLE.
When a macro is encountered during expansion all words are copied "as is" to the output file, except in the following cases:
- The word is a macro itself;
- The word is a so-called "phony variable".
If the word is a macro it is executed - simply by calling it through a recursive call. Nesting can go quite deep and the maximum level is only limited by stack space. If the word is a "phony variable" the code associated with it is called.
There are four macro variables. That may not seem like much, but there is also an entire string stack available. Macro variables should be regarded as registers. Where possible, the traditional (string) stack operators are provided. String constants can be defined using so-called "back quote expressions". These are not evaluated at all, so they may contain anything the developer wants.
The preprocessor also offers some simple branching and looping functionality, loosely based on similar constructs in ColorForth. It may seem unusual and awkward at first, but it does the job. Basically, it exits the macro without discarding the flag when the comparison renders false, e.g.:
:macro ex1 >>> 0 @if ‘ This is never printed‘ ;
:macro example ‘ Print this‘ ex1 @drop ;
example
Will only print "Print this". @if will render true when the numerical equivalent of the string on the stack is non-zero. However, the flag - either zero or non-zero - will remain on the stack, so it has to be dropped one nesting level down by calling @drop. Adding an "else" clause is possible too:
:macro ex1 >>> 0 @if ‘ This is never printed‘ ;
:macro ex2 ex1 @else ‘ But this is‘ ;
:macro example ‘ Print this‘ ex2 @drop ;
example
@else is the reverse of @if and exits the macro when the numerical equivalent of the string on the stack is non-zero, again, preserving the flag. Using @if and @else one can build "case" like constructs or even loops.
Finally, all usual preprocessor functionalities are supported, like token concatenation, string comparison, etc.
Reading, parsing and conversion
Since the preprocessor is in essence a text file converter, it uses the standard 4tH conversion template. When a file is opened, a table with known file extensions decides what kind of file it is and selects the proper reading procedure. Both block files and text files are supported. Words are read and parsed by the ANS-Forth 200x extension PARSE-NAME.
The output file is formatted by the 4tH library print.4th. Since all comments and include files have already been either resolved or removed, line breaks have no longer any significance to the compiler.
Preprocessor in practice
One of the major projects involving the preprocessor was the TEONW port. TEONW was a 14 KB Minimal BASIC program with virtually no structure at all. Special tools were written in 4tH to analyze it.
The resulting algorithms were hand coded to 4tH, because at the time the preprocessor didn't have any "infix to postfix" tools yet. These were introduced in v3.64.0 when the LET directive was added. This nifty tool allows you to write P=(406.25+(J*7.5))/12.5 and have it automatically translated to f% 406.25e J f@ f% 7.5e f* f+ f% 12.5e f/ P f!. Show me a Forth compiler that supports that out of the box!
From the very beginning it was clear that "vanilla" 4tH would not do. It would result in horrible, hard to read code, so the preprocessor was used from the very beginning. Only one single user-defined macro was needed (for the definition of FARRAY).
The only real issue encountered during this project was the need for "smart" fliterals. F% would initially simply translate to:
s" 234.56e" S>FLOAT
Which in itself was correct, but not optimal for integer fliterals, which could be translated much more efficiently by using:
1645 S>F
After the program was completed, these optimizations were applied by hand, which defeated the use of a preprocessor. After that "smart" fliterals were added, so if a conversion with NUMBER was successful, a more optimal conversion would be selected.
This made it impossible to define F% as:
: F% ; immediate
When porting a program to ANS-Forth, because ANS-Forth would recognize the number as a single cell number. Consequently, it was decided to define F% as:
: f%
bl word count >float 0= abort" Bad float"
state @ if postpone fliteral then
; immediate
So floating point conversion would be forced at compile time. Furthermore, since F% was "state smart" in 4tH programs (due to its architecture all words appear to be smart in 4tH) state smartness was added to the definition. A similar design was applied for D% which is the double number counterpart for F%. Both definitions were added to a library called ezpp4th.4th. A typical use of this library is:
[UNDEFINED] 4TH# [IF] s" lib/ezpp4th.4th" included [THEN]
So it is transparently loaded when porting a program to an ANS-Forth environment.
Verdict
As a whole, the preprocessor functioned perfectly during the development of TEONW. The extra step required to translate the source wasn't too much of a burden, neither did it get in the way when debugging the program.
Because TEONW itself is relatively small (~ 23 KB), conversion was almost instantaneous on a modern machine. How this works out on older, less powerful machines or significantly larger sources remains to be seen.
The intermediate source was rarely inspected, which proves that the connection between the preprocessor source and the resulting behavior was well preserved.
The source that resulted from the use of the preprocessor was much easier to read, maintain and understand, since the preprocessor took care of all the "noise" words.
So far, no effort has been made to port TEONW or any other preprocessor source to a full-fledged ANS-Forth environment, so how the preprocessor affects portability remains untested.
