CiteSpace Blog
A widely used tool for visual exploration of scientific literature.
Brought to you by:
citespace
One of the questions asked frequently by new users of CiteSpace is how come the citatation frequency of a paper shown in CiteSpace is often lower than what you may see on Google Scholar or the Web of Science. So the next questions may go like this: what do we miss and what can we do about it?
The discrepancies are due to the scope and the depth of sampling. The most common way to use CiteSpace begins with a dataset that you have collected from the Web of Science, Dimensions, the Lens, or some other repositories of scholarly publications. These repositories typically contain hundreds of millions of scholarly publications. They are like an ocean of papers. The dataset that you are typically interested in and intended to analyze, on the other hand, is a subset of the entire database of any one of these vast ocean of papers. As long as there are papers in the ocean staying outside the scope of your study, then you are dealing with a subset of the pool, i.e. the ocean, of the publications. Your scope is typically much narrower than the scope invisibly drawn by these individual oceans and, of course, even smaller than a combination of all the available oceans of papers.
Now let's see what difference this may lead when you count citations of a paper within your dataset and in one of the original ocean where the dataset was drawn in the first place, for the sake of argument, assuming that is Dimensions. The argument remains the same if you want to compare citation counts with other giants such as the Web of Science and Google Scholar. Assume Dimensions currently has 200,000,000 bibliographic records and you collected a dataset of interest consisting of 10,000 of them. The counting of a paper's citations based on the 10,000-item dataset gives you a local citation score, whereas the counting based on the 200 million base of Dimensions gives you a global citation score. Yes, even the 'global citatoin score' would be different if you choose different oceans as your base. The citation frequency of a paper you see in CiteSpace is a local citation score, which is typically lower and possibly much lower than a global citation score.
The difference between the local and global citation scores is made by articles outside your dataset but out there in the base ocean of yours.
So is it a good idea to expand your original dataset so that you can include these 'outsiders'? Not necessarily - it depends. The devil here is the concept of relevance. The relevance of these 'outsiders' tends to drop quickly, which is largly why they were not captured by your initial dataset in the first place. Including 'outsiders' with diminimshing relevance may reduce the intensity of the focus of your analysis and your study may drift away from your original interest, although one can never rule out the potential benenfits of drifting away from our original course of plan - the potential value of a surprise may outweigh the planned course (We can sidetrack here to another interesting topic - I should probably write about it in another piece).
If, after you carefully considered the implications, you decide it will be indeed a good idea to pull these 'outsiders' into your initial dataset, you may use the Cascading Citation Expansion strategy to incrementally expand your dataset in such a way that you can still exercise some selection criteria to maintain the relevance to a reasonable level as opposed to open up your gate for the entire ocean to flood in.
In summary, the answer to the local vs global citation score discrepancies depends on how you want to delineat the scope of the topic of interest and how you want to construct your dataset in such a way so that it is the most representative and the most efficient. In other words, the optimal dataset would be the smallest in size with the highest relevance.... read more
All versions below 5.6.R3 will become invalid after July 31, 2020. I recommend you to upgrade to 5.7.R1. Versions 5.6.R3 and 5.6.R5 will remain valid until their corresponding expiration dates, which are also shown on the welcome page when you launch CiteSpace.
Update:
The following list shows the most active versions of CiteSpace in use over the last 3 months (May-July 2020). The versions in bold (i.e. 5.6.R3 or higher) will remain valid, whereas other versions will be phased out from today (August 1, 2020).... read more
It should usually take about 13 seconds to complete the download of the latest version of CiteSpace.
If it takes much longer than this, you may try different mirror sites and see which one is better for you.
Click on the "Problem Downloading?" button on the download page and select a mirorr site from the list.
I'd be interested in how long it takes at different mirror sites.
Here are some work-in-progress visualizations for CiteSpace.
CiteSpace is one of the 9 candidates for “Community Choice” Project of the Month Vote – February 2020.
See more details here:
https://sourceforge.net/blog/community-choice-project-month-vote-february-2020/
Action:
If you like CiteSpace to be listed at the top of the SourceForge homepage, vote for CiteSpace by January 15, 2020 at the following link:
https://sourceforge.net/p/potm/discussion/vote/thread/16990a2c04/
From 5.5.R3, the following heuristics will be used to determine whether two records are duplicates and, if so, which one should be retained.
Two records are considered to be the same if they match as follows:
The first author's lastname
The first 10 letters of the title
The first 10 letters of the source
The year of publication
The DOI, if any
The first page number
Heuristics of retention
If one of them is from the Web of Science, keep that version and remove the one from other source.
If none of the records is from the Web of Science, keep the one with more information, i.e. the longer one.... read more
First of all, it only takes 444 words for this blog.
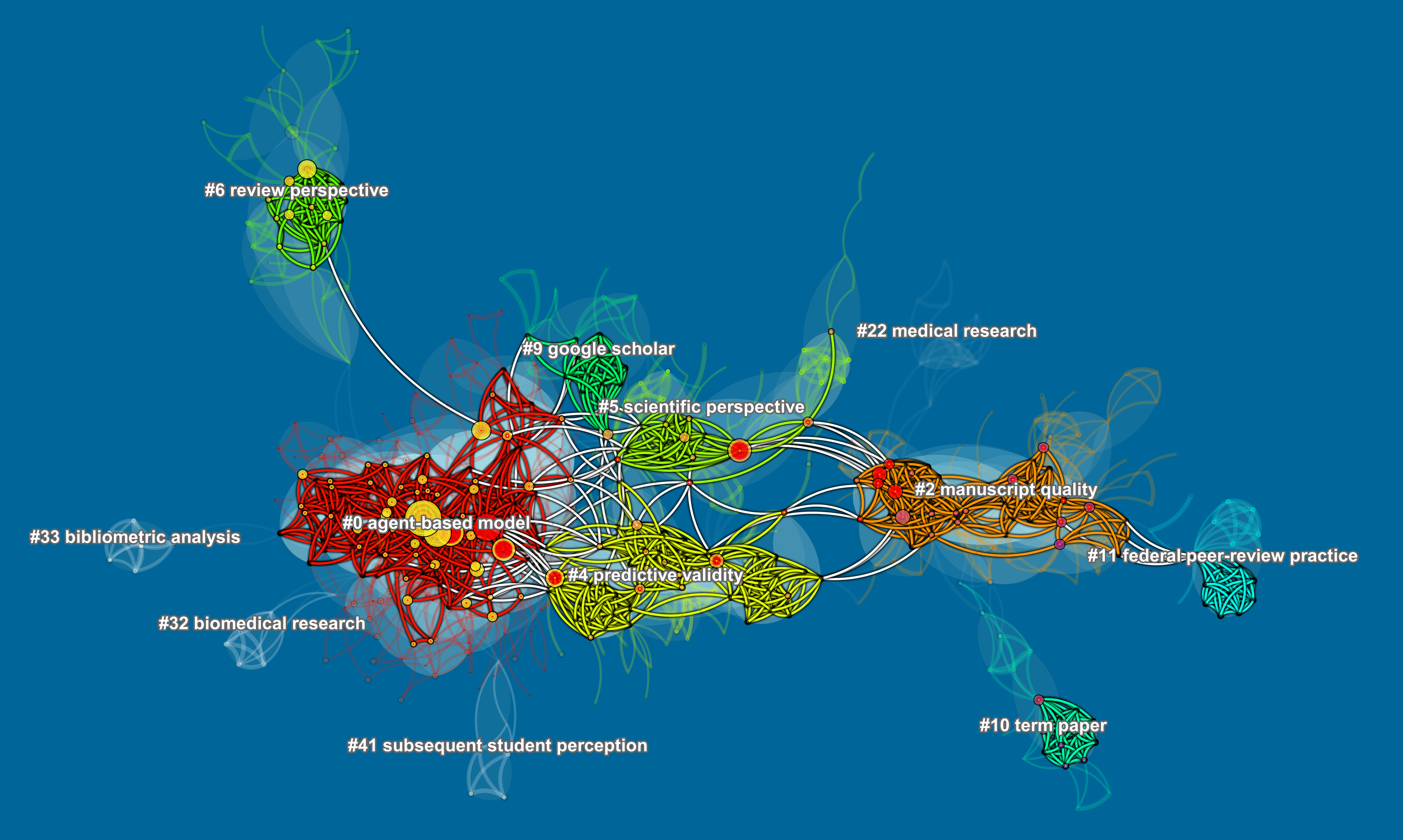
Note that the example below is more of a teaser than a full-swing scientometric analysis. The dataset contains top 3,000 most cited articles on peer reviews on the Web of Science (1980-2019) as of 8/11/2019. The point here is to illustrate the potential of the method. Consider collecting more data if possible.
