cucumber-linux-development Mailing List for Cucumber Linux (Page 2)
A general purpose desktop and server Linux distribution.
Brought to you by:
z5t1
You can subscribe to this list here.
| 2017 |
Jan
|
Feb
|
Mar
|
Apr
|
May
|
Jun
|
Jul
|
Aug
|
Sep
|
Oct
(3) |
Nov
(4) |
Dec
(1) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2018 |
Jan
|
Feb
|
Mar
(1) |
Apr
(2) |
May
(21) |
Jun
(2) |
Jul
(2) |
Aug
(1) |
Sep
(1) |
Oct
(1) |
Nov
(2) |
Dec
|
| 2019 |
Jan
(1) |
Feb
|
Mar
|
Apr
(1) |
May
(1) |
Jun
|
Jul
|
Aug
|
Sep
|
Oct
|
Nov
|
Dec
|
|
From: LM <lm...@gm...> - 2018-05-08 17:39:47
|
Using pkgapi_strip, pkgapi_make, etc. is a good idea. You may need to build on a system that can't handle parallel make calls or that uses a different name for make (such as gmake on BSD). You just need to change the buildscript file and it should work. If it I were writing this, I'd use routines for tar and some of the other utilities as well. I use a preprocessor and templates instead of functions in case I'm dealing with a system that may not have a shell that handles functions (like msh). I also mentioned I wanted the ability to concatenate using the preprocessor. In my own scripts, I do things like give the command to extract files, but also give it an extension, so it knows whether to extract a zip file or a .tar.xz file based on using decompress concatenated with the file extension and it generates the appropriate code. It works similar to passing parameters to a function. I can change between configure, autogen.sh, qmake, cmake, cdetect or other configure utilities by specifying the type of configure code I want generated. I have global locations where tools are listed so I can change them out. I may want to use tar on a system, but I also may prefer to use bsdtar or 7za. I also switch between options like sed or minised or perl for search and replace based on a global setting. One needs to regenerate the build scripts when the default tools are changed. It does give you the freedom to use the tools you prefer or the ones you have available on a system though. As to having to regenerate the build script before building a package, I have a script that goes through a simple list of packages and runs a series of steps on them, such as regenerate the build script using the template system, build the program or library, install the program or library. If I need to build a lot of packages from source, I'd rather have the whole process automated and not have to run each script by hand. I also have a script that goes through a list of packages and runs the checks for each to see if the version is updated. I've mentioned the build system I'm working on to Scott, but if anyone else on the list is interested, you can see some packages I'm working on and some sample inputs (lm bld files) and outputs (bash build scripts) for my build system here: http://www.distasis.com/cpp/lmports.htm I'm still making patches to packages and uploading them, so it's a work in progress. I definitely like the changes to the new Cucumber buildinfo format. I'd personally take it a step further and use functions or templates for common tools (like tar). MXE does that with their calls to wget and sed. Sincerely, Laura |
|
From: Scott C. <sc...@cu...> - 2018-05-08 16:45:07
|
So I've changed the buildscript-buildinfo prototype to use an API for the portions of the script that are common to all buildscripts. It is much more modular and more clean than the original prototype, but it's a little less easy to understand. What are your thoughts on the new prototype? Is it too difficult to follow? For reference: New buildscript-buildinfo format (with the API): https://github.com/cucumberlinux/new-buildscript-format/blob/master/buildscript-buildinfo-format/iproute2.buildinfo Original buildscript-buildinfo format (without the API): https://github.com/cucumberlinux/new-buildscript-format/blob/8826c60e191019bcaffb70cadd097aaf7841e975/buildscript-buildinfo-format/iproute2.buildinfo - Scott |
|
From: Scott C. <sc...@cu...> - 2018-05-08 15:38:11
|
Can confirm: the buildscript-buildinfo format will be compatible with pkgtools and will still use that as its backend. Pkgtools has always struck me as the most portable option and it's nice how it stays out of your way for the most part. It would also be a P.I.T.A. to change the package manager. I would really like whatever buildscript format we settle on to use pkgtools. If there is any objection to this speak now or forever hold your peace (or at least until we start work on Cucumber 3.0 at which point we can discuss this again). - Scott On 05/08/2018 11:07 AM, Maarten Hendrickx via Cucumber-linux-development wrote: > Hi there, I read through Laura's reply. > Could you show me a few example buildscripts or usecases? > I suggested to build a LFS ch5-like tools-chroot-tarball to use as a > way to build the next cucumber. > As long as the package format is compatible with pkgtools, things can > evolve later on in the build process. > > My own package manager experience is with pkgutils, pacman, and > cruxports4slack (https://connochaetos.org/cruxports4slack.html) among > others. > cruxports4slack adds the possibility to use Pkgfiles and even > PKGBUILD-scripts as a second option next to pkgtools. > > Adding pkgtools to LFS is very easy and can be done at the end of ch5 > so each package in ch6 is done with the package manager. > That is also how I would create a scripted automated way to build and > bootstrap cucumber 2.0. > Adding pacman involves more because it has more features. Pkgutils > needs only libarchive and some small hacks. > > The splitting up of the buildscript like Scott suggested and > demonstrated is at least very readable. > There is need for a better system/buildscript. > > Hi to all! > Maarten > > > > -----Original Message----- > From: LM <lm...@gm...> > To: cucumber-linux-development > <cuc...@li...> > Sent: Tue, May 8, 2018 2:37 pm > Subject: Re: [Cucumber-linux-development] New Buildscript Format > > On Mon, May 7, 2018 at 6:04 PM, Scott Court <sc...@cu... > <mailto:sc...@cu...