
It is notable when Microsoft and others talk about new approaches and standards. One example is how Differential Privacy and synthetic data is favored for data privacy and compliance. This article reviews how synthetic data is used, and the advantages driving the transition to Synthetic data for data privacy and compliance.
Modeled synthetic data delivers superior data privacy
Microsoft and others are turning to synthetic data for superior data privacy and usability. As modeled synthetic data can look and behave like the source data, reflecting source data distributions. The resulting data set is privacy protected and supports the accuracy needed in Machine Learning and AI initiatives. Simple data masking and anonymization is no longer considered a best practice.
Another driver for synthetic data is the emerging demand for Generative AI, and the need for high volumes of enterprise textual data for Retrieval Augmented Generation (RAG). Support tickets, word docs, and other textual data are scanned to identify Personally Identifiable Information (PII), which is either redacted or replaced with privacy protecting synthetic data. This process of producing a privacy protected data lake is foundational for enterprises pursuing Generative AI solutions. The data lake is ingested to create an authoritative set of business knowledge to support Retrieval Augmented Generation (RAG), which in turn augments Large Language Models for business specific AI solutions.
Synthetic data for Generative AI
Enterprises should be familiar with data privacy requirements such as GDPR and California Privacy Act, and protecting information in databases has been readily available for the past decade or more. The emerging challenge is how to protect textual data, which is now in demand for Generative AI?
Large Language Models (LLMs) are based on widely available and public text, and enterprises will add value with an authoritative knowledge base built on private enterprise documents (support tickets, word docs, etc.). These documents capture knowledge in context, and are incorporated into Generative AI by creation of Retrieval Augmented Generation (RAG).
A RAG based Generative AI solution incorporates textual data, including support tickets, catalogs of products, in house word docs, PDFs, and other sources. This data must be cleansed of Personally Identifiable Information (PII), as PII data cannot be leaked to a customer facing Generative AI application! Collections of documents are organized into file shares or object stores and scanned by an automated document reader, to detect PII information. Once identified the sensitive data is either redacted or replaced with synthetic data, creating a privacy protected document collection. The protected data is then divided into contextually understandable “chunks” and ingested into a vector database (vector databases are designed to catalog information into as many as 3,000 dimensions, to align with the dimensions of LLMs).
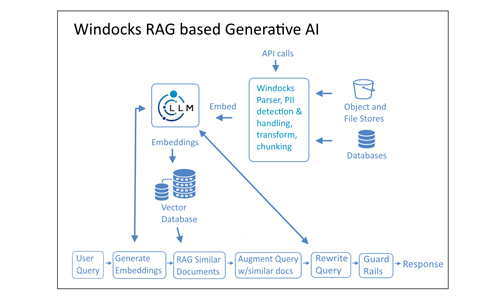
The vector database becomes the authoritative knowledge base, and is queried by the LLM in responding to customer prompts. This RAG based Generative AI is the most popular approach to enterprise AI.
RAG based Generative AI is the most common approach to enterprise Generative AI today. Generative AI is evolving rapidly, and one area that is gaining attention is the need for near real-time information which is typically stored in databases. Various methods of incorporating relational data include structuring the Generative AI application to source data through SQL queries, or to define specific queries in the vector database to source explicitly linked data for delivery through the Generative AI application.
3 key advantages of synthetic data
Modeled synthetic data looks and feels like source data
Masked and anonymized data involves the replacement of primary identifiers, such as “John Smith” replaced with “Toby Jones.” The resulting data is anonymized, but does not reflect the inter-column correlations such as age to income, geographic distribution, and other nuances of the source data.
Modeled synthetic data reflects source data distributions, populating sensitive data with values that look like the source. The result is higher quality and utility in the protected data, that can be used for analytics, or used to augment Machine Learning data sets with high data accuracy.
Synthetic data delivers assured data privacy and compliance
Masked and anonymous databases are subject to linkage attacks, where anonymized data is joined with another data set to re-engineer identities. There are many examples of linkage attacks, including healthcare data, and even a public contest involving Netflix movie recommendations.
To avoid these problems, Microsoft, Amazon, and others are turning to synthetically populated data with differential privacy for mathematically assured data privacy. Differential privacy is a mathematical solution that includes sufficient noise in query results to ensure no individual can be identified from the synthetically populated data set.
Synthetic data accuracy is needed for Machine Learning, and RAG based Generative AI
Data compliance with GDPR, CCPA, and other legal standards isn’t limited to tabular and relational data, but includes personally identifiable data in support tickets, text files, documents, PDFs, and logs. Modern synthetic data solutions read and detect sensitive textual data in S3 buckets, Azure Blobs, and file stores, and either redact or replace sensitive data with synthetic data.
A synthetic data privacy strategy applied to documents and databases is a best practice for privacy and compliance, but also supports the business imperative of privacy protected data for development of Large Language Models (LLMs) and Generative AI.
Exploring synthetic data
Synthetic data tooling varies according to scale and type of data. Python based solutions focus on tables of 50,000 rows or less, where others scale to support tables as well as complete databases. Windocks supports tables as well as complete relational databases, and documents and other textual data in privacy-protected data lakes ready for ingestion into LLM and vector databases. Check out our free downloadable Synthetic data generator at www.windocks.com.
Related Categories