The topic search query was very simple: "peer review" OR "peer reviews".
Export the data with the Plain Text option, i.e. the field tagged format.
Configure the settings in CiteSpace as follows:
Top N=50, we are building the network based on the citation behavior of top 50 most cited articles per year. If there are ties, all parties will be included.
Node Type: Cited References
LRF=3.0, LBY=5, e=1.0 (You can edit these in the Project>Edit Properties)
Network: 8,050 cited references with 27,359 co-citation links. ... read more
CiteSpace version required: 5.5.R2 or higher.
CiteSpace 5.6.R3 updates:
Cited references are retrieved through the Lens API when you convert the downloaded data in CSV format.
This is a brief update on how to handle CSV files exported from lens in CiteSpace 5.5.R2.
The current option is to use the Data>Import/Export>CSV to configure your own conversion and select Keyword as the node type. What you can get now is a network of co-cited references in their Lens' IDs, you can look it up in your browser by right-clicking on the node and selecting the "LENS" option in the pop-up menu. For example, to look up a node with lens ID 026 395 112 558 483, the corresponding webpage will be shown in your browser window: https://www.lens.org/lens/scholar/article/026-395-112-558-483/main. In the example below, the most cited reference turns out to be an article by Eugene Garfield.... read more
Here is a new demo video of creating visualizations with #Scopus data in #CiteSpace.
https://youtu.be/Pr5CeiIq8A0
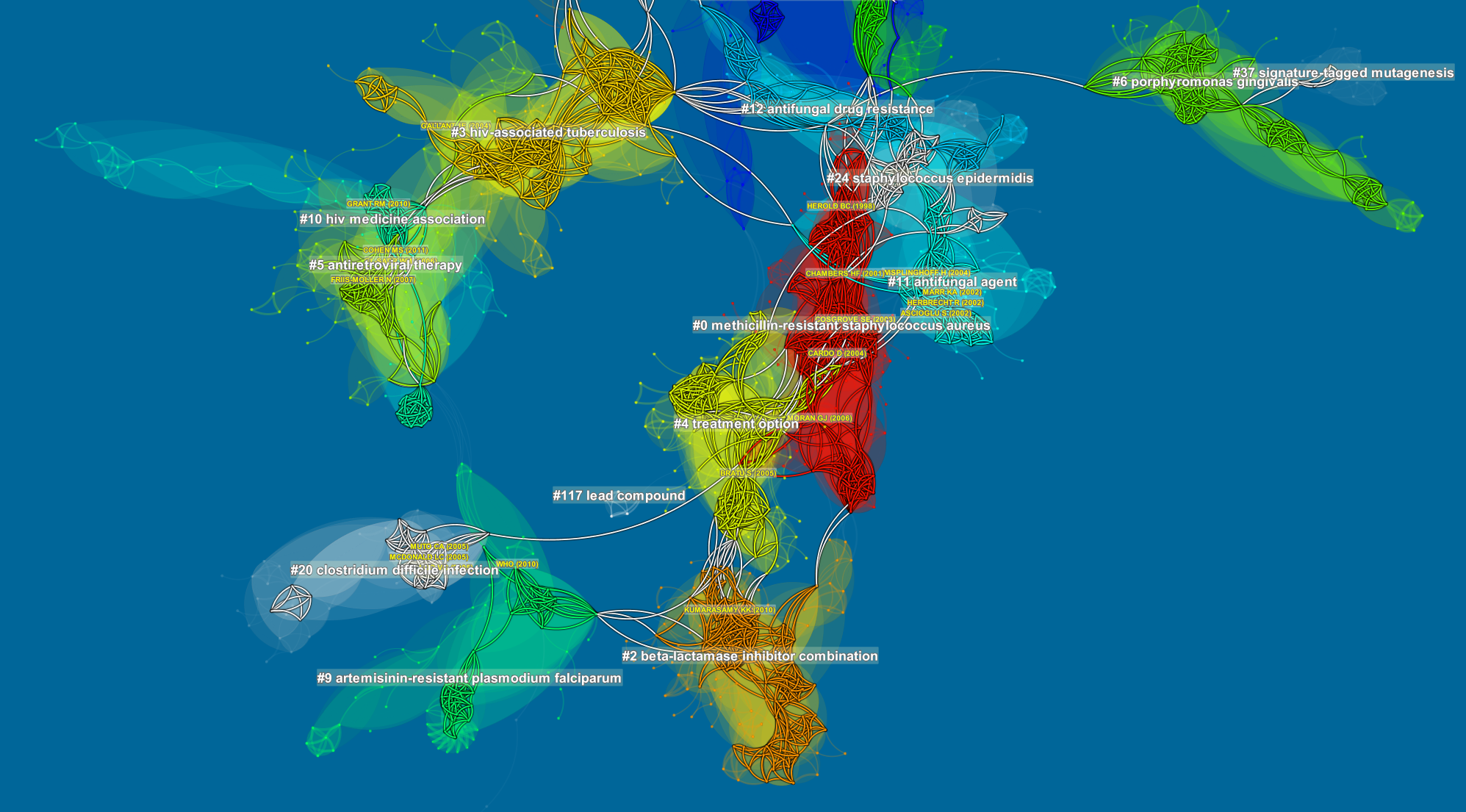
CiteSpace 5.4.R4 has revised the way to process data downloaded from Scopus in the RIS format.
One interesting change is the option of using article titles instead of the journal titles for cited references. As a result, in a network of co-cited references we will be able to see the article titles directly, which should be more informative than see the corresponding journal titles only. The length of the title is limited to 50 letters. Titles longer than that will have a trailing ... to indicate they have been chopped off. If you prefer the previous style, which is consistent with the Web of Science format, you can select that option accordingly at the time of coversion.
The References section of Scopus data is still highly volatile to put it politely. References without author information at all will be discarded not becaues they are not important, rather because it is a warning sign of something very unpredictable.
Some references of articles originally appeared in Chinese contain references in English and then in Chinese. When possible, the English version will be retained. If references are in Chinese entirely, then they will be processed.
The figure below shows a network of cited references derived from 1,126 records from a search on Scopus (title, keyword, abstract). Some discrepencies are obvious - you may use the alias trick to unify them. ... read more
The procedure consists of the following steps:
1. Load your dataset (in the WoS format) to your MySQL database on localhost: Data>Import/Export>Built-in Database: Create a New Project: Browse, Import
According to a recently published survey of the use of knowledge mapping software in China in the Journal of Information Resources Management (信息资源管理学报) - all in Chinese - CiteSpace is among the most used knowledge mapping software in China.