>> wrote: > > The original buildscript format was heavily inspired by the Slackware > > .SlackBuild format. > > I started experimenting with the SlackBuild format several years ago. > I like it better than many other Linux build systems, but one > immediate drawback was that if something changed in the scripts, you > had to change it by hand everywhere. There were some nice tools that > helped create the script in the first place, but the tools didn't > modify a created script if a change needed to be made globally. > > > It doesn't use any form of templates. This means it is not possible > to make > > any sort of global change without manually editing every single > buildscript. > > It doesn't sufficiently track information about the package's > upstream. For > > example, it would be very helpful if the build system could track > (amongst > > other things): > > There are different ways to factor out the common code so that it's > not repeated by hand in each build script. One way is similar to what > Arch Linux does, where there's a compiled tool that does most of the > work and you just need to supply the basic information to build the > package. The other way is to use a scripting language instead of a > compiled program. Arch Linux users like that their system is fast and > efficient. If a program is compiled, it's typically going to be more > efficient than a scripting language. However, if you're changing > something often or debugging, it's much easier to work with a > scripting language. My personal choice with the build system I'm > currently using is to go with a scripting language. I felt the > flexibility was more important than the speed for my particular > situation. I expect things to change often and I don't expect them to > stabilize any time soon. > > If one goes with a scripting language, one also needs to decide which > scripting language to use or if you want to come up with a syntax that > does not tie you down to any particular scripting language. Slackware > uses shell/bash style scripting. BSD make systems typically use BSD > make ( http://bsdbuild.hypertriton.com// ). I've seen some projects > use JavaScript for scripting. My original idea was to not tie my > system down to any particular scripting language. So, one would use a > common syntax that can generate the desired scripting language using > templates. However, bash or sh are available on most platforms I work > with and I ended up using some less portable syntax in certain cases > and working mainly with bash/sh as the scripting language of choice > similar to Slackware Slackbuilds. I could change the decision in the > future, but it would take some modifications to the individual build > scripts. > > I also knew I wanted to use a template based system, so the next step > after deciding on a language was to decide what tool to use for > working with/updating templates. As a C/C++ programmer, one of the > more familiar template systems is just using a preprocessor. However, > I absolutely wanted the ability to concatenate variables and be able > to interpret the results of the concatenation as another variable. I > could reinvent the wheel and write my own template engine, but there > are already several out there. I ended up using gpp ( > https://files.nothingisreal.com/software/gpp/gpp.html ). It's very > similar to a C preprocessor with similar syntax. However, it does a > few things a C preprocessor isn't capable of doing. It doesn't have > all the functionality I would like in an ideal situation, but it has > the minimum I needed. > > Using a template based system, I still end up creating one build > script per package (similar to a Slackbuild script). I find it > convenient for sharing build scripts to be able to just give someone > the actual script and it has everything they need to complete the > build. With a system like Arch, you'd need to supply the build tools > and the package information (partial script) to recreate a build. > > I also tried to modularize everything as much as possible. It's not > the easiest code to read, but I basically use the preprocessor and > macros like one might use functions in a programming language. I try > to factor out repeated code. If I find I need to put the same exact > information in each package's build script, then I know I'm doing > something wrong. Repeated information should be part of the template > code or kept globally somewhere. > > > What the upstream URL is for a project. > > The MXE project uses a clever way to track when a project is updated. > It isn't maintenance free, but it makes it easier to track when an > upstream project changes than to have to check every project by going > to each URL and looking for changes. They do a wget on the URL where > information on the project version resides and parse the version > number out. If the version doesn't match the version of the package > they're expecting, they know it's time to look into updating the build > script. There's an example of one of their build scripts including > the update code here: > https://github.com/mxe/mxe/blob/master/src/curl.mk > > > What the signature/checksum of the source tarball is. > > I think most build systems include ability to validate checksums > including what MXE and ARCH use. With my own system, I can specify > what type of checksum I'm using for a specific package, (sha1sum, > sha256sum, etc.). That way, if a project supplies some type of > checksum, I can use whatever they do. > > The way I know if I'm on the right track with my design is by seeing > how fast it can adapt to changes. When I update a package, if it's > just a minor update it may just take changing the version number, > regenerating and rerunning the build script and it'll fetch the new > version of the source code and build. Major changes to build a > package may take several hours or even a few days. However, they'd > take as long if I wasn't using a build script and it would be much > harder to recreate what I'd done or give the steps to someone else to > reproduce. I recently changed my build system to handle > cross-compiling in order to build packages for Android. It took at > least a few days to add all the features I wanted. However, once I > updated my build scripts, build time for producing an Android apk went > down significantly. Also, my system was flexible enough to adapt to > the new situation even if it did require some major modifications in a > few areas. > > I went through a lot of pros and cons when designing a build system > for my own use and I did a lot of investigating what other build > systems did to see if I could use them or ideas from them and not > completely reinvent the wheel. It would have been nice to discuss the > pros and cons of various build system designs with others, but I > really didn't have any luck finding other developers who were > interested in that sort of thing. I'll be very interested to read > about the design decisions that go into the new Cucumber Linux build > system. I did try to have a clear idea of my main design goals before > starting. I also did a lot of research on the various trade-offs of > design decisions. I'm sure what I decided wouldn't necessarily be the > most popular choices, but I went with what was practical and would > work best for my situation. > > I look forward to reading how the Cucumber Linux build system progresses. > > Sincerely, > Laura > > ------------------------------------------------------------------------------ > Check out the vibrant tech community on one of the world's most > engaging tech sites, Slashdot.org! http://sdm.link/slashdot > _______________________________________________ > Cucumber-linux-development mailing list > Cuc...@li... > <mailto:dev...@li...> > https://lists.sourceforge.net/lists/listinfo/cucumber-linux-development > > > ------------------------------------------------------------------------------ > Check out the vibrant tech community on one of the world's most > engaging tech sites, Slashdot.org! http://sdm.link/slashdot > > > _______________________________________________ > Cucumber-linux-development mailing list > Cuc...@li... > https://lists.sourceforge.net/lists/listinfo/cucumber-linux-development |
