One of the main property of a cluster in Citespace is a silhouette, which is defined as the homogeneity of a cluster. As far as I understand, the higher the silhouette score, the more consistent the cluster members are. But in what terms this 'consistency' is measured? I would much appreciate the clarification.
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:
Thanks Chaomei . But so what does that similarity REALLY mean in, for instance, a co-citation network? Or maybe easier yet - a co-term network? Explained in understandable terms that preferably do not include cosine distance :)...
And this is a more general comment too. I think more and more people in various disciplines would be willing to start using this broader epistemic exploration of the field they work in using tools like CiteSpace. I also suspect that, like myself, they' be willing to trust bibliometric experts on the math. But at least a better understanding of the underlying intuition behind things like this would, I expect, help the uptake of these tools.
Last edit: Stephan De Spiegeleire 2021-01-19
If you would like to refer to this comment somewhere else in this project, copy and paste the following link:

One of the main property of a cluster in Citespace is a silhouette, which is defined as the homogeneity of a cluster. As far as I understand, the higher the silhouette score, the more consistent the cluster members are. But in what terms this 'consistency' is measured? I would much appreciate the clarification.
The consistency is essentially measured as how members in the same cluster are more similar to members outside the cluster.
Thanks Chaomei . But so what does that similarity REALLY mean in, for instance, a co-citation network? Or maybe easier yet - a co-term network? Explained in understandable terms that preferably do not include cosine distance :)...
And this is a more general comment too. I think more and more people in various disciplines would be willing to start using this broader epistemic exploration of the field they work in using tools like CiteSpace. I also suspect that, like myself, they' be willing to trust bibliometric experts on the math. But at least a better understanding of the underlying intuition behind things like this would, I expect, help the uptake of these tools.
Last edit: Stephan De Spiegeleire 2021-01-19
I am adding a glossary to explain concepts such as this without using too much of jargon.
https://citespace.podia.com/glossary-cocitations
尊敬的陈教授:
您好!在使用CiteSpace的聚类功能时,我遇到如下问题,因经过大量查阅您的论文和答疑帖还是未能解决,所以发此询问,希望能得到您的回复,十分感谢!
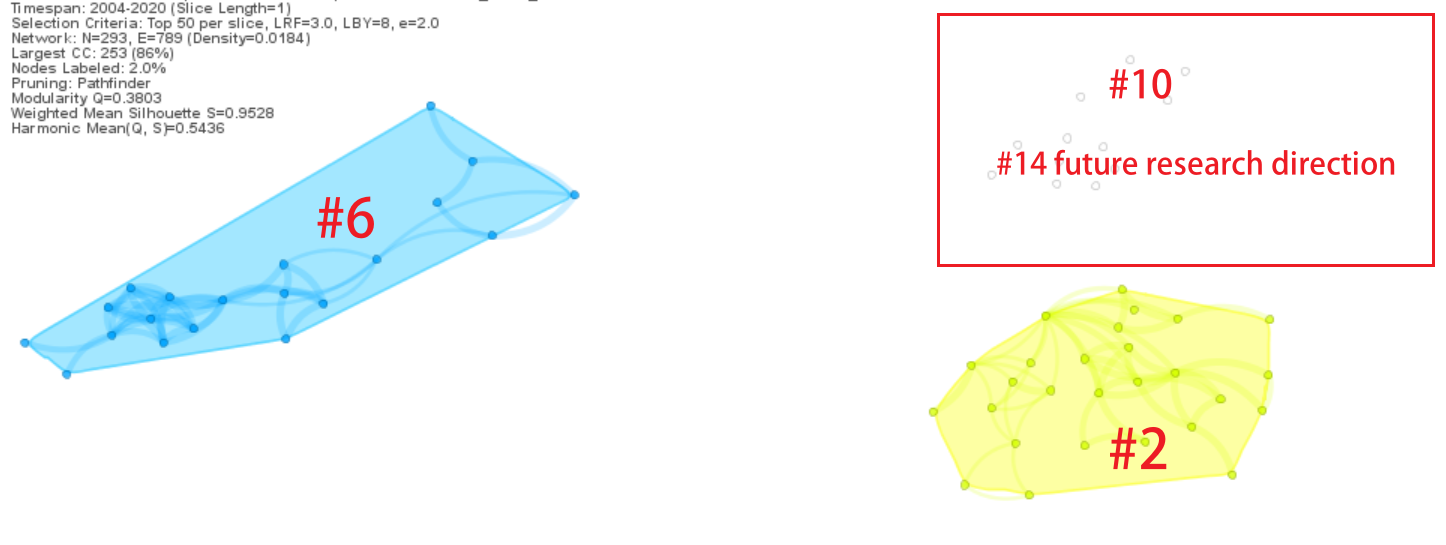
聚类完成的网络图色块填充后(如图1),有两个聚类没有内部连接线、没有轮廓也没有填充颜色(#10和#14),但是Silhouette分别为0.968和0.994,请问这样的聚类可以保留吗?
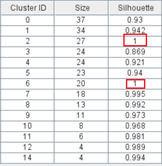
得到的聚类结果,有两个类Silhouette=1(如图2,对应聚类图见图1),我看您和李杰老师的讲解都是要接近1最好,没有具体说等于1的情况,且我看的很多论文得到的值也都没有等于1。请问这样的聚类结果是否可靠呢?Silhouette等于1的聚类结果可以保留吗?
关于使用Keyword和Term,进行研究热点、研究趋势、知识结构分析时,我看了您的很多答疑,还是有些疑惑:因为Keyword和Term的结果会有些类似,所以进行热点分析时,是比较这两种的结果,再做出最优选择吗?还是可以同时进行分析?如果需要对这两个的结果进行选择,那哪一个更可靠呢,是要结合实际情况分析吗?
最后,再次感谢您抽出的宝贵时间!盼能尽快收到您的回复!
祝您身体健康,万事顺遂!
用Cluster Explorer查看相应的聚类里的Citing Articles是否只有少数几个或只有一个。如果是的话,应避免过多解读。