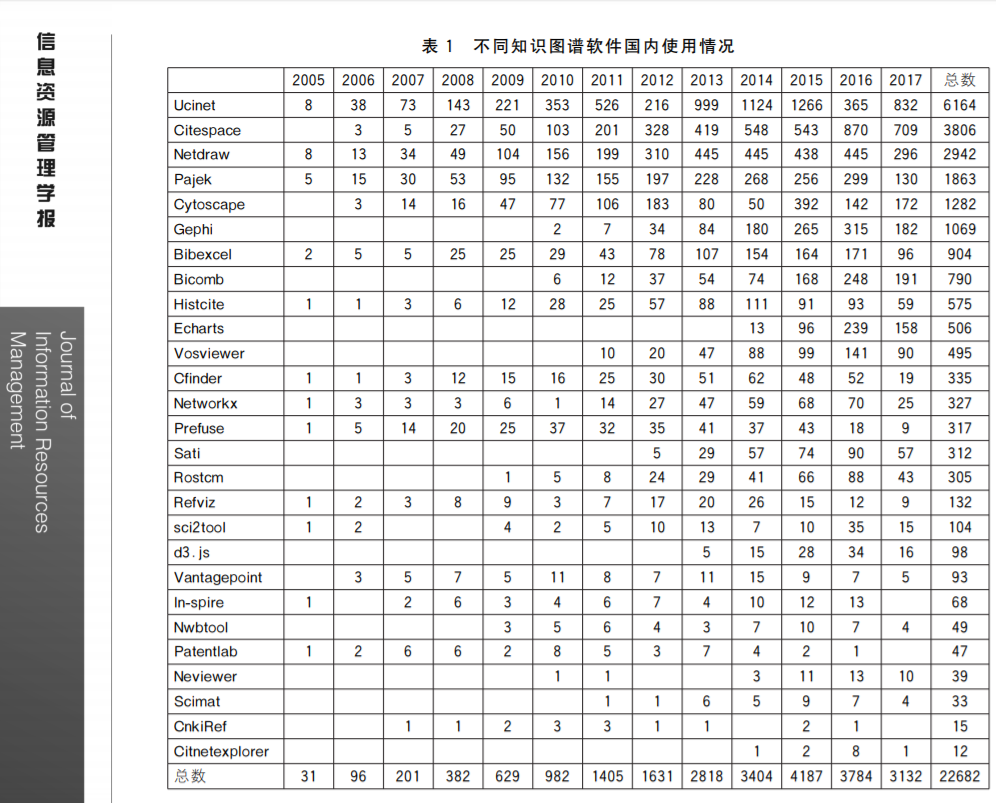
I'd be interested in collecting similar surveys together. If you are aware of additional surveys of CiteSpace and other comparable software, please feel free to add your comments below.
Windows 10 users may get a virus alert of "TrojanDownloader:Java/Vigorf.A" from Windows Defender for the exe file and/or the 7z file.
This blog recommends a scan with virusTotal.
Here is the VirusTotal page. You may upload the file or give it an URL. I uploaded the exe file.
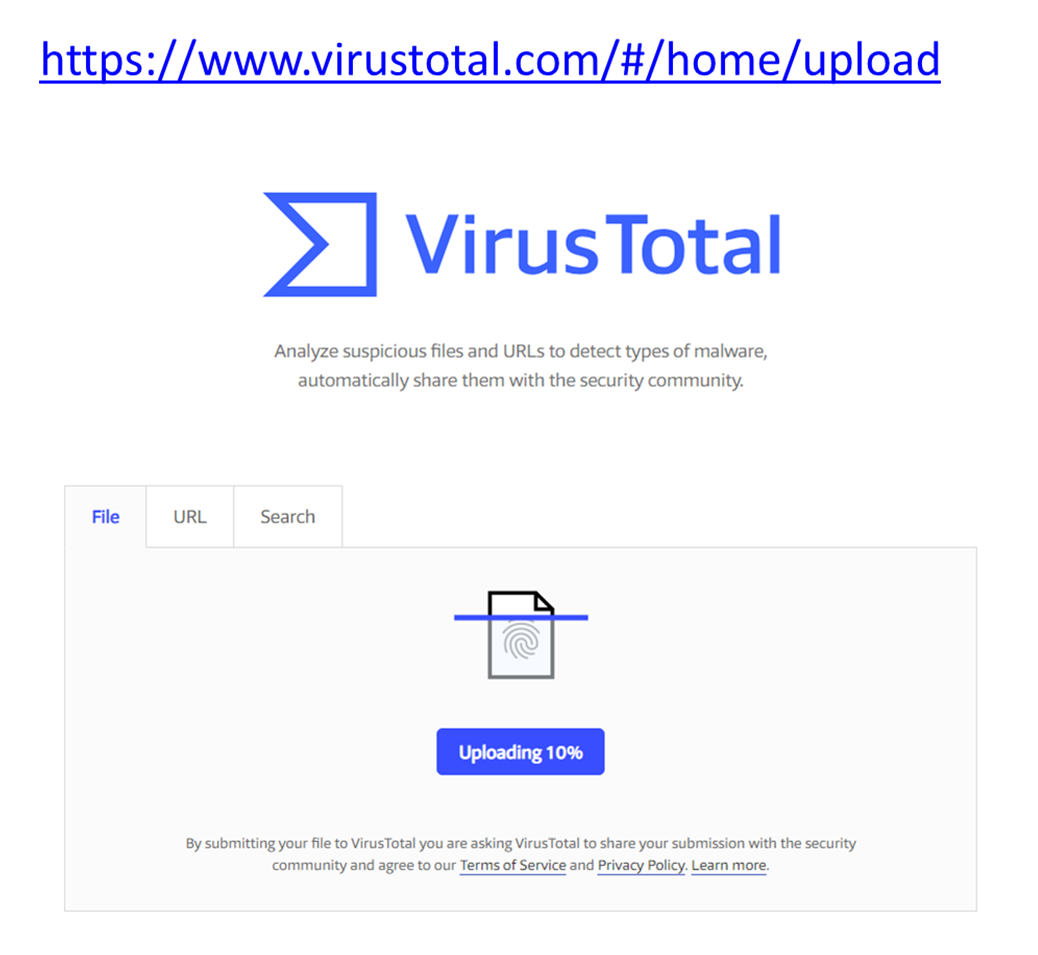 ... read more
... read more
5.3.R10 modifies the way to handle projects in CiteSpace using the plain text file citespace.projects.txt in the .citespace folder under your user folder.
If you are using a previous version of CiteSpace, use Projects > Export Projects to save your existing projects. 5.3.R10 can understand the file format saved from the Export Projects.
The menu is slightly changed in 5.3.R10 as follows:
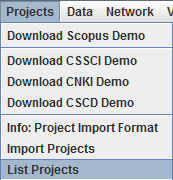
Projects > List Projects actually does two things: 1) save the existing projects and 2) display the content of the saved file. You can use any text editor to modify a project. You can even directly create a new project in the text file as long as you follow the template. If the project or data directories are not found, they will be created for you.