|
From: Scott C. <sc...@cu...> - 2018-05-08 15:20:31
|
On 05/08/2018 08:37 AM, LM wrote: > On Mon, May 7, 2018 at 6:04 PM, Scott Court <sc...@cu...> wrote: >> The original buildscript format was heavily inspired by the Slackware >> .SlackBuild format. > I started experimenting with the SlackBuild format several years ago. > I like it better than many other Linux build systems, but one > immediate drawback was that if something changed in the scripts, you > had to change it by hand everywhere. There were some nice tools that > helped create the script in the first place, but the tools didn't > modify a created script if a change needed to be made globally. > >> It doesn't use any form of templates. This means it is not possible to make >> any sort of global change without manually editing every single buildscript. >> It doesn't sufficiently track information about the package's upstream. For >> example, it would be very helpful if the build system could track (amongst >> other things): > There are different ways to factor out the common code so that it's > not repeated by hand in each build script. One way is similar to what > Arch Linux does, where there's a compiled tool that does most of the > work and you just need to supply the basic information to build the > package. The other way is to use a scripting language instead of a > compiled program. Arch Linux users like that their system is fast and > efficient. If a program is compiled, it's typically going to be more > efficient than a scripting language. However, if you're changing > something often or debugging, it's much easier to work with a > scripting language. My personal choice with the build system I'm > currently using is to go with a scripting language. I felt the > flexibility was more important than the speed for my particular > situation. I expect things to change often and I don't expect them to > stabilize any time soon. I'm planning use a scripting language instead of a compiled program for those reasons, and also because of the increased portability that comes with using a script instead of a compiled program. I also think that having a build system that's easy to work with, modify and port is more important than having one that runs quickly. > If one goes with a scripting language, one also needs to decide which > scripting language to use or if you want to come up with a syntax that > does not tie you down to any particular scripting language. Slackware > uses shell/bash style scripting. BSD make systems typically use BSD > make ( http://bsdbuild.hypertriton.com// ). I've seen some projects > use JavaScript for scripting. My original idea was to not tie my > system down to any particular scripting language. So, one would use a > common syntax that can generate the desired scripting language using > templates. However, bash or sh are available on most platforms I work > with and I ended up using some less portable syntax in certain cases > and working mainly with bash/sh as the scripting language of choice > similar to Slackware Slackbuilds. I could change the decision in the > future, but it would take some modifications to the individual build > scripts. All of the buildscripts for Cucumber Linux 1.x are already written in Bash, so it would probably be easiest to stick with that. > I also knew I wanted to use a template based system, so the next step > after deciding on a language was to decide what tool to use for > working with/updating templates. As a C/C++ programmer, one of the > more familiar template systems is just using a preprocessor. However, > I absolutely wanted the ability to concatenate variables and be able > to interpret the results of the concatenation as another variable. I > could reinvent the wheel and write my own template engine, but there > are already several out there. I ended up using gpp ( > https://files.nothingisreal.com/software/gpp/gpp.html ). It's very > similar to a C preprocessor with similar syntax. However, it does a > few things a C preprocessor isn't capable of doing. It doesn't have > all the functionality I would like in an ideal situation, but it has > the minimum I needed. One approach I'm thinking of is to turn the repeated sections into Bash functions and effectively make a Bash API for the buildsystem. The *.buildinfo files would then source this API and use the Bash functions. My main concern with this approach is its impact on readability, since it would effectively replace easy to understand Bash commands with function calls that a developer would then have to look up. This issue can be at least partially mitigated though by commenting all of the functions calls well. The other option is of course to use a preprocessor like you said, but then that would require one to re-preprocess the buildscript every time a change is made to it. I'm worried that someone (i.e. me) may forget to do this at some point and break stuff as a result. It also adds another dependency to the buildsystem (the preprocessor). This approach does result in a more readable final result (if done properly); however, it is not editable in it's final form: you still have to edit it in terms of macros. From an editing standpoint it looks like they're similar. Like you said the macros behave similarly to functions in this case. I think I'm leaning more towards the Bash API though since it removes the need to re-preprocess. Also, if a change to the API is made with the Bash approach, there's no need to re-preprocess anything; you just have to replace all the old API bash source files with the new ones and call it a day. With a preprocessor, it would be necessary to re-preprocess every single buildscript whenever this happens. Your thoughts? > Using a template based system, I still end up creating one build > script per package (similar to a Slackbuild script). I find it > convenient for sharing build scripts to be able to just give someone > the actual script and it has everything they need to complete the > build. With a system like Arch, you'd need to supply the build tools > and the package information (partial script) to recreate a build. That is one minor drawback of the buildscript-buildinfo approach (https://github.com/cucumberlinux/new-buildscript-format/tree/master/buildscript-buildinfo-format): it requires you to distribute two scripts instead of one. That being the case though, it's already necessary to redistribute the slack-desc and doinst.sh files with each buildscript in order for it to be usable anyway. So I'm not sure adding another file is a huge issue since you already have to distribute more than one. > I also tried to modularize everything as much as possible. It's not > the easiest code to read, but I basically use the preprocessor and > macros like one might use functions in a programming language. I try > to factor out repeated code. If I find I need to put the same exact > information in each package's build script, then I know I'm doing > something wrong. Repeated information should be part of the template > code or kept globally