dataflowkit Code
Golang framework for scraping data from web pages
Status: Beta
Brought to you by:
slotix
![]()


![]()
Dataflow kit extracts structured data from web pages, following the specified extractors.
It can be used in many ways for data mining, data processing or archiving.
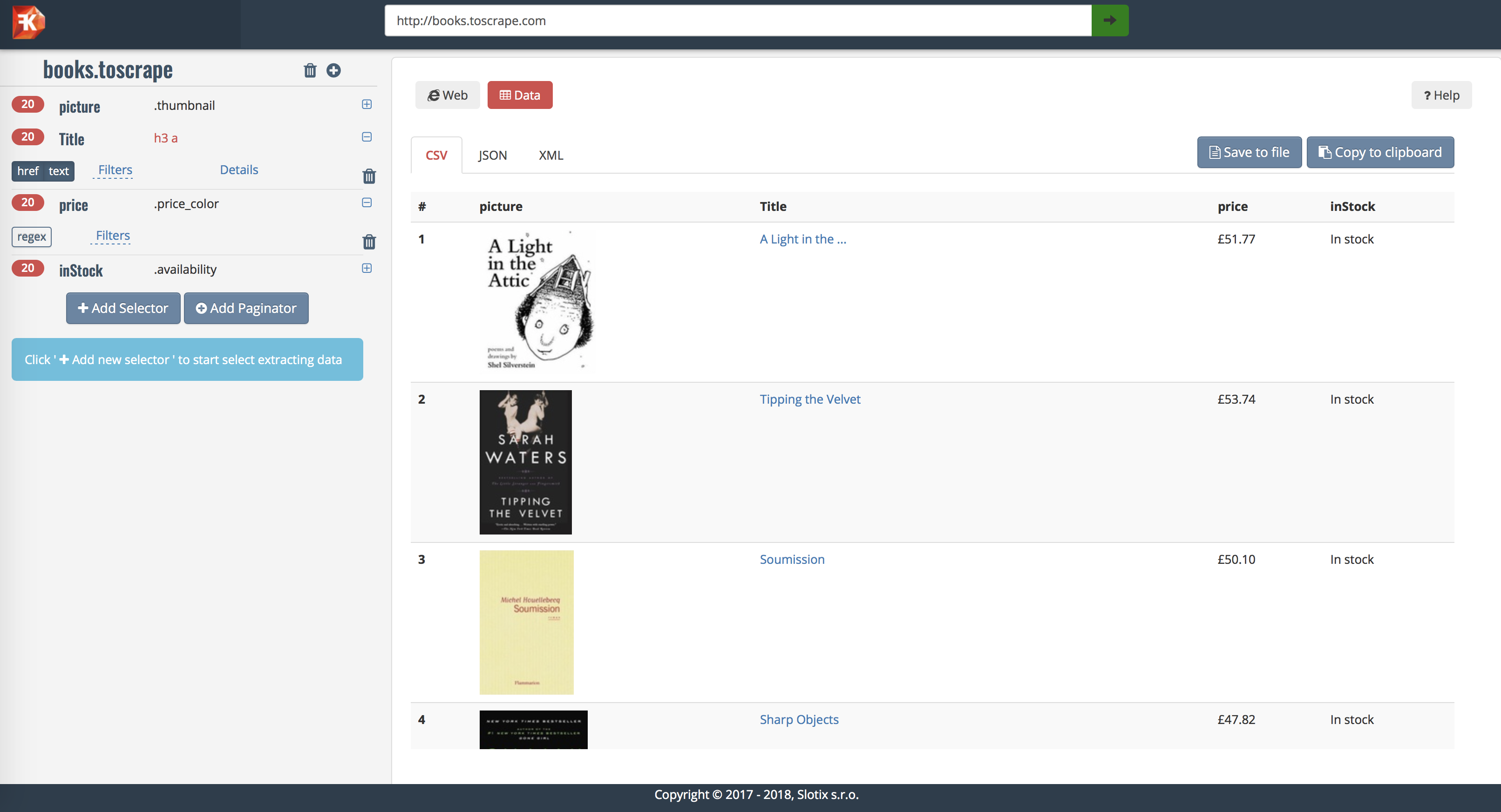
The actual use case can be grabbing list of products on several pages and follow each product’s details page to retrieve additional information. Parse endpoint returns information as a JSON, XML or CSV data.
DFK consists of two general services for fetching and parsing web pages content.
fetch.d is the daemon that downloads html pages. It sends requests to Splash server. Splash is a javascript rendering service. It is used to retrieve actual data before sending it to parse.d daemon.
parse.d is the daemon that extracts data from downloaded web page following the rules described in configuration JSON file. Extracted data are returned in CSV, JSON or XML format.