Here is a screenshot of the display:
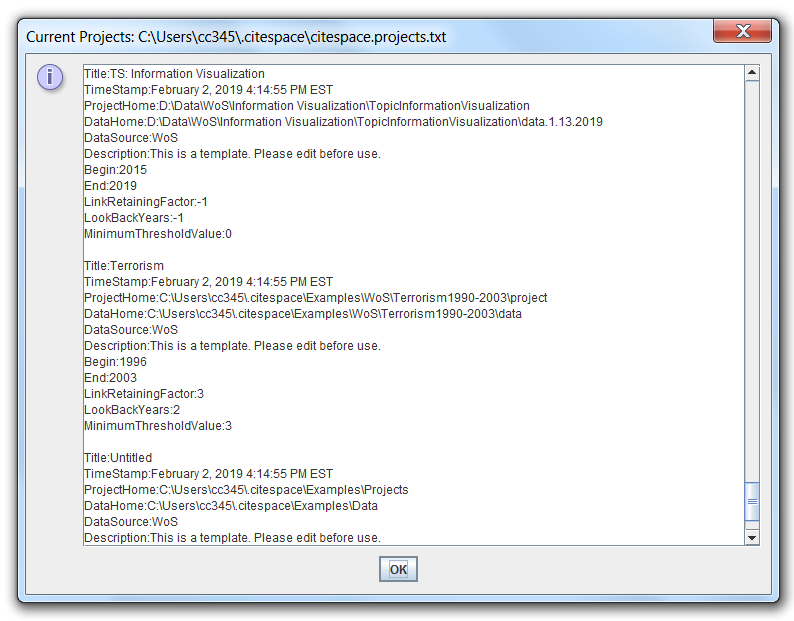
Three commonly used project properties are highlighted in the Edit Properties to get your attention.
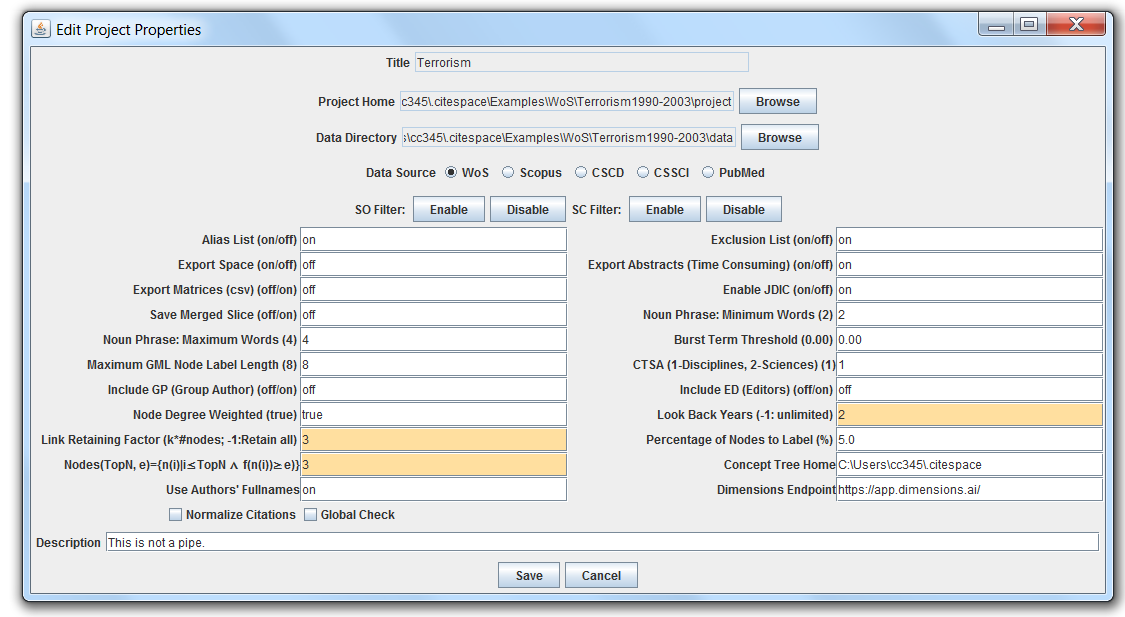
You can reload the saved projects with Projects > Import Projects to open the citespace.projects.txt file. Since by default the file is saved under the .citespace, it would be a good idea to keep a copy elsewhere in case you accidently delete the .citespace.
The last edition of the e-book was published on June 9, 2018. It was based on CiteSpace 5.3.R1. It has 31,541 words on 223 pages.
The new edition is updated based on 5.3.R9. It is available now (1/21/2019).
233 pages
252 figures
32957 words
https://leanpub.com/howtousecitespace
CiteSpace allows users to analyze bibliographic records from Dimensions in two ways: 1) Advanced DSL (an integrated search interface in CiteSpace) and 2) Convert search results exported from a search on Dimensions.
1) Use the Integrated Search Interface in CiteSpace
CiteSpace: Data > Import/Export > Dimensions > Advanced
The first option is flexible and suitable if you are familiar with the DSL query language. It is also the way to use Cascading Citation Expansion functions.... read more
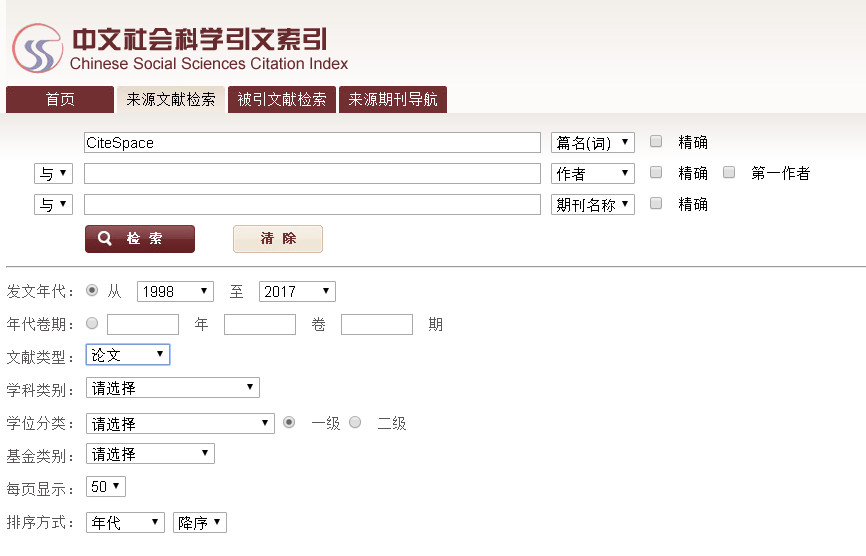
CSSCI - Chinese Social Sciences Citation Index - includes cited references in a mixture of entries in both Chinese and English.
Here are some examples of what you can do with CSSCI data using CiteSpace.