somewhere. Agreed. I definitely want to make that sort of stuff global. That's what I was thinking with the API. >> What the upstream URL is for a project. > The MXE project uses a clever way to track when a project is updated. > It isn't maintenance free, but it makes it easier to track when an > upstream project changes than to have to check every project by going > to each URL and looking for changes. They do a wget on the URL where > information on the project version resides and parse the version > number out. If the version doesn't match the version of the package > they're expecting, they know it's time to look into updating the build > script. There's an example of one of their build scripts including > the update code here: > https://github.com/mxe/mxe/blob/master/src/curl.mk > >> What the signature/checksum of the source tarball is. > I think most build systems include ability to validate checksums > including what MXE and ARCH use. With my own system, I can specify > what type of checksum I'm using for a specific package, (sha1sum, > sha256sum, etc.). That way, if a project supplies some type of > checksum, I can use whatever they do. We could definitely use something like that. Currently, I track most packages by hand and it can be quite tedious at times, so thanks. I'll add implementing something like this to the To Do List. Not a top priority for now, but adding the version/URL/checksum/signature information to the new buildsystem will make this substantially easier to implement in the future. > The way I know if I'm on the right track with my design is by seeing > how fast it can adapt to changes. When I update a package, if it's > just a minor update it may just take changing the version number, > regenerating and rerunning the build script and it'll fetch the new > version of the source code and build. Major changes to build a > package may take several hours or even a few days. However, they'd > take as long if I wasn't using a build script and it would be much > harder to recreate what I'd done or give the steps to someone else to > reproduce. I recently changed my build system to handle > cross-compiling in order to build packages for Android. It took at > least a few days to add all the features I wanted. However, once I > updated my build scripts, build time for producing an Android apk went > down significantly. Also, my system was flexible enough to adapt to > the new situation even if it did require some major modifications in a > few areas. > > I went through a lot of pros and cons when designing a build system > for my own use and I did a lot of investigating what other build > systems did to see if I could use them or ideas from them and not > completely reinvent the wheel. It would have been nice to discuss the > pros and cons of various build system designs with others, but I > really didn't have any luck finding other developers who were > interested in that sort of thing. I'll be very interested to read > about the design decisions that go into the new Cucumber Linux build > system. I did try to have a clear idea of my main design goals before > starting. I also did a lot of research on the various trade-offs of > design decisions. I'm sure what I decided wouldn't necessarily be the > most popular choices, but I went with what was practical and would > work best for my situation. > > I look forward to reading how the Cucumber Linux build system progresses. > > Sincerely, > Laura Thank you, glad to have your expertise. - Scott |
|
From: Maarten H. <maa...@ao...> - 2018-05-08 15:07:29
|
Hi there, I read through Laura's reply. Could you show me a few example buildscripts or usecases? I suggested to build a LFS ch5-like tools-chroot-tarball to use as a way to build the next cucumber. As long as the package format is compatible with pkgtools, things can evolve later on in the build process. My own package manager experience is with pkgutils, pacman, and cruxports4slack (https://connochaetos.org/cruxports4slack.html) among others. cruxports4slack adds the possibility to use Pkgfiles and even PKGBUILD-scripts as a second option next to pkgtools. Adding pkgtools to LFS is very easy and can be done at the end of ch5 so each package in ch6 is done with the package manager. That is also how I would create a scripted automated way to build and bootstrap cucumber 2.0. Adding pacman involves more because it has more features. Pkgutils needs only libarchive and some small hacks. The splitting up of the buildscript like Scott suggested and demonstrated is at least very readable. There is need for a better system/buildscript. Hi to all! Maarten |
|
From: LM <lm...@gm...> - 2018-05-08 12:37:17
|
On Mon, May 7, 2018 at 6:04 PM, Scott Court <sc...@cu...> wrote: > The original buildscript format was heavily inspired by the Slackware > .SlackBuild format. I started experimenting with the SlackBuild format several years ago. I like it better than many other Linux build systems, but one immediate drawback was that if something changed in the scripts, you had to change it by hand everywhere. There were some nice tools that helped create the script in the first place, but the tools didn't modify a created script if a change needed to be made globally. > It doesn't use any form of templates. This means it is not possible to make > any sort of global change without manually editing every single buildscript. > It doesn't sufficiently track information about the package's upstream. For > example, it would be very helpful if the build system could track (amongst > other things): There are different ways to factor out the common code so that it's not repeated by hand in each build script. One way is similar to what Arch Linux does, where there's a compiled tool that does most of the work and you just need to supply the basic information to build the package. The other way is to use a scripting language instead of a compiled program. Arch Linux users like that their system is fast and efficient. If a program is compiled, it's typically going to be more efficient than a scripting language. However, if you're changing something often or debugging, it's much easier to work with a scripting language. My personal choice with the build system I'm currently using is to go with a scripting language. I felt the flexibility was more important than the speed for my particular situation. I expect things to change often and I don't expect them to stabilize any time soon. If one goes with a scripting language, one also needs to decide which scripting language to use or if you want to come up with a syntax that does not tie you down to any particular scripting language. Slackware uses shell/bash style scripting. BSD make systems typically use BSD make ( http://bsdbuild.hypertriton.com// ). I've seen some projects use JavaScript for scripting. My original idea was to not tie my system down to any particular scripting language. So, one would use a common syntax that can generate the desired scripting language using templates. However, bash or sh are available on most platforms I work with and I ended up using some less portable