Using dep
dep ensure -add github.com/slotix/dataflowkit@master
or go get
go get -u github.com/slotix/dataflowkit
Install Docker and Docker Compose
Start services.
cd $GOPATH/src/github.com/slotix/dataflowkit && docker-compose up
This command fetches docker images automatically and starts services.
curl -XPOST 127.0.0.1:8001/parse --data-binary "@$GOPATH/src/github.com/slotix/dataflowkit/examples/books.toscrape.com.json"
Here is the sample json configuration file:
{
"name":"collection",
"request":{
"url":"https://example.com"
},
"fields":[
{
"name":"Title",
"selector":".product-container a",
"extractor":{
"types":["text", "href"],
"filters":[
"trim",
"lowerCase"
],
"params":{
"includeIfEmpty":false
}
}
},
{
"name":"Image",
"selector":"#product-container img",
"extractor":{
"types":["alt","src","width","height"],
"filters":[
"trim",
"upperCase"
]
}
},
{
"name":"Buyinfo",
"selector":".buy-info",
"extractor":{
"types":["text"],
"params":{
"includeIfEmpty":false
}
}
}
],
"paginator":{
"selector":".next",
"attr":"href",
"maxPages":3
},
"format":"json",
"paginateResults":false
}
Read more information about scraper configuration JSON files at our GoDoc reference
Extractors and filters are described at https://godoc.org/github.com/slotix/dataflowkit/extract
cd $GOPATH/src/github.com/slotix/dataflowkit && docker-compose down --remove-orphans --volumes
docker run -d -it --rm -p 5023:5023 -p 8050:8050 -p 8051:8051 scrapinghub/splash
Splash is used for fetching web pages to feed a Dataflow kit parser.
cd $GOPATH/src/github.com/slotix/dataflowkit/fetch/fetch.d && go build && ./fetch.d
cd $GOPATH/src/github.com/slotix/dataflowkit/parse/parse.d && go build && ./parse.d
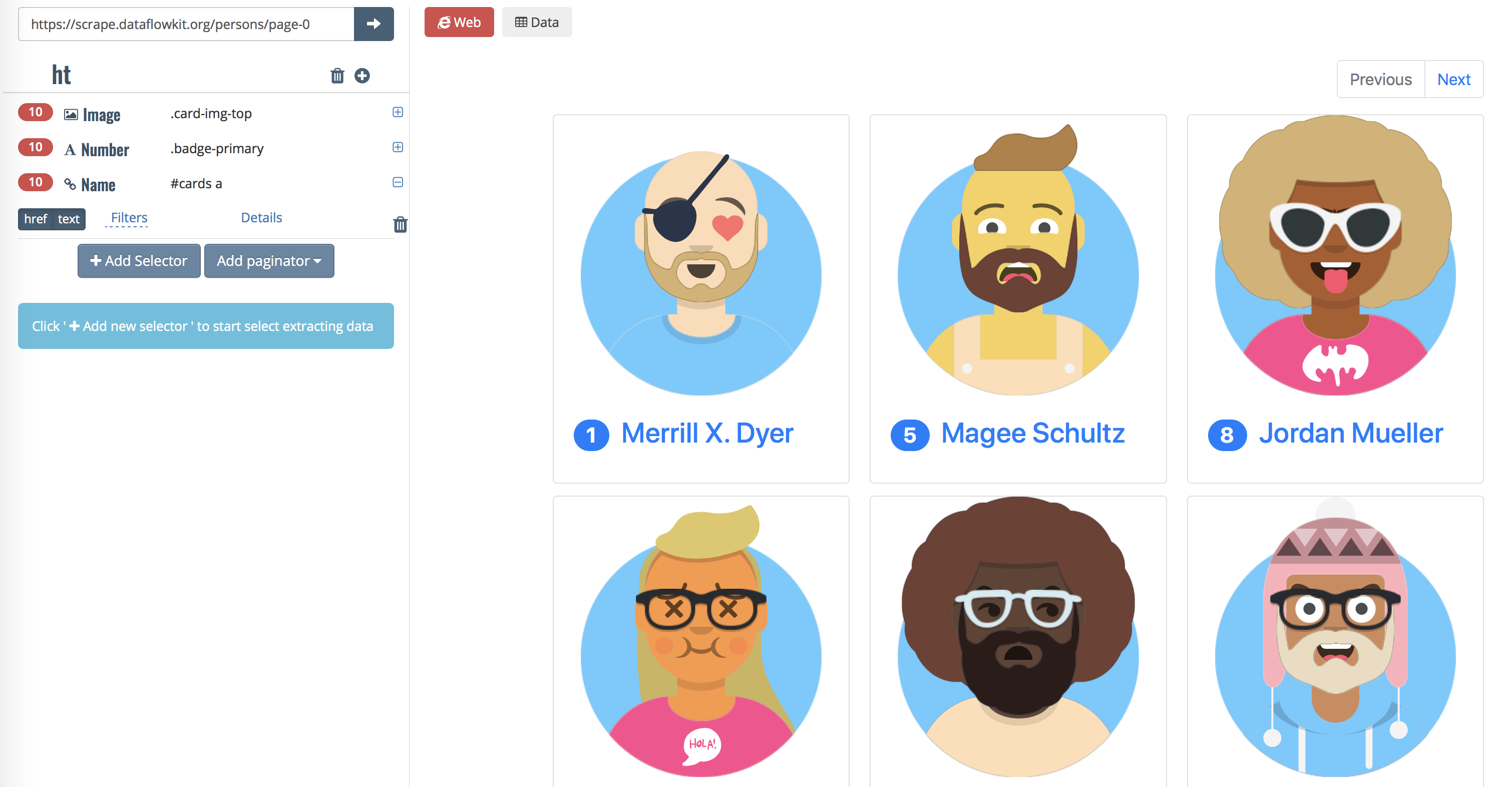
Try http://scrape.dataflowkit.org Front-end with Point-and-click interface to Dataflow kit services. It generates JSON config file and sends POST request to DFK Parser
This is Free Software, released under the BSD 3-Clause License.
You are welcome to contribute to our project.


 DMITRY NARIZHNYKH
DMITRY NARIZHNYKH