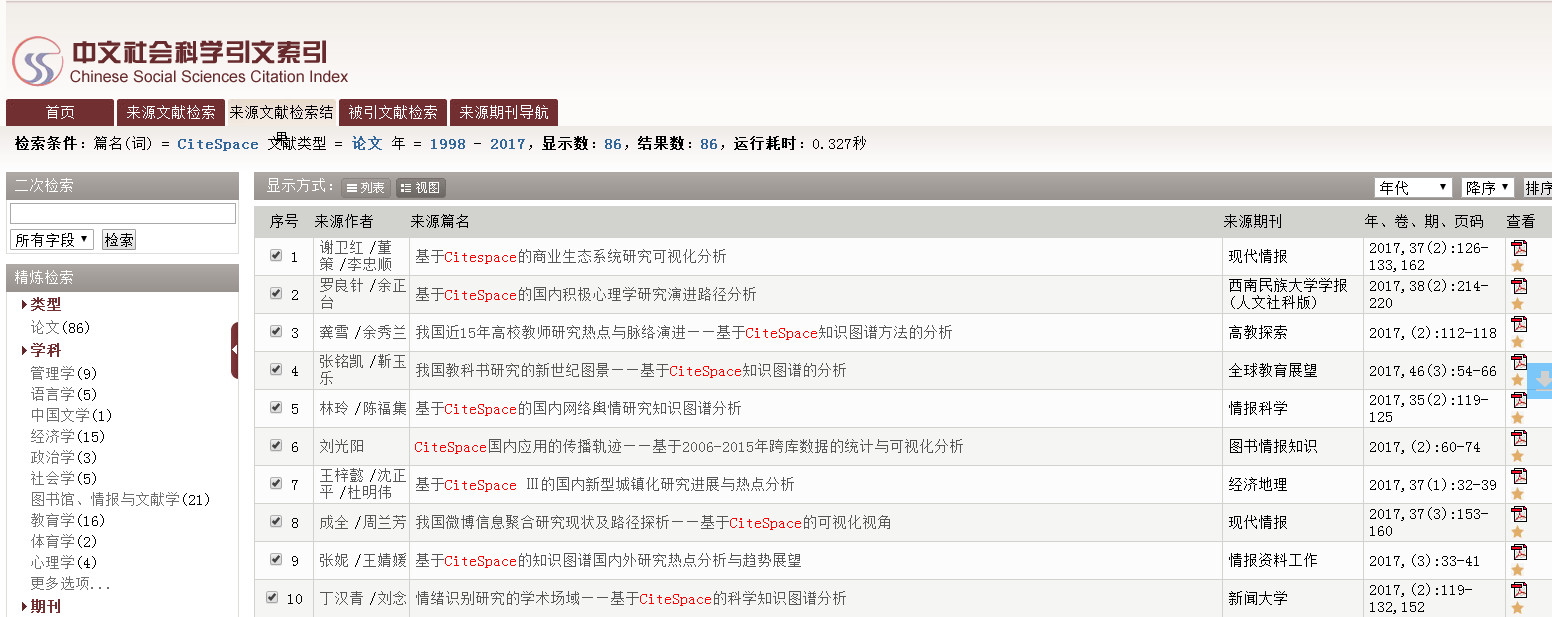
Here are the search query and various filters used for the search:
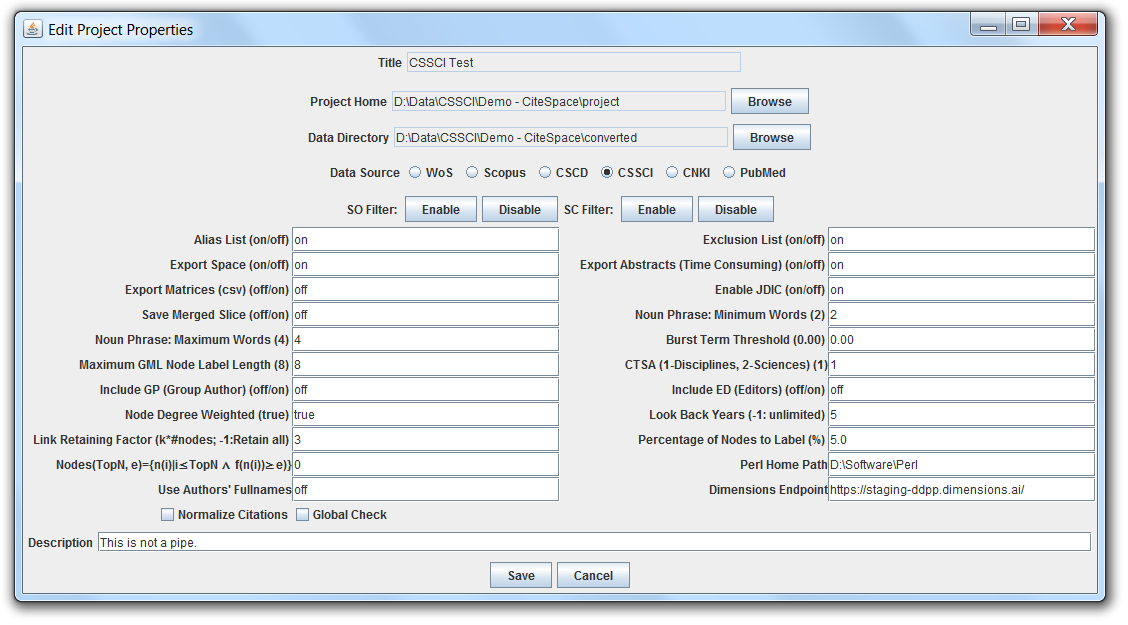
This is how I configured the project in CiteSpace. You may tailor the properties to suit your own datasets.
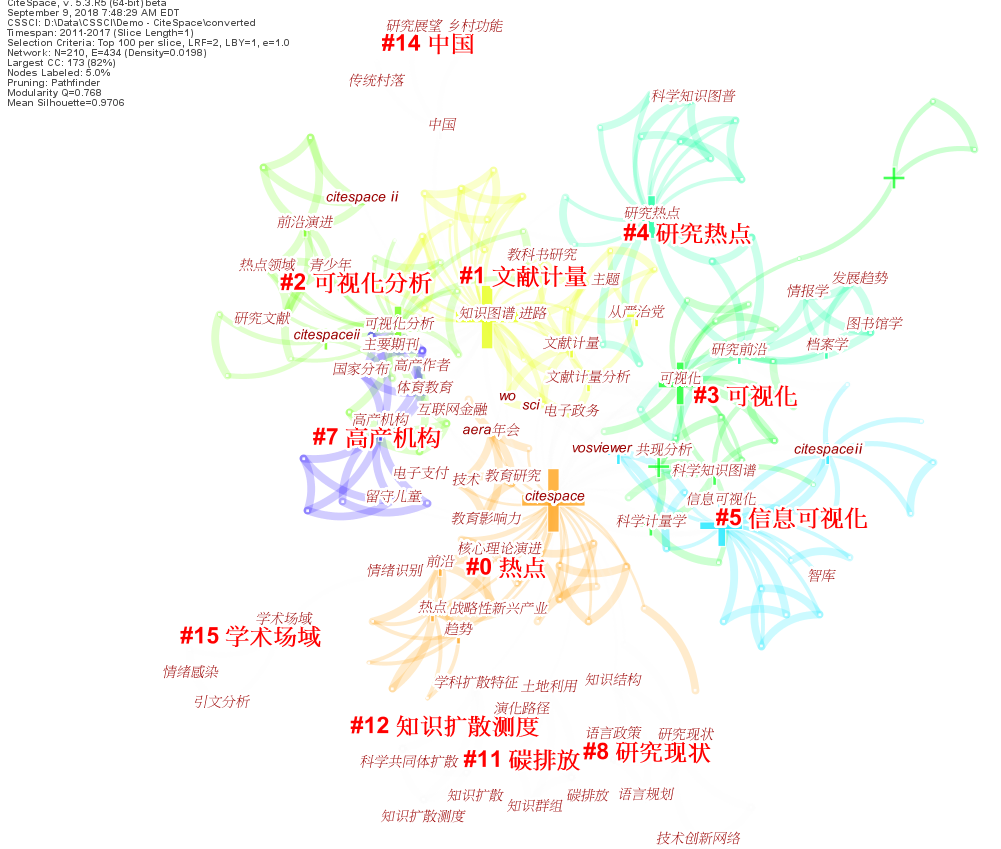
Keywords
First, a network of co-occuring keywords. Most of them are in Chinese.
Next, you can step forward and backward in time through the link walkthrough feature to reveal connections made in a particular year. The example here shows the snapshot of the link walkthrough in year 2015.