syntax in certain cases and working mainly with bash/sh as the scripting language of choice similar to Slackware Slackbuilds. I could change the decision in the future, but it would take some modifications to the individual build scripts. I also knew I wanted to use a template based system, so the next step after deciding on a language was to decide what tool to use for working with/updating templates. As a C/C++ programmer, one of the more familiar template systems is just using a preprocessor. However, I absolutely wanted the ability to concatenate variables and be able to interpret the results of the concatenation as another variable. I could reinvent the wheel and write my own template engine, but there are already several out there. I ended up using gpp ( https://files.nothingisreal.com/software/gpp/gpp.html ). It's very similar to a C preprocessor with similar syntax. However, it does a few things a C preprocessor isn't capable of doing. It doesn't have all the functionality I would like in an ideal situation, but it has the minimum I needed. Using a template based system, I still end up creating one build script per package (similar to a Slackbuild script). I find it convenient for sharing build scripts to be able to just give someone the actual script and it has everything they need to complete the build. With a system like Arch, you'd need to supply the build tools and the package information (partial script) to recreate a build. I also tried to modularize everything as much as possible. It's not the easiest code to read, but I basically use the preprocessor and macros like one might use functions in a programming language. I try to factor out repeated code. If I find I need to put the same exact information in each package's build script, then I know I'm doing something wrong. Repeated information should be part of the template code or kept globally somewhere. > What the upstream URL is for a project. The MXE project uses a clever way to track when a project is updated. It isn't maintenance free, but it makes it easier to track when an upstream project changes than to have to check every project by going to each URL and looking for changes. They do a wget on the URL where information on the project version resides and parse the version number out. If the version doesn't match the version of the package they're expecting, they know it's time to look into updating the build script. There's an example of one of their build scripts including the update code here: https://github.com/mxe/mxe/blob/master/src/curl.mk > What the signature/checksum of the source tarball is. I think most build systems include ability to validate checksums including what MXE and ARCH use. With my own system, I can specify what type of checksum I'm using for a specific package, (sha1sum, sha256sum, etc.). That way, if a project supplies some type of checksum, I can use whatever they do. The way I know if I'm on the right track with my design is by seeing how fast it can adapt to changes. When I update a package, if it's just a minor update it may just take changing the version number, regenerating and rerunning the build script and it'll fetch the new version of the source code and build. Major changes to build a package may take several hours or even a few days. However, they'd take as long if I wasn't using a build script and it would be much harder to recreate what I'd done or give the steps to someone else to reproduce. I recently changed my build system to handle cross-compiling in order to build packages for Android. It took at least a few days to add all the features I wanted. However, once I updated my build scripts, build time for producing an Android apk went down significantly. Also, my system was flexible enough to adapt to the new situation even if it did require some major modifications in a few areas. I went through a lot of pros and cons when designing a build system for my own use and I did a lot of investigating what other build systems did to see if I could use them or ideas from them and not completely reinvent the wheel. It would have been nice to discuss the pros and cons of various build system designs with others, but I really didn't have any luck finding other developers who were interested in that sort of thing. I'll be very interested to read about the design decisions that go into the new Cucumber Linux build system. I did try to have a clear idea of my main design goals before starting. I also did a lot of research on the various trade-offs of design decisions. I'm sure what I decided wouldn't necessarily be the most popular choices, but I went with what was practical and would work best for my situation. I look forward to reading how the Cucumber Linux build system progresses. Sincerely, Laura |
|
From: Scott C. <sc...@cu...> - 2018-05-07 22:03:33
|
Hello All,
As I have previously alluded to and as most of you probably already
know, we will be changing the buildscript format for Cucumber Linux 2.0.
This is something that every developer I have spoken to has suggested
doing, so hopefully this won't be too controversial a decision. Here is
my rationale behind it:
The original buildscript format was heavily inspired by the Slackware
.SlackBuild format. This allowed for the entire buildscript to be
located in a single file that could be run on its own, without the
presence of a build infrastructure. While this is convenient, it has
started to become a little unmanageable for the following reasons:
* It doesn't use any form of templates. This means it is not possible
to make any sort of global change without manually editing every
single buildscript.
* It doesn't sufficiently track information about the package's
upstream. For example, it would be very helpful if the build system
could track (amongst other things):
o What the upstream URL is for a project.
o What the signature/checksum of the source tarball is.
o What PGP keys are valid for signing each package's source tarballs.
I have created a git repository at
https://github.com/cucumberlinux/new-buildscript-format. This repository
will hold prototypes for all of the contenders for the new format.
Currently, there is one new format in there that I have started working
on: buildscript-buildinfo
(https://github.com/cucumberlinux/new-buildscript-format/tree/master/buildscript-buildinfo-format).
There is a README in that directory explaining how it works. Please feel
free to comment away either on this mailing list or on GitHub. Also,
feel free to fork the repository and modify my prototype or make your own.
If possible, I would ideally like to decide on a new buildscript format
by 2018-05-14 so that we can move forward with starting on the ports
tree (see
https://sourceforge.net/p/cucumber-linux/mailman/message/36296253/);
however, this is a large decision so I don't want to rush the process
too much: if it takes a little longer that's ok. Also we will be
starting work on the ports tree before we start work on Cucumber Linux
2.0. This will allow us to use the ports tree as a testing ground for
the new buildscript format before it becomes set in stone.
- Scott
|
|
From: Scott C. <sc...@cu...> - 2018-05-07 15:35:53
|
Hello all, I have created a page on the Cucumber Linux Wiki outlining the roadmap for the Cucumber Linux 2.0 development/release cycle a little more thoroughly. It contains much more detail about which specific packages need to be updated/changed/added/removed and what other tasks will need to be done. It's viewable at https://z5t1.com/cucumber/wiki/devdocs:2_0_roadmap. - Scott |
|
From: Scott C. <sc...@cu...> - 2018-04-17 16:58:06
|
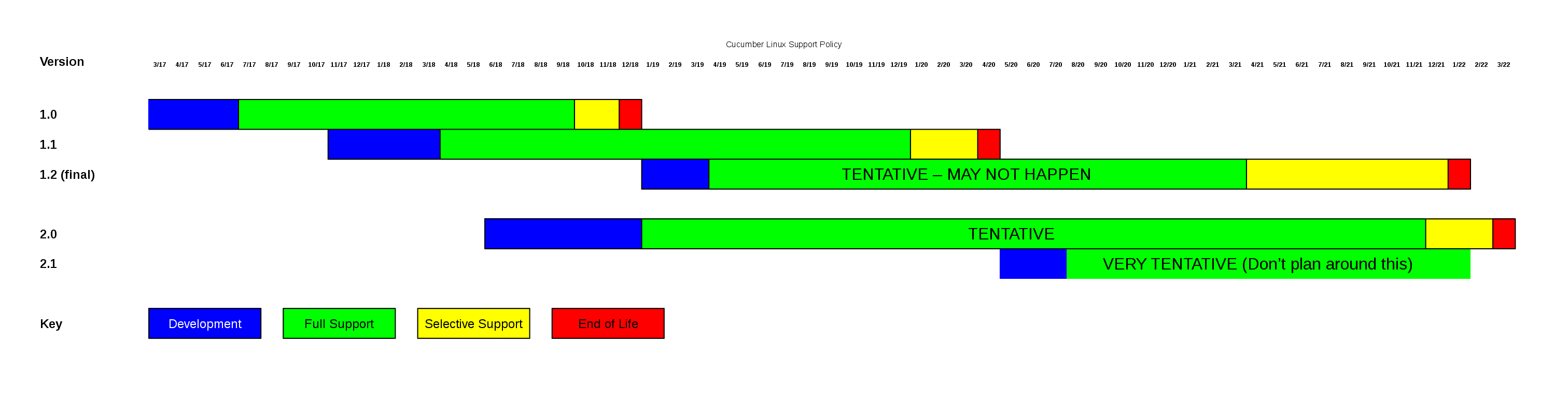
Hello all, It's been a while. Consequentially, this will be a long email. I apologize in advance for this, but all of the information in here is quite important, so please read all the way through it. Believe it or not it is already time to start talking about *Cucumber Linux 2.0* now that Cucumber Linux 1.1 has been released. Unfortunately, our current infrastructure is not powerful enough to maintain Cucumber Linux 1.0 and 1.1 and develop Cucumber Linux 2.0 simultaneously. I will be substantially upgrading our infrastructure in the next couple of months, after which we will be able to handle all three versions simultaneously without infrastructure issue; however, until the upgrade is complete, we will not have a development branch of Cucumber Linux. The upgrade should be finished some time in June, so hold tight until then. In the meantime don't fret, there are plenty of *other things to do*. First, we can plan what *versions of the core packages* (see https://cucumberlinux.com/support_policy.php) we will use for Cucumber Linux 2.0. This requires careful research to ensure that all of the versions of the core packages will be supported for a reasonable amount of time, allowing us to fully support Cucumber Linux 2.0 for as long as possible. I have already started researching this, and a spreadsheet outlining what I have found can be found at https://cucumberlinux.com/~scott/release_proposals/2.x%20Package%20Version%20Information%20DRAFT%201.html <https://cucumberlinux.com/%7Escott/release_proposals/2.x%20Package%20Version%20Information%20DRAFT%201.html>. I encourage you to double check my work here because it's very important we get this right. Also, let me know if there are any packages you think should be classified as core packages that are not listed on that spreadsheet. It's looking like the following will be our (very tentative) release schedule for Cucumber Linux 2.0: June 2018 - Active development begins; cucumber-2.0 branched off of cucumber-1.1. January 2019 - Cucumber Linux 2.0 released. November 29, 2021 - Cucumber Linux 2.0 End of Full Support. March 1, 2022 - Cucumber Linux 2.0 End of Life. This is all subject to change, so don't get too worked up over any of these dates (especially the release date; that one is the most flexible). For a more visual depiction of this see https://cucumberlinux.com/~scott/release_proposals/1.x%20&%202.x%20Release%20Cycles%20DRAFT%201.png <https://cucumberlinux.com/%7Escott/release_proposals/1.x%20&%202.x%20Release%20Cycles%20DRAFT%201.png>. Second, *the Ports Tree*. As everyone is probably well aware, the current Cucumber Linux ports tree leaves a lot to be desired. I have spoken to various people, and most people have indicated that the reason they don't use Cucumber Linux more is one of the following: the lack of documentation, or the lack of easily installable third party packages. While we are waiting to start building Cucumber Linux 2.0, I would like to work on addressing these two issues. Everyone seems to have one or two packages he absolutely needs that is not part of the official distribution. What I have in mind is creating a ports tree hosted in a Git repository, containing buildscripts and makefiles for building third party packages. This would allow several people to easily create and update different package ports. Otherwise, it would continue to work much the same as the current ports tree, which works similarly to the FreeBSD/OpenBSD ports trees. From an end user perspective, you would just have to `cd /usr/ports/<package> && make install` to install the package. I'm still working on flushing out the details (expect another lengthy email once that's done). If you have any thoughts or ideas, drop me an email or ping me on IRC. Third, *Documentation*. I have resumed my endeavor to write /The Hitchhiker's Guide to Cucumber Linux/, a book going over the basics of Cucumber Linux system administration. I have published the first preview draft at https://cucumberlinux.com/~scott/documentation/DRAFT%20PREVIEW%201%20-%20The%20Hitchhiker's%20Guide%20to%20Cucumber%20Linux%201.1.pdf <https://cucumberlinux.com/%7Escott/documentation/DRAFT%20PREVIEW%201%20-%20The%20Hitchhiker%27s%20Guide%20to%20Cucumber%20Linux%201.1.pdf>. Any and all feedback is welcome. If you'd be interested in helping work on it, please let me know. Ok I'm done. Thanks for sticking with me, and here's to a successful and productive Cucumber Linux 2.0 development cycle. - Scott |
|
From: Scott C. <sc...@cu...> - 2018-04-04 21:01:05
|