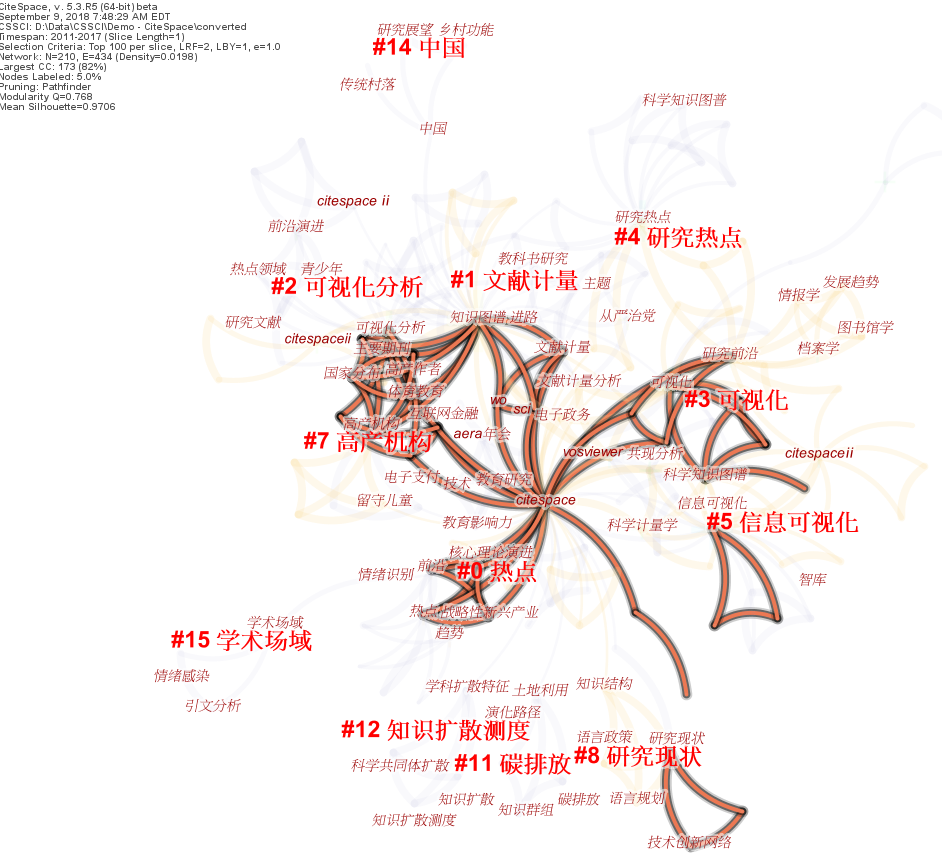
Burst Detection
Here are 9 keywords that are found to have sharpe increases (aka burst) during the period of 2011-2017.

Local Search
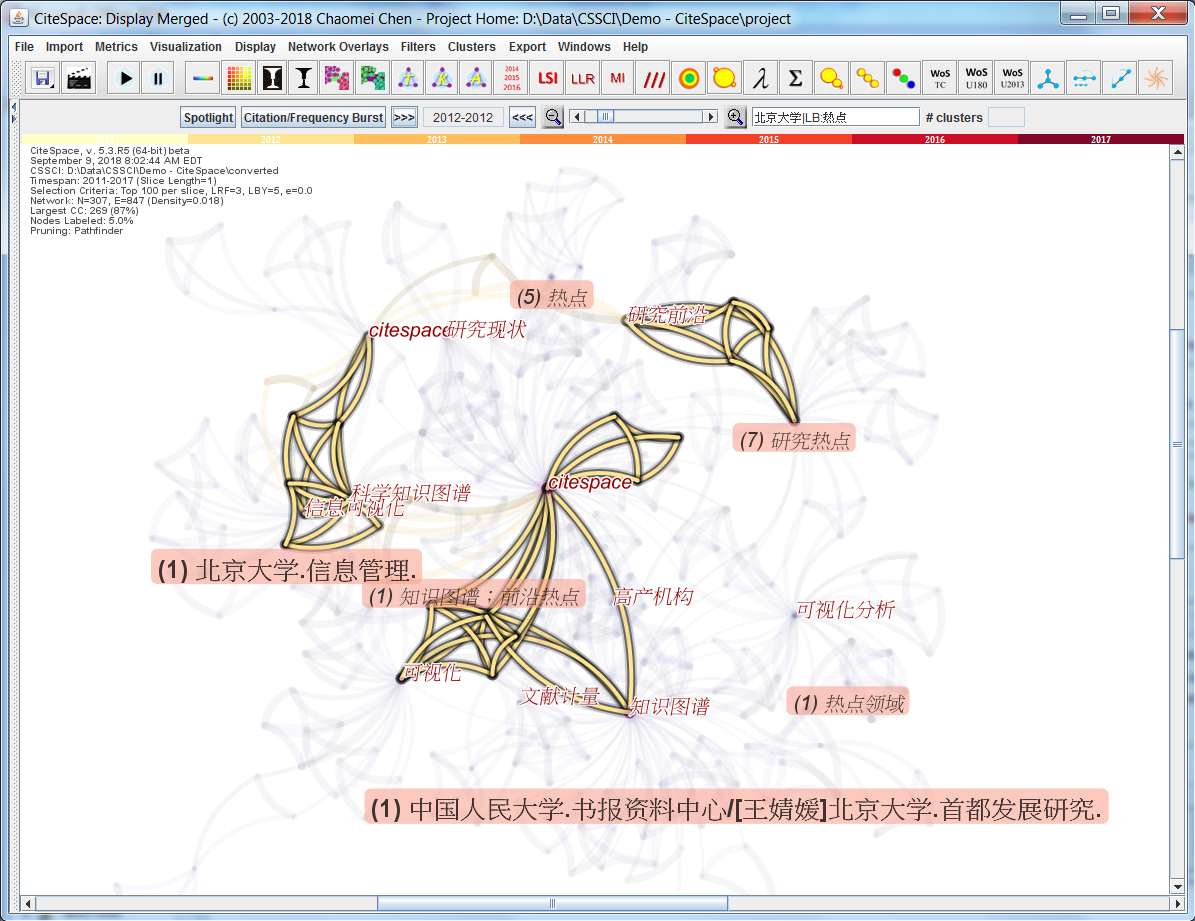
This is a function that has been there for a long time but I haven't seen it used in the literature. The example below illustrates its use. Surprisingly, it works well even with words in Chinese, although it was not on my mind at the time of design.
The local search query is: 北京大学|LB:热点
To those of you who may not read Chinese everyday, 北京大学=Beijing University=Peking University and 热点=hot spot or hot topics.
LB is English for Label. More information on the syntax is in the tool tip. As a result, you can see several nodes are highlighted because their labels contain the word 热点:
热点,研究热点,热点领域,知识图谱;前沿热点
Two institutions match the 北京大学part of the search:
北京大学,信息管理and ...... 北京大学,首都发展研究
This is also in the middle of a link walkthrough (year=2012).