After six months of development, version 1.1 of Cucumber Linux has been released. This is a minor update, so only the few packages that needed to be updated for continued upstream support have need updated: PHP (updated to 7.2), Perl (updated to 5.26) and Bind client (updated to 9.11). Additionally, this release adds a few new daemons: VSFPTD 3.0.3, OpenSMTPD 6.0.3, Dovecot 2.2 and Bind server 9.11. This version of Cucumber Linux will be fully supported until December 31, 2019 and will then receive at least three months of selective support, putting the end of life date at March 31, 2020. For more information see the supported versions page <http://z5t1.com/cucumber/supported_versions.php>. Originally, it was stated that Cucumber Linux 1.1 would be released at least three months before the end of full support for Cucumber Linux 1.0. To keep this promise, the end of full support date for Cucumber Linux 1.0 has been pushed back from the original date of May 31, 2018 to September 30, 2018, and the end of life date has been pushed back from September 30, 2018 to November 30, 2018. This should allow plenty of time for users of Cucumber Linux 1.0 to upgrade to Cucumber Linux 1.1. We've also created a handy upgrade guide at https://cucumberlinux.com/upgrade_guide/cucumber_linux_1.1.html. Go grab the Cucumber Linux 1.1 installation ISOs at the download page <https://z5t1.com/cucumber/download.php>. The full list of changes can be found in the CHANGELOG <http://mirror.cucumberlinux.com/cucumber/cucumber-1.1/CHANGELOG>. Happy Hacking! |
|
From: Scott C. <sc...@cu...> - 2018-03-21 00:33:35
|
The first release candidate for Cucumber Linux 1.1 has arrived. Being a release candidate, this version has the potential to become the official 1.1 release if no critical bugs are found in it. If you find any last minute bugs, make sure to get the reports in quickly. Starting with this release, we will no longer be providing MD5 checksums of the installation ISOs. We are doing this to encourage people to switch to using the more secure SHA256 or PGP signatures to verify the integrity of the images, since it is well known that MD5 is broken <https://www.mscs.dal.ca/%7Eselinger/md5collision/>. As always, you can get the installable ISOs at the download page <https://z5t1.com/cucumber/download.php> and the full list of changes can be found in the CHANGELOG <http://mirror.cucumberlinux.com/cucumber/cucumber-1.1/CHANGELOG>. Happy Hacking! |
|
From: Scott C. <z5...@z5...> - 2017-12-04 02:15:42
|
The third and final beta for Cucumber Linux 1.1 has been released. This beta introduces an upgrade feature which allows you to upgrade a Cucumber Linux 1.0 system to 1.1. We have also published a 1.0 to 1.1 upgrade guide, which is available at http://www.cucumberlinux.com/upgrade_guide/cucumber_linux_1.1.html. As always, you can get the installable ISOs at the download page <http://www.cucumberlinux.com/download.php> and the full list of changes can be found in the CHANGELOG <http://mirror.cucumberlinux.com/cucumber/cucumber-1.1/CHANGELOG> Happy Hacking! |
|
From: Scott C. <z5...@z5...> - 2017-11-23 18:25:40
|
The second beta for Cucumber Linux 1.1 is here, and sooner than expected. Originally, it was planned that this second beta would be released at the beginning of December; however, a critical bug was discovered in the first beta: when a user tried to update his Cucumber Linux 1.1 Beta system using Pickle, Pickle would instead attempt to downgrade the system to Cucumber Linux 1.0. For this reason, we are encouraging all users of the first beta to either completely reinstall using this second beta or follow steps 2 and 3 (but NOT step 1) of the "Upgrading to the Cucumber Linux 1.1 Alpha" instructions on this blog post <https://sourceforge.net/p/cucumber-linux/blog/2017/10/work-begins-on-cucumber-linux-11/>. You can go get the installable ISOs at the download page <http://z5t1.com/cucumber/download.php>, and of course the full list of changes can be found in the CHANGELOG <http://mirror.cucumberlinux.com/cucumber/cucumber-1.1/CHANGELOG>. There will also be a third beta released at the beginning of December (when the second beta was originally going to be released). This will encompass what was originally going to be in second beta as outlined here <https://z5t1.com/cucumber/wiki/devdocs:1_1_roadmap>. Happy Thanksgiving! |
|
From: Scott C. <z5...@z5...> - 2017-11-19 23:31:49
|
The first beta for Cucumber Linux 1.1 is here! As we move into beta, we will begin rigorously testing the new and updated packages in preparation for the stable 1.1 release. At this time, we are envisioning having another beta release at the end of November, followed by the first release candidate in mid to late December. You can go get the installable ISOs at the new and improved download page <http://www.cucumberlinux.com/download.php>. As always, the full list of changes can be found in the CHANGELOG <http://mirror.cucumberlinux.com/cucumber/cucumber-1.1/CHANGELOG>. Happy Hacking! |
|
From: Z5T1 <z5...@z5...> - 2017-11-14 16:30:45
|
Hello all, This is a friendly reminder that the Cucumber Linux 1.1 feature freeze will be taking place tomorrow, so if you have any new content for the cucumber-1.1 tree (http://mirror.cucumberlinux.com/cucumber/cucumber-1.1/) make sure to submit it today as no new submissions will be accepted for cucumber-1.1 after the feature freeze. Also, this means that Cucumber Linux 1.1 Beta 1 will be coming out sometime this week. Once that happens we'll start doing serious debugging (like testing the DNS and mail servers, PHP 7.2 and Perl 5.26). Fun! - Scott |
|
From: Scott C. <z5...@z5...> - 2017-11-06 16:36:40
|
Hello All,
I know it's been a while but I'd like to officially welcome you all to
the Cucumber Linux Developers' mailing list! I just have a *couple of
mailing list pointers* I want to go over before we get started:
1. Remember that anything posted to this list will be publicly
viewable. If you need to discuss something with someone in private,
email him directly.