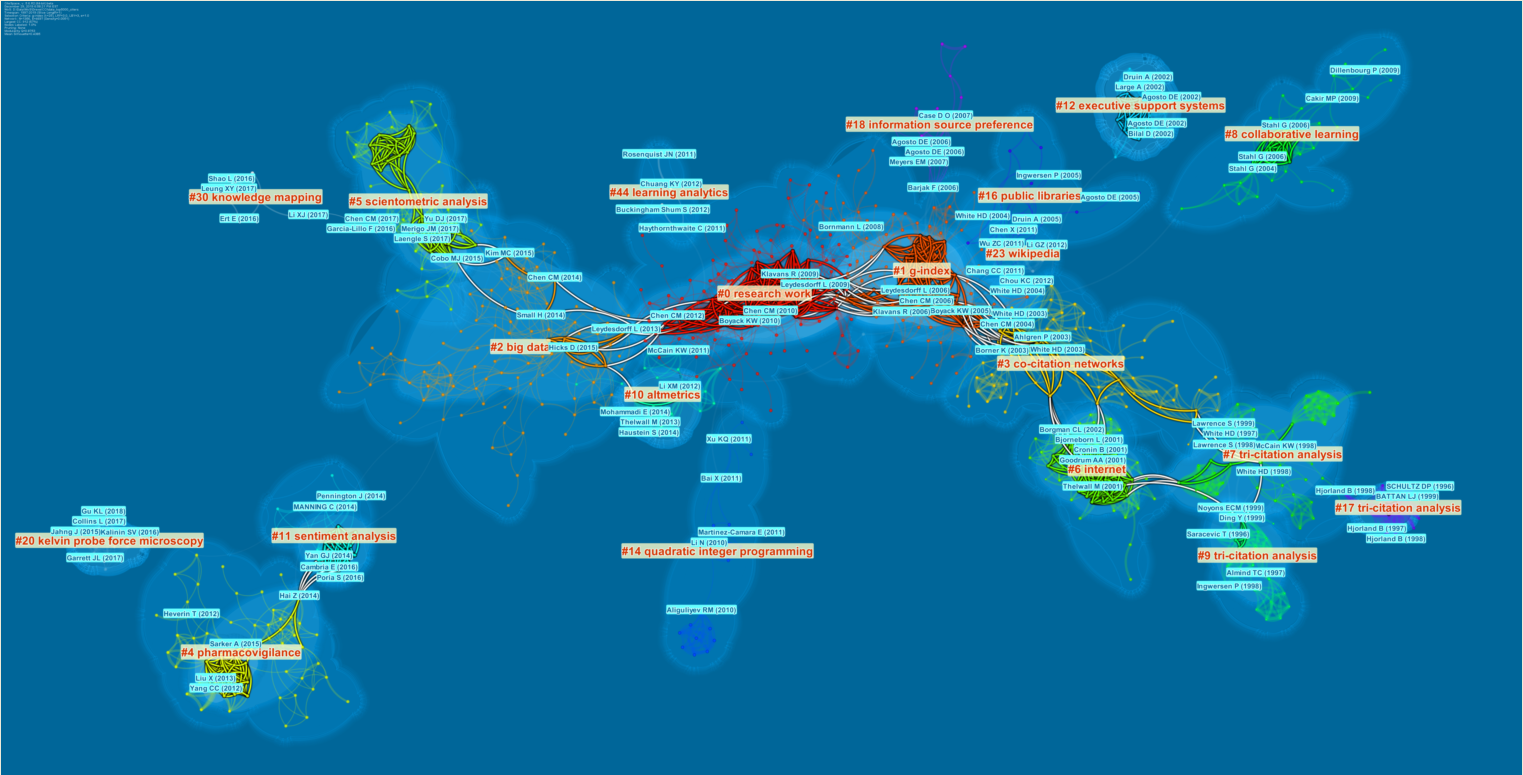
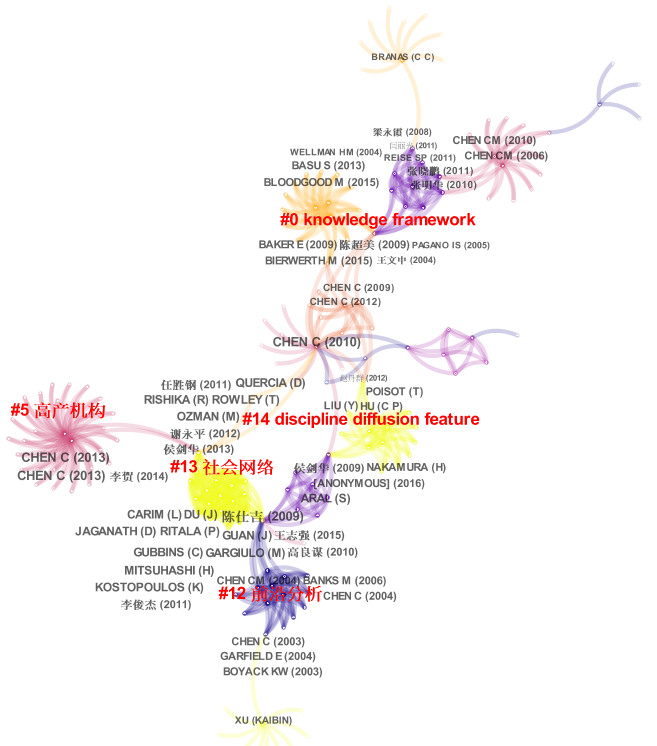
Document Co-Citation Analysis (DCA)
The usual layout of a DCA network, including labels of cited references, which as you can see include both entries in Chinese and English.
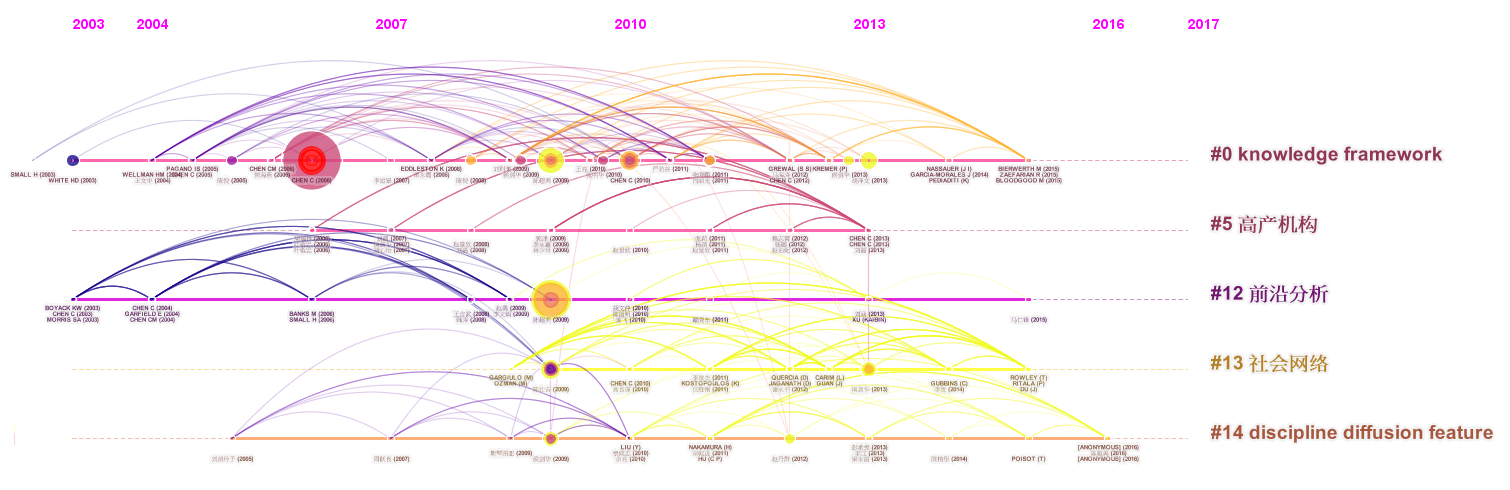
Here is a timeline view. It is easy to inspect temporal patterns of how the five clusters of co-cited references evolved over time. Each year the top-3 most cited references are shown along each of the timelines. They are too small to see in the static images. You can zoom in in the interactive mode to get a sense of what made of each timeline. For example, the timeline on the top is the largest cluster (cluster #0). The big node with a red core in 2006 is my 2006 JASIST paper on CiteSpace II, which has been cited over 2100 times on Google Scholar. Its red core indicates there was a citation burst in earlier years of the period.
 ... read more
... read more
Dissertations and Theses in ProQuest can be downloaded in the RIS format, containing common bibliographic information such as the author, title, keywords, the institution, and so on about a disseration or a thesis. It is straightforward to search on ProQuest and save your search results to one or more files in the RIS format.
Save these RIS files in a directory on your computer, then use CiteSpace to convert these files so that you can use CiteSpace to analyze your data.
Note that ProQuest data does not contain references cited by the dissertation. Although it is not feasible to perform citation-based analyses with ProQuest data, you can still explore the data in some useful ways such as networks of co-occurring keywords.
Convert the ProQuest downloads using the Data>Import/Export>ProQuest menu in CiteSpace. Specify the directory in which you have saved the ProQuest results and a different directory for converted data files. Then you can use CiteSpace as usual by configuring the directory with your converted files as the data directory.
The following network of co-occurring keywords is generated with link strengths stronger than PMI=0.80. The rest of the configuration parameters can be seen in the signature block on the upper left of the image.

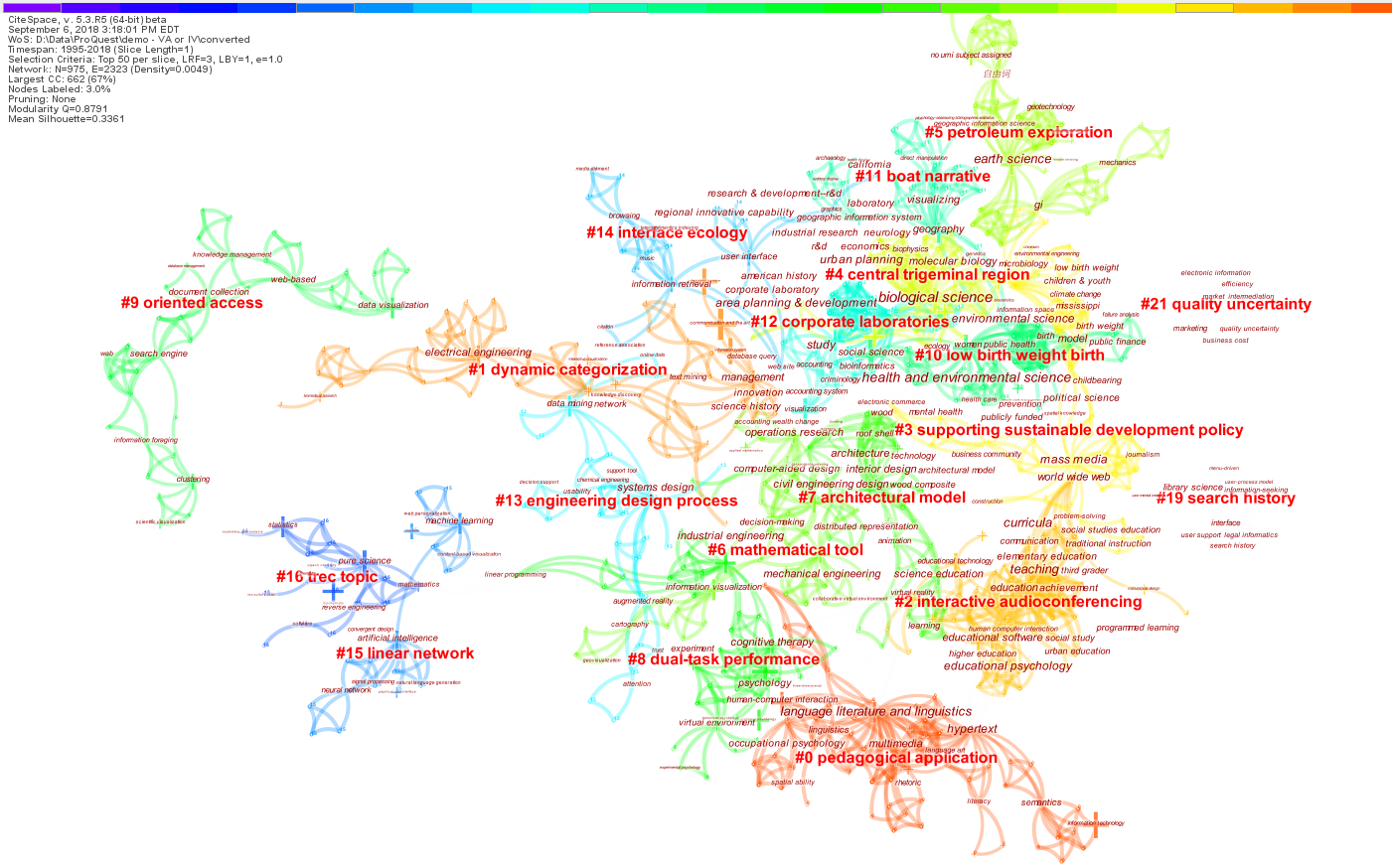
Here is a saved visualization that you can open it in CiteSpace: Visualization>Open Saved Visualization.
Download the 7z File
To use CiteSpace on Mac, you need to download the 7z file to your Mac. You can then use the Unarchiver tool to unpack the 7z file. You will see a new folder named similar to 5.3.R10.2.2.2019.
Launch CiteSpace
Although you may double click on the CiteSpaceV.jar file directly to launch CiteSpace, I recommend you use the following approach. It allows you to optimize the use of your computer's RAM. CiteSpace will run faster with more RAM and it will be able to handle a bigger dataset too.
To launch CiteSpace with a customized amount of RAM, create a simply shell script. You can name the shell script in anyway you like, for example, run.sh or launch.sh.
Open a Terminal on Mac and use the nano text editor to create the run.sh script:
nano run.sh
If you have never used nano, me neither. Very simply to use. Use Control + o to save the content of the file. You will be prompted with "File Name to Write: run.sh" at the bottom of the nano editor. Simply hit the Enter key. When you are done with nano, use Control + x to quit.
Now enter the following three lines as the content of the run.sh script:
#!/bin/bash
echo Launching CiteSpace …
java -Dfile.encoding=UTF-8 -Duser.country=US -Duser.language=en -Xms1g -Xmx4g -Xss5m -jar CiteSpaceV.jar
This shell script will ask the amount of RAM between 1-4GB for the Java virtual machine. With newer Java, it is possible to make it more dynamic, but for now this is the way to do it.
One last thing to check before running the script is to make sure it is executable. This is to avoid the errors your Mac may tell you "Permission Denied".
Use ls -la run.sh to check whether your run.sh is executable. If you see the following,
rwxr--r-- for your run.sh, you need to make the following change. Very simple:
chmod +x run.sh
It will become
rwxr-xr-x and you will be good to go.
In the Terminal, type ./run.sh to launch CiteSpace.
Refresh the .citespace directory on Mac
If you have installed an earlier version of CiteSpace, you might need to refresh the .citespace directory so that CiteSpace can have a clean start. For example, if CiteSpace cannot load projects you have created with earlier versions of CiteSpace, you may need to follow the refresh steps. The general idea is the same regardless on Windows or Mac.
I am borrowing my son's Mac so I will use his username stevenchen as an example. I will use a Terminal window to locate the .citespace directory and remove it along with any files and subdirectories in it. If you are not familiar with Mac, like me, you can use Launchpad and search for Terminal. Once you open up a Terminal window, you would land in the home directory associated with your username, e.g. /Users/stevenchen. You can verify this with the command pwd. Usually, .citespace would be hidden from your listing if you use ls only. Use the following command instead:
ls -la .citespace
If it turns out that you do not have a .citespace directory in your home directory, then you can skip the removal steps and start CiteSpace directly.
To remove the .citespace directory, use the following command. Don't worry, CiteSpace will automatically generate a new .citespace with the latest files.
rm -R .citespace
I will update it with some screenshots when I get a chance. In the meantime, feel free to leave messages below if you encounter any problems to launch CiteSpace.