2. When you reply to a mailing list, make sure to send your reply to
the list email address
(cuc...@li...), not the sender.
If you reply to just the sender, that will send a private reply to
only him and the rest of the people on the list won't see it. If you
are using Thunderbird as your mail client, you can click the 'Reply
List' button to send a reply to the whole list.
So now that that's overwith, I'd like to lay out a *roadmap for the next
couple of months* of Cucumber Linux development. Here are some key
events that will be happening in the near future with approximate dates.
Note that we don't like force any releases or milestones to happen
before we're ready, so these dates are just approximate and may be
subject to some change:
* /_Present_/
o Cucumber Linux 1.1 is in the Alpha stage.
o Cucumber Linux 2.0 is a vague thought somewhere that we won't
worry about too much right now.
* /_November 15_/
o Cucumber 1.1 moves to the Beta stage and receives a feature
freeze, meaning that no new packages will be accepted into the
repository for the Cucumber 1.1 release after this date.
o Serious debugging begins on Cucumber Linux 1.1.
o Cucumber Linux 1.1 Beta 1 released.
* /_November 30_/
o PHP 7.2 will be officially released (currently we are using the
7.2 Release Candidate). This will enable us to upgrade to PHP
7.2 stable on Cucumber 1.1. This will be the last package we
have to wait for a stable release for Cucumber 1.1. After this,
all the packages which needed upgrading for Cucumber 1.1 will
have been upgraded, putting us much closer to a stable release
(which leads itself nicely to the next bullet):
o Cucumber Linux 1.1 Beta 2 released.
* /_December 16_/
o Cucumber Linux 1.1 Release Candidate 1 released. This version
will have the potential to become the official Cucumber Linux
1.1 release if no critical bugs are found in it.
* /_December 22_/
o Cucumber Linux 1.1 Released (if no bugs are found in RC 1,
otherwise this will be RC 2 released)
* /_Sometime After we've Recovered from the 1.1 Release_/
o Begin working on Cucumber Linux 2.0 (we won't worry about that
until after the 1.1 release though).
Also, I realize that many of our developers (myself included) are
students, and Mid-December is usually when *final exams* are. I want any
developers who are also students to be able to focus on their finals,
which is why I tried to place the release candidate dates after most
finals are complete. That being said though, if things get too hectic
with final exams on and around those dates, we can push the 1.1 Release
Candidate cycle release back to either after Christmas or into January 2018.
Sorry for this long email but I'm almost done. I just want to give the
new developers *a couple of links to useful project webpages*:
1. Our development roadmap can be found at
https://z5t1.com/cucumber/wiki/devdocs:start. This is also where we
keep track of who has been assigned what tasks and the progress that
has been made on those tasks. Please email me your desired Wiki
username so I can create an account for you.
2. Information about security vulnerabilities can be found on our
security tracker at
http://security.cucumberlinux.com/security/table.php and on our
security mailing list
(cuc...@li...). If you have not
already joined this mailing list, I strongly suggest you do so by
going to
https://sourceforge.net/projects/cucumber-linux/lists/cucumber-linux-security.
3. The official website for Cucumber Linux is
http://www.cucumberlinux.com/ <%27>.
4. The official SourceForge page for Cucumber Linux is
https://sourceforge.net/projects/cucumber-linux/.
5. The official forum for Cucumber Linux can be found at
https://www.linuxquestions.org/questions/cucumber-linux-124/.
One quick final note: in case you haven't noticed, I *make the topic for
each paragraph bold* in my emails. :)
Happy Hacking,
- Scott
|
|
From: Z5T1 <z5...@z5...> - 2017-10-24 17:15:33
|
3 |
|
From: Z5T1 <z5...@z5...> - 2017-10-24 17:13:25
|
#2! |
|
From: Z5T1 <z5...@z5...> - 2017-10-24 17:09:00
|
printf("Hello World!\n");
|
{kind=link}
{kind=link}